mirror of
https://github.com/LearnOpenGL-CN/LearnOpenGL-CN.git
synced 2025-12-02 05:55:57 +08:00
conver 05/03
This commit is contained in:
88
05 Advanced Lighting/01 Advanced Lighting.md
Normal file
88
05 Advanced Lighting/01 Advanced Lighting.md
Normal file
@@ -0,0 +1,88 @@
|
||||
本文作者JoeyDeVries,由Django翻译自[http://learnopengl.com](http://learnopengl.com)
|
||||
|
||||
## 高级光照
|
||||
|
||||
在光照教程中,我们简单的介绍了Phong光照模型,它给我们的场景带来的基本的现实感。Phong模型看起来还不错,但本章我们把重点放在一些细微差别上。
|
||||
|
||||
|
||||
|
||||
### Blinn-Phong
|
||||
|
||||
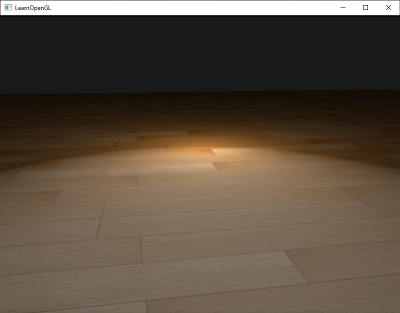
Phong光照很棒,而且性能较高,但是它的specular反射在特定的条件下会坏掉,特别是当shininess属性低的时候,specular区域就会非常大。下面的图片展示了,当我们使用specular的shininess指数为1.0时,一个带纹理地板的效果:
|
||||
|
||||
|
||||
|
||||
你可以看到,specular区域边缘迅速减弱。出现这个问题的原因是在视线向量和反射向量的角度不允许大于90度。如果大于90度的话,点乘的结果就会是负数,specular指数就会变成0。你可能会想,这不是问题,因为我们不会得到任何大于90度的角度,对吧?
|
||||
|
||||
错了,这只适用于diffuse部分,当法线和光源之间的角度大于90度时意味着光源在被照亮表面的下方,这样光的diffuse成分就会是0.0。然而,对于specular光照,我们不会测量光源和法线之间的角度,而是测量视线和反射方向向量之间的。看看下面的两幅图:
|
||||
|
||||

|
||||
|
||||
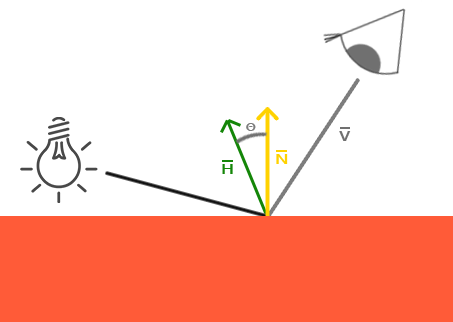
现在看来问题就很明显了。左侧图片显示Phong反射就是θ,小于90度。我们可以看到右侧图片视线和反射之间的角θ大于90度,这样specular成分将会被消除。通常这也不是问题,因为视线方向距离反射方向很远,但如果我们使用一个数值较低的specular成分的话,specular半径就会足够大,以至于能够显现出这个specular成份了。在例子中,我们在角度大于90度时消除了这个成份(如第一个图片所示)。
|
||||
|
||||
1977年James F. Blinn引入了Blinn-Phong着色,它扩展了我们目前所使用的Phong着色。Blinn-Phong模型和大程度上和Phong是相似的,不过它稍微改进了specular模型,使之能够克服我们所讨论到的问题。作为代替,它基于一个我们现在所说的一个叫做半程向量(halfway vector)的反射向量,这是个单位向量,它在实现方向和光线的中间。半程向量表面法线向量越接近,specular成份就越大。
|
||||
|
||||
|
||||
|
||||
当视线方向恰好与反射向量对称时,半程向量就与法线向量重合。这样观察者距离原来的反射方向越近,specular高光就会越强。
|
||||
|
||||
这里,你可以看到无论观察者往哪里看,半程向量和表面法线之间的夹角永远都不会超过90度(当然除了光源远远低于表面的情况)。这样会产生和Phong反射稍稍不同的后果,但这时看起来会更加可信,特别是specular指数比较低的时候。Blinn-Phong着色模型也正是早期OpenGL固定函数输送管道(fixed function pipeline)所使用的着色模型。
|
||||
|
||||
得到半程向量很容易,我们将光的方向向量和视线向量相加,然后将结果标准化(normalize);
|
||||
|
||||

|
||||
|
||||
翻译成GLSL代码如下:
|
||||
|
||||
```c++
|
||||
vec3 lightDir = normalize(lightPos - FragPos);
|
||||
vec3 viewDir = normalize(viewPos - FragPos);
|
||||
vec3 halfwayDir = normalize(lightDir + viewDir);
|
||||
```
|
||||
|
||||
实际的specular的计算,就成为计算表面法线和半程向量的点乘,并对其结果进行约束,然后获取它们之间角度的余弦,再添加上specular的shininess指数:
|
||||
|
||||
```c++
|
||||
float spec = pow(max(dot(normal, halfwayDir), 0.0), shininess);
|
||||
vec3 specular = lightColor * spec;
|
||||
```
|
||||
|
||||
除了我们刚刚讨论的,Blinn-Phong没有更多的内容了。Blinn-Phong和Phong的specular反射唯一不同之处在于,现在我们要测量法线和半程向量之间的角度,半程向量是视线方向和反射向量之间的夹角。
|
||||
|
||||
!!! Important
|
||||
|
||||
Blinn-Phong着色的一个附加好处是,它比Phong着色性能更高,因为我们不必计算更加昂贵的反射向量了。
|
||||
|
||||
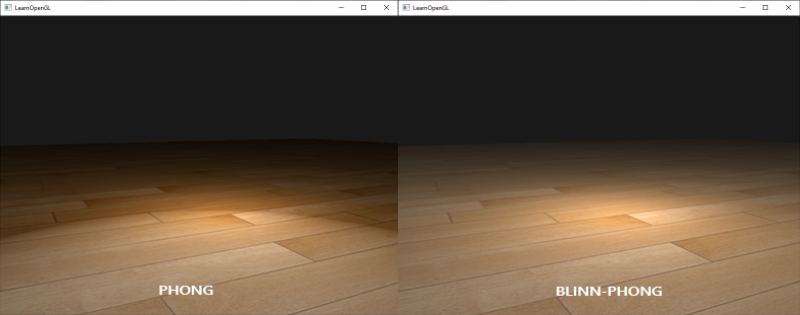
为计算specular高光我们引入了半程向量,我们再也不会遇到Phong着色的specular的骤然过度问题了。下图展示了两种不同方式下specular指数为0.5时specular区域不同效果:
|
||||
|
||||
|
||||
|
||||
Phong和Blinn-Phong着色之间另一个细微差别是,半程向量和表面法线之间的角度经常会比视线和反射向量之间的夹角更小。结果就是,为了获得和Phong着色相似的效果,必须把specular的shininess指数设置的大一点。通常的经验是将其设置为Phong着色的shininess指数的2至4倍。
|
||||
|
||||
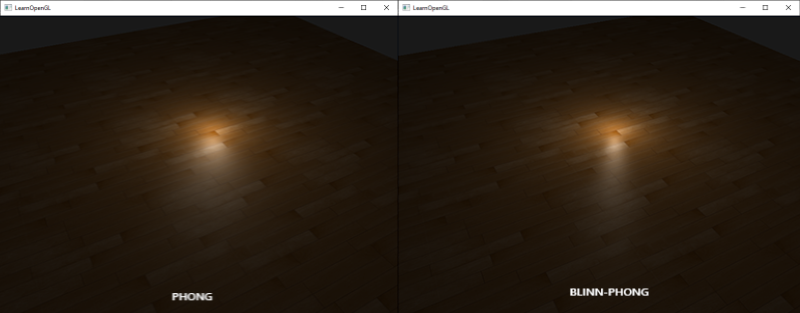
下图是Phong指数为8.0和Blinn-Phong指数为32的时候,两种specular反射模型的对比:
|
||||
|
||||
|
||||
|
||||
你可以看到Blinn-Phong的specular指数要比Phong锐利一些。这通常需要使用一点小技巧才能获得之前你所看到的Phong着色的效果,但Blinn-Phong着色的效果比默认的Phong着色通常更加真实一些。
|
||||
|
||||
这里我们用到了一个简单像素着色器,它可以在普通Phong反射和Blinn-Phong反射之间进行切换:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
[...]
|
||||
float spec = 0.0;
|
||||
if(blinn)
|
||||
{
|
||||
vec3 halfwayDir = normalize(lightDir + viewDir);
|
||||
spec = pow(max(dot(normal, halfwayDir), 0.0), 16.0);
|
||||
}
|
||||
else
|
||||
{
|
||||
vec3 reflectDir = reflect(-lightDir, normal);
|
||||
spec = pow(max(dot(viewDir, reflectDir), 0.0), 8.0);
|
||||
}
|
||||
```
|
||||
|
||||
你可以在这里找到这个简单的[demo的源码](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/blinn_phong)以及[顶点](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/blinn_phong&type=vertex)和[片段](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/blinn_phong&type=fragment)着色器。按下b键,这个demo就会从Phong切换到Blinn-Phong光照,反之亦然。
|
||||
|
||||
161
05 Advanced Lighting/02 Gamma Correction.md
Normal file
161
05 Advanced Lighting/02 Gamma Correction.md
Normal file
@@ -0,0 +1,161 @@
|
||||
本文作者JoeyDeVries,由Django翻译自[http://learnopengl.com](http://learnopengl.com)
|
||||
|
||||
## Gamma校正(Gamma Correction)
|
||||
|
||||
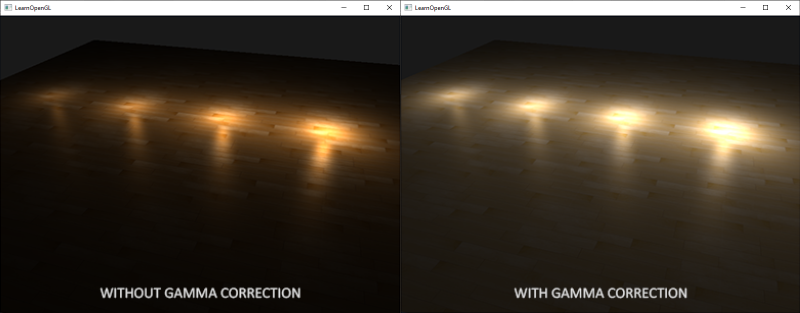
当我们计算出场景中所有像素的最终颜色以后,我们就必须把它们显示在监视器上。过去,大多数监视器是阴极射线管显示器(CRT)。这些监视器有一个物理特性就是两倍的输入电压产生的不是两倍的亮度。输入电压产生约为输入电压的2.2次幂的亮度,这叫做监视器Gamma(译注:Gamma也叫灰度系数,每种显示设备都有自己的Gamma值,都不相同,有一个公式:设备输出亮度 = 电压的Gamma次幂,任何设备Gamma基本上都不会等于1,等于1是一种理想的线性状态,这种理想状态是:如果电压和亮度都是在0到1的区间,那么多少电压就等于多少亮度。对于CRT,Gamma通常为2.2,因而,输出亮度 = 输入电压的2.2次幂,你可以从本节第二张图中看到Gamma2.2实际显示出来的总会比预期暗,相反Gamma0.45就会比理想预期亮,如果你讲Gamma0.45叠加到Gamma2.2的显示设备上,便会对偏暗的显示效果做到校正,这个简单的思路就是本节的核心)。
|
||||
|
||||
人类所感知的亮度恰好和CRT所显示出来相似的指数关系非常匹配。为了更好的理解所有含义,请看下面的图片:
|
||||
|
||||

|
||||
|
||||
第一行是人眼所感知到的正常的灰阶,亮度要增加一倍(比如从0.1到0.2)你才会感觉比原来变亮了一倍(译注:这里的意思是说比如一个东西的亮度0.3,让人感觉它比原来变亮一倍,那么现在这个亮度应该成为0.6,而不是0.4,也就是说人眼感知到的亮度的变化并非线性均匀分布的。问题的关键在于这样的一倍相当于一个亮度级,例如假设0.1、0.2、0.4、0.8是我们定义的四个亮度级别,在0.1和0.2之间人眼只能识别出0.15这个中间级,而虽然0.4到0.8之间的差距更大,这个区间人眼也只能识别出一个颜色)。然而,当我们谈论光的物理亮度,也就是光子的数量的多少的时候,底部的灰阶显示出的才是这时讨论的亮度。底部的灰阶显示出的是双倍的亮度所返回的物理亮度(译注:这里亮度是指光子数量和正相关的亮度,即物理亮度,前面讨论的是人的感知亮度;物理亮度和感知亮度的区别在于,物理亮度基于光子数量,感知亮度基于人的感觉,比如第二个灰阶里亮度0.1的光子数量是0.2的二分之一),但是由于这与我们的眼睛感知亮度不完全一致(对比较暗的颜色变化更敏感),所以它看起来很奇怪。
|
||||
|
||||
因为人眼看到颜色的亮度更倾向于顶部的灰阶,监视器使用的也是一种指数关系(电压的2.2次幂),所以物理亮度通过监视器能够被映射到顶部的非线性亮度;因此看起来效果不错(译注:CRT亮度是是电压的2.2次幂而人眼相当于2次幂,因此CRT这个缺陷正好能满足人的需要)。
|
||||
|
||||
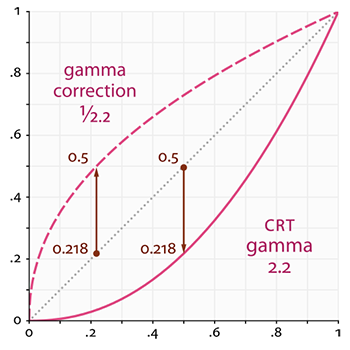
监视器的这个非线性映射的确可以让亮度在我们眼中看起来更好,但当渲染图像时,会产生一个问题:我们在应用中配置的亮度和颜色是基于监视器所看到的,这样所有的配置实际上是非线性的亮度/颜色配置。请看下图:
|
||||
|
||||
|
||||
|
||||
点线代表线性颜色/亮度值(译注:这表示的是理想状态,Gamma为1),实线代表监视器显示的颜色。如果我们把一个点线线性的颜色翻一倍,结果就是这个值的两倍。比如,光的颜色向量L=(0.5, 0.0, 0.0)代表的是暗红色。如果我们在线性空间中把它翻倍,就会变成(1.0, 0.0, 0.0),就像你在图中看到的那样。然而,由于我们定义的颜色仍然需要输出的监视器上,监视器上显示的实际颜色就会是(0.218, 0.0, 0.0)。在这儿问题就出现了:当我们将理想中直线上的那个暗红色翻一倍时,在监视器上实际上亮度翻了4.5倍以上!
|
||||
|
||||
直到现在,我们还一直假设我们所有的工作都是在线性空间中进行的(译注:Gamma为1),但最终还是要把所哟的颜色输出到监视器上,所以我们配置的所有颜色和光照变量从物理角度来看都是不正确的,在我们的监视器上很少能够正确地显示。出于这个原因,我们(以及艺术家)通常将光照值设置得比本来更亮一些(由于监视器会将其亮度显示的更暗一些),如果不是这样,在线性空间里计算出来的光照就会不正确。同时,还要记住,监视器所显示出来的图像和线性图像的最小亮度是相同的,它们最大的亮度也是相同的;只是中间亮度部分会被压暗。
|
||||
|
||||
因为所有中间亮度都是线性空间计算出来的(译注:计算的时候假设Gamma为1)监视器显以后,实际上都会不正确。当使用更高级的光照算法时,这个问题会变得越来越明显,你可以看看下图:
|
||||
|
||||

|
||||
|
||||
Gamma校正
|
||||
|
||||
Gamma校正的思路是在最终的颜色输出上应用监视器Gamma的倒数。回头看前面的Gamma曲线图,你会有一个短划线,它是监视器Gamma曲线的翻转曲线。我们在颜色显示到监视器的时候把每个颜色输出都加上这个翻转的Gamma曲线,这样应用了监视器Gamma以后最终的颜色将会变为线性的。我们所得到的中间色调就会更亮,所以虽然监视器使它们变暗,但是我们又将其平衡回来了。
|
||||
|
||||
我们来看另一个例子。还是那个暗红色(0.5, 0.0, 0.0)。在将颜色显示到监视器之前,我们先对颜色应用Gamma校正曲线。线性的颜色显示在监视器上相当于降低了2.2次幂的亮度,所以倒数就是1/2.2次幂。Gamma校正后的暗红色就会成为
|
||||
|
||||
```math
|
||||
{(0.5, 0.0, 0.0)}^{1/2.2} = {(0.5, 0.0, 0.0)}^{0.45}={(0.73, 0.0, 0.0)}
|
||||
```
|
||||
|
||||
校正后的颜色接着被发送给监视器,最终显示出来的颜色是
|
||||
|
||||
```math
|
||||
(0.73, 0.0, 0.0)^{2.2} = (0.5, 0.0, 0.0)
|
||||
```
|
||||
你会发现使用了Gamma校正,监视器最终会显示出我们在应用中设置的那种线性的颜色。
|
||||
|
||||
!!! Important
|
||||
|
||||
2.2通常是是大多数显示设备的大概平均gamma值。基于gamma2.2的颜色空间叫做sRGB颜色空间。每个监视器的gamma曲线都有所不同,但是gamma2.2在大多数监视器上表现都不错。出于这个原因,游戏经常都会为玩家提供改变游戏gamma设置的选项,以适应每个监视器(译注:现在Gamma2.2相当于一个标准,后文中你会看到。但现在你可能会问,前面不是说Gamma2.2看起来不是正好适合人眼么,为何还需要校正。这是因为你在程序中设置的颜色,比如光照都是基于线性Gamma,即Gamma1,所以你理想中的亮度和实际表达出的不一样,如果要表达出你理想中的亮度就要对这个光照进行校正)。
|
||||
|
||||
有两种在你的场景中应用gamma校正的方式:
|
||||
|
||||
使用OpenGL内建的sRGB帧缓冲。
|
||||
自己在像素着色器中进行gamma校正。
|
||||
第一个选项也许是最简单的方式,但是我们也会丧失一些控制权。开启GL_FRAMEBUFFER_SRGB,可以告诉OpenGL每个后续的绘制命令里,在颜色储存到颜色缓冲之前先校正sRGB颜色。sRGB这个颜色空间大致对应于gamma2.2,它也是家用设备的一个标准。开启GL_FRAMEBUFFER_SRGB以后,每次像素着色器运行后续帧缓冲,OpenGL将自动执行gamma校正,包括默认帧缓冲。
|
||||
|
||||
开启GL_FRAMEBUFFER_SRGB简单的调用glEnable就行:
|
||||
|
||||
```c++
|
||||
glEnable(GL_FRAMEBUFFER_SRGB);
|
||||
```
|
||||
|
||||
自此,你渲染的图像就被进行gamma校正处理,你不需要做任何事情硬件就帮你处理了。有时候,你应该记得这个建议:gamma校正将把线性颜色空间转变为非线性空间,所以在最后一步进行gamma校正是极其重要的。如果你在最后输出之前就进行gamma校正,所有的后续操作都是在操作不正确的颜色值。例如,如果你使用多个怎还冲,你可能打算让两个帧缓冲之间传递的中间结果仍然保持线性空间颜色,只是给发送给监视器的最后的那个帧缓冲应用gamma校正。
|
||||
|
||||
第二个方法稍微复杂点,但同时也是我们对gamma操作有完全的控制权。我们在每个相关像素着色器运行的最后应用gamma校正,所以在发送到帧缓冲前,颜色就被校正了。
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
// do super fancy lighting
|
||||
[...]
|
||||
// apply gamma correction
|
||||
float gamma = 2.2;
|
||||
fragColor.rgb = pow(fragColor.rgb, vec3(1.0/gamma));
|
||||
}
|
||||
```
|
||||
|
||||
最后一行代码,将fragColor的每个颜色元素应用有一个1.0/gamma的幂运算,校正像素着色器的颜色输出。
|
||||
|
||||
这个方法有个问题就是为了保持一致,你必须在像素着色器里加上这个gamma校正,所以如果你有很多像素着色器,它们可能分别用于不同物体,那么你就必须在每个着色器里都加上gamma校正了。一个更简单的方案是在你的渲染循环中引入后处理阶段,在后处理四边形上应用gamma校正,这样你只要做一次就好了。
|
||||
|
||||
这些单行代码代表了gamma校正的实现。不太令人印象深刻,但当你进行gamma校正的时候有一些额外的事情别忘了考虑。
|
||||
|
||||
#### sRGB纹理
|
||||
|
||||
因为监视器总是在sRGB空间中显示应用了gamma的颜色,无论什么时候当你在计算机上绘制、编辑或者画出一个图片的时候,你所选的颜色都是根据你在监视器上看到的那种。这实际意味着所有你创建或编辑的图片并不是在线性空间,而是在sRGB空间中(译注:sRGB空间定义的gamma接近于2.2),假如在你的屏幕上对暗红色翻一倍,便是根据你所感知到的亮度进行的,并不等于将红色元素加倍。
|
||||
|
||||
结果就是纹理编辑者,所创建的所有纹理都是在sRGB空间中的纹理,所以如果我们在渲染应用中使用这些纹理,我们必须考虑到这点。在我们应用gamma校正之前,这不是个问题,因为纹理在sRGB空间创建和展示,同样我们还是在sRGB空间中使用,从而不必gamma校正纹理显示也没问题。然而,现在我们是把所有东西都放在线性空间中展示的,纹理颜色就会变坏,如下图展示的那样:
|
||||
|
||||
|
||||
|
||||
纹理图像实在太亮了,发生这种情况是因为,它们实际上进行了两次gamma校正!想一想,当我们基于监视器上看到的情况创建一个图像,我们就已经对颜色值进行了gamma校正,所以再次显示在监视器上就没错。由于我们在渲染中又进行了一次gamma校正,图片就实在太亮了。
|
||||
|
||||
为了修复这个问题,我们得确保纹理制作者是在线性空间中进行创作的。但是,由于大多数纹理制作者并不知道什么是gamma校正,并且在sRGB空间中进行创作更简单,这也许不是一个好办法。
|
||||
|
||||
另一个解决方案是重校,或把这些sRGB纹理在进行任何颜色值的计算前变回线性空间。我们可以这样做:
|
||||
|
||||
```c++
|
||||
float gamma = 2.2;
|
||||
vec3 diffuseColor = pow(texture(diffuse, texCoords).rgb, vec3(gamma));
|
||||
```
|
||||
|
||||
为每个sRGB空间的纹理做这件事非常烦人。幸好,OpenGL给我们提供了另一个方案来解决我们的麻烦,这就是GL_SRGB和GL_SRGB_ALPHA内部纹理格式。
|
||||
|
||||
如果我们在OpenGL中创建了一个纹理,把它指定为以上两种sRGB纹理格式其中之一,OpenGL将自动把颜色校正到线性空间中,这样我们所使用的所有颜色值都是在线性空间中的了。我们可以这样把一个纹理指定为一个sRGB纹理:
|
||||
|
||||
```c++
|
||||
glTexImage2D(GL_TEXTURE_2D, 0, GL_SRGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, image);
|
||||
```
|
||||
|
||||
如果你还打算在你的纹理中引入alpha元素,必究必须将纹理的内部格式指定为GL_SRGB_ALPHA。
|
||||
|
||||
因为不是所有纹理都是在sRGB空间中的所以当你把纹理指定为sRGB纹理时要格外小心。比如diffuse纹理,这种为物体上色的纹理几乎都是在sRGB空间中的。而为了获取光照参数的纹理,像specular贴图和法线贴图几乎都在线性空间中,所以如果你把它们也配置为sRGB纹理的话,光照就坏掉了。指定sRGB纹理时要当心。
|
||||
|
||||
将diffuse纹理定义为sRGB纹理之后,你将获得你所期望的视觉输出,但这次每个物体都会只进行一次gamma校正。
|
||||
|
||||
|
||||
## 衰减
|
||||
|
||||
在使用了gamma校正之后,另一个不同之处是光照衰减。真实的物理世界中,光照的衰减和光源的距离的平方成反比。
|
||||
|
||||
```c++
|
||||
float attenuation = 1.0 / (distance * distance);
|
||||
```
|
||||
|
||||
然而,当我们使用这个衰减公式的时候,衰减效果总是过于强烈,光只能照亮一小圈,看起来并不真实。出于这个原因,我们使用在基本光照教程中所讨论的那种衰减方程,它给了我们更大的控制权,此外我们还可以使用双曲线函数:
|
||||
|
||||
```c++
|
||||
float attenuation = 1.0 / distance;
|
||||
```
|
||||
|
||||
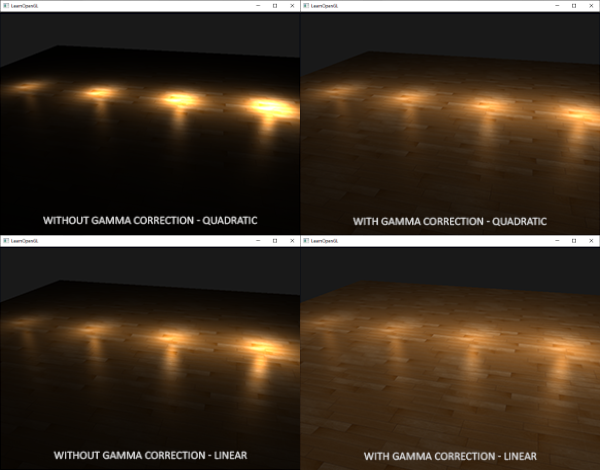
双曲线比使用二次函数变体在不用gamma校正的时候看起来更真实,不过但我们开启gamma校正以后线性衰减看起来太弱了,符合物理的二次函数突然出现了更好的效果。下图显示了其中的不同:
|
||||
|
||||
|
||||
|
||||
这种差异产生的原因是,光的衰减方程改变了亮度值,而且屏幕上显示出来的也不是线性空间,在监视器上效果最好的衰减方程,并不是符合物理的。想想平方衰减方程,如果我们使用这个方程,而且不进行gamma校正,显示在监视器上的衰减方程实际上将变成:
|
||||
|
||||
```math
|
||||
{(1.0 / distance2)}^{2.2}
|
||||
```
|
||||
若不进行gamma校正,将产生更强烈的衰减。这也解释了为什么双曲线不用gamma校正时看起来更真实,因为它实际变成了
|
||||
|
||||
```math
|
||||
{(1.0 / distance)}^{2.2} = 1.0 / distance^{2.2}
|
||||
```
|
||||
这和物理公式是很相似的。
|
||||
|
||||
!!! Important
|
||||
|
||||
我们在基础光照教程中讨论的更高级的那个衰减方程在有gamma校正的场景中也仍然有用,因为它可以让我们对衰减拥有更多准确的控制权(不过,在进行gamma校正的场景中当然需要不同的参数)。
|
||||
|
||||
我创建的这个简单的demo场景,你可以在这里找到源码以及顶点和像素着色器。按下空格就能在有gamma校正和无gamma校正的场景进行切换,两个场景使用的是相同的纹理和衰减。这不是效果最好的demo,不过它能展示出如何应用所有这些技术。
|
||||
|
||||
总而言之,gamma校正使你可以在线性空间中进行操作。因为线性空间更符合物理世界,大多数物理公式现在都可以获得较好效果,比如真实的光的衰减。你的光照越真实,使用gamma校正获得漂亮的效果就越容易。这也正是为什么当引进gamma校正时,建议只去调整光照参数的原因。
|
||||
|
||||
|
||||
|
||||
### 附加资源
|
||||
|
||||
[cambridgeincolour.com](http://www.cambridgeincolour.com/tutorials/gamma-correction.htm):更多关于gamma和gamma校正的内容。
|
||||
|
||||
[wolfire.com](http://blog.wolfire.com/2010/02/Gamma-correct-lighting): David Rosen关于在渲染领域使用gamma校正的好处。
|
||||
|
||||
[renderwonk.com](http://renderwonk.com/blog/index.php/archive/adventures-with-gamma-correct-rendering/): 一些额外的实践上的思考。
|
||||
551
05 Advanced Lighting/03 Shadows/01 Shadow Mapping.md
Normal file
551
05 Advanced Lighting/03 Shadows/01 Shadow Mapping.md
Normal file
@@ -0,0 +1,551 @@
|
||||
本文作者JoeyDeVries,由Django翻译自[http://learnopengl.com](http://learnopengl.com)
|
||||
|
||||
## 阴影映射(Shadow Mapping)
|
||||
|
||||
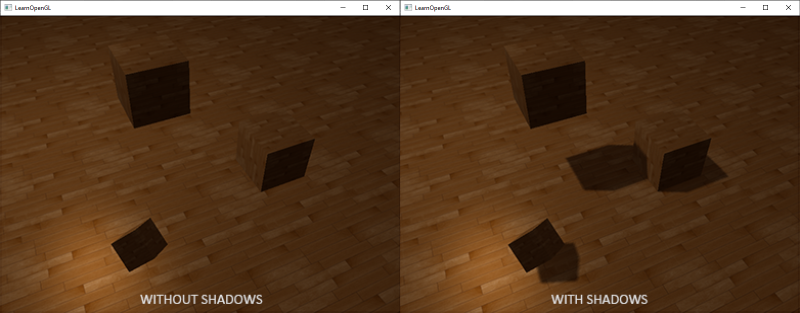
阴影是光线被阻挡的结果;当一个光源的光线由于其他物体的阻挡不能够达到一个物体的表面的时候,那么它就在阴影中了。阴影能够给场景中加入非常显著的真实性,并且观察者能够获得更好的物体之间的空间感。场景和物体的深度感因此能够得到极大提升,下图展示了有阴影和没有阴影的情况下的不同:
|
||||
|
||||
|
||||
|
||||
你可以看到,有阴影的时候你能更容易地区分出物体之间的关系,例如,当使用阴影的时候浮在地板上的立方体的事实更加清晰。
|
||||
|
||||
阴影还是比较不好实现的,因为当前实时渲染领域还没找到一种完美的阴影算法。不过有几种近似阴影技术,但它们都有自己的弱点和不足,这点我们必须要考虑到。
|
||||
|
||||
视频游戏中较多使用的一种技术是阴影贴图(shadow mapping),效果不错,而且相对容易实现。阴影贴图并不难以理解,性能也不会太低,而且非常容易扩展成更高级的算法(比如 Omnidirectional Shadow Maps和 Cascaded Shadow Maps)。
|
||||
|
||||
### 阴影映射
|
||||
|
||||
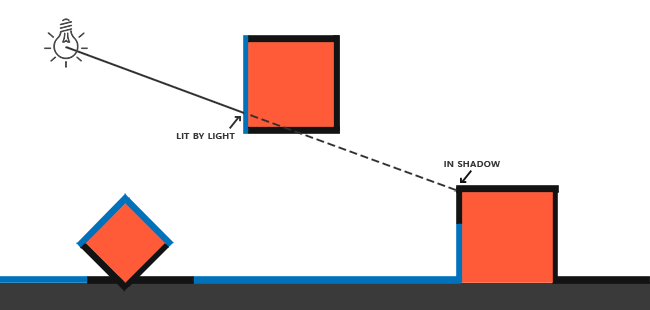
阴影映射背后的思路非常简单:我们以光的位置为视角进行渲染,我们从光的位置对场景进行透视,我们能看到的东西都将被点亮,看不见的一定是在阴影之中了。假设有一个地板,在光源和它之间有一个大盒子。由于光源处向光线方向看去,可以看到这个盒子,但看不到地板的一部分,这部分就应该在阴影中了。
|
||||
|
||||
|
||||
|
||||
这里的所有蓝线代表光源可以看到的fragment。黑线代表被遮挡的fragment:它们应该渲染为带阴影的。如果我们绘制一条从光源出发,到答最右边盒子上的一个fragment上的线段或射线,那么射线将先击中悬浮的盒子,随后才会到达最右侧的盒子。结果就是悬浮的盒子被照亮,而最右侧的盒子将处于阴影之中。
|
||||
|
||||
我们希望得到射线第一次击中的那个物体,然后用这个最近点和涉嫌上其他点进行对比。然后我们将测试一下看看射线上的其他点是否比最近点更远,如果是的话,测试点就在阴影中。对从光源发出的射线上的成千上万个点进行遍历是个极端消耗性能的举措,实时渲染上基本不可取。我们可以采取相似举措,不过不用投射出光的射线。我们所使用的是非常熟悉的东西:深度缓冲。
|
||||
|
||||
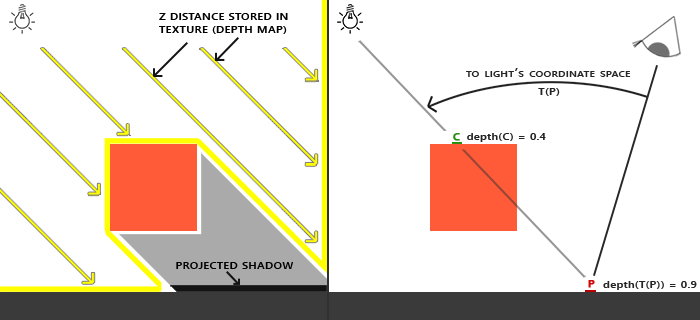
你可能记得在深度测试教程中,在深度缓冲里的一个值是摄像机视角下,对应于一个fragment的一个0到1之间的深度值。如果我们从光源的透视图来渲染场景,并把深度值的结果储存到纹理中会怎样?通过这种方式,我们就能对光源的透视图所见的最近的深度值进行采样。最终,深度值就会显示从光源的透视图下见到的第一个fragment了。我们管储存在纹理中的所有这些深度值,叫做深度贴图(depth map)或阴影贴图。
|
||||
|
||||
|
||||
|
||||
左侧的图片展示了一个定向光源(所有光线都是平行的)在立方体下的表面投射的阴影。通过储存到深度贴图中的深度值,我们就能找到最近点,用以决定fragment是否在阴影中。我们使用一个来自光源的视图和投影矩阵来渲染场景就能创建一个深度贴图。这个投影和视图矩阵结合在一起成为一个T变换,它可以将任何3D位置转变为光的可见坐标空间。
|
||||
|
||||
!!! Important
|
||||
|
||||
定向光并没有位置,因为它被规定为无穷远。然而,为了实现阴影贴图,我们得从一个光的透视图渲染场景,这样就得在光的方向的某一点上渲染场景。
|
||||
|
||||
我们渲染一个在点P的fragment,我们必须决定它是否在阴影中。我们先得使用T把P变换到光的坐标空间里。因为点P是从光的透视图中看到的,它的z坐标对应于它的深度,现在这个值是0.9。使用点P,我们也可以索引深度贴图,来获得从光的透视图中最近的可见深度,现在它是点C,被采样的深度是0.4。因为索引深度贴图返回的是一个小于点P的深度,我们可以断定P被挡住了,它在阴影中了。
|
||||
|
||||
深度映射由两个步骤组成:首先,我们渲染深度贴图,然后我们像往常一样渲染场景,使用生成的深度贴图来计算fragment是否在阴影之中。听起来有点复杂,但随着我们一步一步地讲解这个技术,就能理解了。
|
||||
|
||||
### 深度贴图(depth map)
|
||||
|
||||
第一步我们需要生成一张深度贴图。深度贴图是哦那个光的透视图里渲染的深度纹理,用它计算阴影。因为我们需要将场景的渲染结果储存到一个纹理中,我们将再次需要帧缓冲。
|
||||
|
||||
首先,我们要为渲染的深度贴图创建一个帧缓冲对象:
|
||||
|
||||
```c++
|
||||
GLuint depthMapFBO;
|
||||
glGenFramebuffers(1, &depthMapFBO);
|
||||
```
|
||||
|
||||
然后,创建一个2D纹理,提供给帧缓冲的深度缓冲使用:
|
||||
|
||||
```c++
|
||||
const GLuint SHADOW_WIDTH = 1024, SHADOW_HEIGHT = 1024;
|
||||
|
||||
GLuint depthMap;
|
||||
glGenTextures(1, &depthMap);
|
||||
glBindTexture(GL_TEXTURE_2D, depthMap);
|
||||
glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT,
|
||||
SHADOW_WIDTH, SHADOW_HEIGHT, 0, GL_DEPTH_COMPONENT, GL_FLOAT, NULL);
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
|
||||
```
|
||||
|
||||
生成深度贴图不太复杂。因为我们只关心深度值,我们要把纹理格式指定为GL_DEPTH_COMPONENT。我们还要把纹理的高宽设置为1024:这是深度贴图的解析度。
|
||||
|
||||
把我们把生成的深度纹理作为帧缓冲的深度缓冲:
|
||||
|
||||
```c++
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
|
||||
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, GL_TEXTURE_2D, depthMap, 0);
|
||||
glDrawBuffer(GL_NONE);
|
||||
glReadBuffer(GL_NONE);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
```
|
||||
|
||||
我们需要的只是在从光的透视图下渲染场景的时候深度信息,所以颜色缓冲没有用。然而帧缓冲对象不是完全不包含颜色缓冲的,所以我们需要显式告诉OpenGL我们不适用任何颜色数据进行渲染。我们通过将调用glDrawBuffer和glReadBuffer把读和绘制缓冲设置为GL_NONE来做这件事。
|
||||
|
||||
合理配置将深度值渲染到纹理的帧缓冲后,我们就可以开始第一步了:生成深度贴图。两个步骤的完整的渲染阶段,看起来有点像这样:
|
||||
|
||||
```c++
|
||||
// 1. first render to depth map
|
||||
glViewport(0, 0, SHADOW_WIDTH, SHADOW_HEIGHT);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
|
||||
glClear(GL_DEPTH_BUFFER_BIT);
|
||||
ConfigureShaderAndMatrices();
|
||||
RenderScene();
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
// 2. then render scene as normal with shadow mapping (using depth map)
|
||||
glViewport(0, 0, SCR_WIDTH, SCR_HEIGHT);
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
|
||||
ConfigureShaderAndMatrices();
|
||||
glBindTexture(GL_TEXTURE_2D, depthMap);
|
||||
RenderScene();
|
||||
```
|
||||
|
||||
这段代码隐去了一些细节,但它表达了阴影映射的基本思路。这里一定要记得调用glViewport。因为阴影贴图经常和我们原来渲染的场景(通常是窗口解析度)有着不同的解析度,我们需要改变视口(viewport)的参数以适应阴影贴图的尺寸。如果我们忘了更新视口参数,最后的深度贴图要么太小要么就不完整。
|
||||
|
||||
|
||||
|
||||
### 光空间的变换(light spacce transform)
|
||||
|
||||
前面那段代码中一个不清楚的函数是COnfigureShaderAndMatrices。它是用来在第二个步骤确保为每个物体设置了合适的投影和视图矩阵,以及相关的模型矩阵。然而,第一个步骤中,我们从光的位置的视野下使用了不同的投影和视图矩阵来渲染的场景。
|
||||
|
||||
因为我们使用的是一个所有光线都平行的定向光。出于这个原因,我们将为光源使用正交投影矩阵,透视图将没有任何变形:
|
||||
|
||||
```c++
|
||||
GLfloat near_plane = 1.0f, far_plane = 7.5f;
|
||||
glm::mat4 lightProjection = glm::ortho(-10.0f, 10.0f, -10.0f, 10.0f, near_plane, far_plane);
|
||||
```
|
||||
|
||||
这里有个本节教程的demo场景中使用的正交投影矩阵的例子。因为投影矩阵间接决定可视区域的范围,以及什么东西不会被裁切,你希望能保证投影视锥(frustum)的大小,以包含打算在深度贴图中包含的物体。当物体和fragment不在深度贴图中时,它们就不会产生阴影。
|
||||
|
||||
为了创建一个视图矩阵来变换每个物体,这样它们从光的视野看去就是可见的了,我们将使用臭名昭著的glm::lookAt函数;这次从光源的位置看向场景中央。
|
||||
|
||||
```c++
|
||||
glm::mat4 lightView = glm::lookAt(glm::vec(-2.0f, 4.0f, -1.0f), glm::vec3(0.0f), glm::vec3(1.0));
|
||||
```
|
||||
|
||||
二者相结合为我们提供了一个光空间的变换矩阵,它将每个世界空间坐标变换到光源处所见到的那个空间;这正是我们渲染深度贴图所需要的。
|
||||
|
||||
```c++
|
||||
glm::mat4 lightSpaceMatrix = lightProjection * lightView;
|
||||
```
|
||||
|
||||
这个lightSpaceMatrix正是前面我们称为T的那个变换矩阵。有了lightSpaceMatrix只要给shader提供光空间的投影和视图矩阵,我们就能像往常那样渲染场景了。然而,我们只关心深度值,并非所有fragment计算都在我们的着色器中进行。为了提升性能,我们将使用一个与之不同但更为简单的着色器来渲染出深度贴图。
|
||||
|
||||
### 渲染出深度贴图
|
||||
|
||||
当我们以光的透视图进行场景渲染的时候,我们会用一个比较简单的着色器,这个着色器除了把顶点变换到光空间以外,不会做得更多了。这个简单的着色器叫做simpleDepthShader,就是使用下面的这个着色器:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
|
||||
uniform mat4 lightSpaceMatrix;
|
||||
uniform mat4 model;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = lightSpaceMatrix * model * vec4(position, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
这个顶点着色器将一个单独模型的一个顶点,使用lightSpaceMatrix变换到光空间中。
|
||||
|
||||
由于我们没有颜色缓冲,最后的fragment不需要任何处理,所以我们可以简单地使用一个空像素着色器:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
|
||||
void main()
|
||||
{
|
||||
// gl_FragDepth = gl_FragCoord.z;
|
||||
}
|
||||
```
|
||||
|
||||
这个空像素着色器什么也不干,运行完后,深度缓冲会被更新。我们可以注释掉那行,来显式设置深度,这着呢个是场景私下里所发生的事情。
|
||||
|
||||
渲染深度缓冲现在成了:
|
||||
|
||||
```c++
|
||||
simpleDepthShader.Use();
|
||||
glUniformMatrix4fv(lightSpaceMatrixLocation, 1, GL_FALSE, glm::value_ptr(lightSpaceMatrix));
|
||||
|
||||
glViewport(0, 0, SHADOW_WIDTH, SHADOW_HEIGHT);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
|
||||
glClear(GL_DEPTH_BUFFER_BIT);
|
||||
RenderScene(simpleDepthShader);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
```
|
||||
|
||||
这里的RenderScene函数的参数是一个着色器程序(shader program),它调用所有相关的绘制函数,并在需要的地方设置相应的模型矩阵。
|
||||
|
||||
最后,在光的透视图视角下,很完美地用每个可见fragment的最近深度填充了深度缓冲。通过将这个纹理投射到一个2D四边形上,就能在屏幕上显示出来,我们会获得这样的东西:
|
||||
|
||||

|
||||
|
||||
将深度贴图渲染到四边形上的像素着色器:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 color;
|
||||
in vec2 TexCoords;
|
||||
|
||||
uniform sampler2D depthMap;
|
||||
|
||||
void main()
|
||||
{
|
||||
float depthValue = texture(depthMap, TexCoords).r;
|
||||
color = vec4(vec3(depthValue), 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
要注意的是当用透视投影矩阵取代正交投影矩阵来显示深度时,有一些轻微的改动,因为使用透视投影时,深度是非线性的。本节教程的最后,我们会讨论这些不同之处。
|
||||
|
||||
你可以在这里获得把场景渲染成深度贴图的源码。
|
||||
|
||||
### 渲染阴影
|
||||
|
||||
正确地生成深度贴图以后我们就可以开始生成阴影了。这段代码在像素着色器中执行,用来检验一个fragment是否在阴影之中,不过我们在顶点着色器中进行光空间的变换:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
layout (location = 1) in vec3 normal;
|
||||
layout (location = 2) in vec2 texCoords;
|
||||
|
||||
out vec2 TexCoords;
|
||||
|
||||
out VS_OUT {
|
||||
vec3 FragPos;
|
||||
vec3 Normal;
|
||||
vec2 TexCoords;
|
||||
vec4 FragPosLightSpace;
|
||||
} vs_out;
|
||||
|
||||
uniform mat4 projection;
|
||||
uniform mat4 view;
|
||||
uniform mat4 model;
|
||||
uniform mat4 lightSpaceMatrix;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0f);
|
||||
vs_out.FragPos = vec3(model * vec4(position, 1.0));
|
||||
vs_out.Normal = transpose(inverse(mat3(model))) * normal;
|
||||
vs_out.TexCoords = texCoords;
|
||||
vs_out.FragPosLightSpace = lightSpaceMatrix * vec4(vs_out.FragPos, 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
这儿的新的地方是FragPosLightSpace这个输出向量。我们用同一个lightSpaceMatrix,把世界空间顶点位置转换为光空间。顶点着色器传递一个普通的经变换的世界空间顶点位置vs_out.FragPos和一个光空间的vs_out.FragPosLightSpace给像素着色器。
|
||||
|
||||
像素着色器使用Blinn-Phong光照模型渲染场景。我们接着计算出一个shadow值,当fragment在阴影中时是1.0,在阴影外是0.0。然后,diffuse和specular颜色会乘以这个阴影元素。由于阴影不会是全黑的,我们把ambient颜色从乘法中剔除。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 FragColor;
|
||||
|
||||
in VS_OUT {
|
||||
vec3 FragPos;
|
||||
vec3 Normal;
|
||||
vec2 TexCoords;
|
||||
vec4 FragPosLightSpace;
|
||||
} fs_in;
|
||||
|
||||
uniform sampler2D diffuseTexture;
|
||||
uniform sampler2D shadowMap;
|
||||
|
||||
uniform vec3 lightPos;
|
||||
uniform vec3 viewPos;
|
||||
|
||||
float ShadowCalculation(vec4 fragPosLightSpace)
|
||||
{
|
||||
[...]
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
vec3 color = texture(diffuseTexture, fs_in.TexCoords).rgb;
|
||||
vec3 normal = normalize(fs_in.Normal);
|
||||
vec3 lightColor = vec3(1.0);
|
||||
// Ambient
|
||||
vec3 ambient = 0.15 * color;
|
||||
// Diffuse
|
||||
vec3 lightDir = normalize(lightPos - fs_in.FragPos);
|
||||
float diff = max(dot(lightDir, normal), 0.0);
|
||||
vec3 diffuse = diff * lightColor;
|
||||
// Specular
|
||||
vec3 viewDir = normalize(viewPos - fs_in.FragPos);
|
||||
vec3 reflectDir = reflect(-lightDir, normal);
|
||||
float spec = 0.0;
|
||||
vec3 halfwayDir = normalize(lightDir + viewDir);
|
||||
spec = pow(max(dot(normal, halfwayDir), 0.0), 64.0);
|
||||
vec3 specular = spec * lightColor;
|
||||
// Calculate shadow
|
||||
float shadow = ShadowCalculation(fs_in.FragPosLightSpace);
|
||||
vec3 lighting = (ambient + (1.0 - shadow) * (diffuse + specular)) * color;
|
||||
|
||||
FragColor = vec4(lighting, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
像素着色器大部分是从高级光照教程中复制过来,只不过加上了个阴影计算。我们声明一个shadowCalculation函数,用它计算阴影。像素着色器的最后,我们我们把diffuse和specular乘以(1-阴影元素),这表示这个fragment有多少不在阴影中。这个像素着色器还需要两个额外输入,一个是光空间的fragment位置和第一个渲染阶段得到的深度贴图。
|
||||
|
||||
首先要检查一个fragment是否在阴影中,把光空间fragment位置转换为裁切空间的标准化设备坐标。当我们在像素着色器输出一个裁切空间顶点位置到gl_Position时,OpenGL自动进行一个透视除法,将裁切空间坐标的范围-w到w转为-1到1,这要将x、y、z元素除以向量的w元素来实现。由于裁切空间的FragPosLightSpace并不会通过gl_Position传到像素着色器里,我们必须自己做透视除法:
|
||||
|
||||
```c++
|
||||
float ShadowCalculation(vec4 fragPosLightSpace)
|
||||
{
|
||||
// perform perspective divide
|
||||
vec3 projCoords = fragPosLightSpace.xyz / fragPosLightSpace.w;
|
||||
[...]
|
||||
}
|
||||
```
|
||||
|
||||
返回了fragment在光空间的-1到1的范围。
|
||||
|
||||
!!! Important
|
||||
|
||||
当使用正交投影矩阵,顶点w元素仍保持不变,所以这一步实际上毫无意义。可是,当使用透视投影的时候就是必须的了,所以为了保证在两种投影矩阵下都有效就得留着这行。
|
||||
|
||||
因为来自深度贴图的深度在0到1的范围,我们也打算使用projCoords从深度贴图中去采样,所以我们将NDC坐标变换为0到1的范围:
|
||||
|
||||
```c++
|
||||
projCoords = projCoords * 0.5 + 0.5;
|
||||
```
|
||||
|
||||
有了这些投影坐标,我们就能从深度贴图中采样得到0到1的结果,从第一个渲染阶段的projCoords坐标直接对应于变换过的NDC坐标。我们将得到光的位置视野下最近的深度:
|
||||
|
||||
```c++
|
||||
float closestDepth = texture(shadowMap, projCoords.xy).r;
|
||||
```
|
||||
|
||||
为了得到fragment的当前深度,我们简单获取投影向量的z坐标,它等于来自光的透视视角的fragment的深度。
|
||||
|
||||
```c++
|
||||
float currentDepth = projCoords.z;
|
||||
```
|
||||
|
||||
实际的对比就是简单检查currentDepth是否高于closetDepth,如果是,那么fragment就在阴影中。
|
||||
|
||||
```c++
|
||||
float shadow = currentDepth > closestDepth ? 1.0 : 0.0;
|
||||
```
|
||||
|
||||
完整的shadowCalculation函数是这样的:
|
||||
|
||||
```c++
|
||||
float ShadowCalculation(vec4 fragPosLightSpace)
|
||||
{
|
||||
// perform perspective divide
|
||||
vec3 projCoords = fragPosLightSpace.xyz / fragPosLightSpace.w;
|
||||
// Transform to [0,1] range
|
||||
projCoords = projCoords * 0.5 + 0.5;
|
||||
// Get closest depth value from light's perspective (using [0,1] range fragPosLight as coords)
|
||||
float closestDepth = texture(shadowMap, projCoords.xy).r;
|
||||
// Get depth of current fragment from light's perspective
|
||||
float currentDepth = projCoords.z;
|
||||
// Check whether current frag pos is in shadow
|
||||
float shadow = currentDepth > closestDepth ? 1.0 : 0.0;
|
||||
|
||||
return shadow;
|
||||
}
|
||||
```
|
||||
|
||||
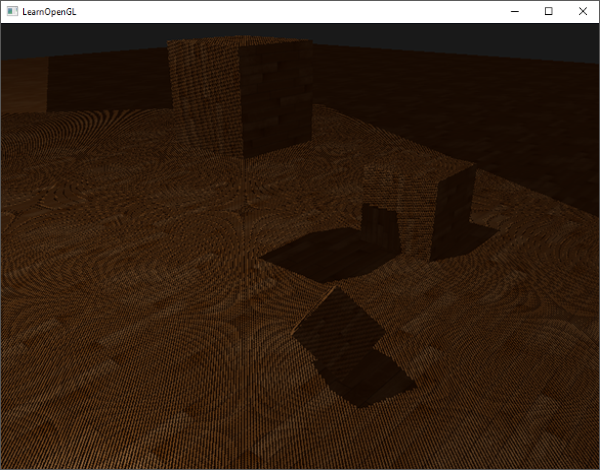
激活这个着色器,绑定合适的纹理,激活第二个渲染阶段默认的投影以及视图矩阵,结果如下图所示:
|
||||
|
||||
|
||||
|
||||
如果你做对了,你会看到地板和上有立方体的阴影。你可以从这里找到demo程序的源码。
|
||||
|
||||
### 改进阴影贴图
|
||||
|
||||
我们试图让阴影映射工作,但是你也看到了,阴影映射还是有点不真实,我们修复它才能获得更好的效果,这是下面的部分所关注的焦点。
|
||||
|
||||
#### 阴影失真(shadow acne)
|
||||
|
||||
前面的图片中明显有不对的地方。放大看会发现明显的线条样式:
|
||||
|
||||

|
||||
|
||||
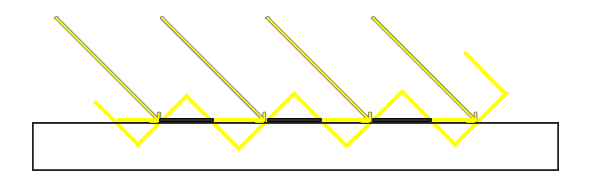
我们可以看到地板四边形渲染出很大一块交替黑线。这种阴影贴图的不真实感叫做阴影失真,下图解释了成因:
|
||||
|
||||
|
||||
|
||||
因为阴影贴图受限于解析度,在距离光源比较远的情况下,多个fragment可能从深度贴图的同一个值中去采样。图片每个斜坡代表深度贴图一个单独的纹理像素。你可以看到,多个fragment从同一个深度值进行采样。
|
||||
|
||||
虽然很多时候没问题,但是当光源以一个角度朝向表面的时候就会出问题,这种情况下深度贴图也是从一个角度下进行渲染的。多个fragment就会从同一个斜坡的深度纹理像素中采样,有些在地板上面,有些在地板下面;这样我们所得到的阴影就有了差异。因为这个,有些fragment被认为是在阴影之中,有些不在,由此产生了图片中的条纹样式。
|
||||
|
||||
我们可以用一个叫做shadow bias(阴影偏移)的技巧来解决这个问题,我们简单的对表面的深度(或深度贴图)应用一个偏移量,这样表面之下fragment就不会错了。
|
||||
|
||||
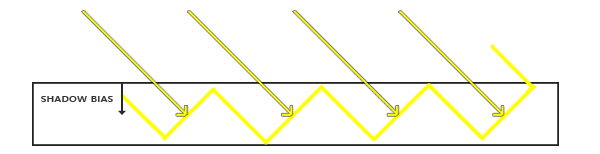
|
||||
|
||||
使用了偏移量所有样呗都获得了比表面深度更小的深度值,这样整个表面就正确地被照亮,没有任何阴影。我们可以这样实现这个偏移:
|
||||
|
||||
```c++
|
||||
float bias = 0.005;
|
||||
float shadow = currentDepth - bias > closestDepth ? 1.0 : 0.0;
|
||||
```
|
||||
|
||||
一个0.005的偏移就能帮到很大的忙,但是有些表面坡度很大,仍然会产生阴影失真。有一个更加可靠的办法能够根据表面朝向光线的角度更改偏移量:使用点乘:
|
||||
|
||||
```c++
|
||||
float bias = max(0.05 * (1.0 - dot(normal, lightDir)), 0.005);
|
||||
```
|
||||
|
||||
这里我们有一个偏移量的最大值0.05,和一个最小值0.005,它们是基于表面法线和光照方向的。这样像地板这样的表面几乎与光源垂直,得到的偏移就很小,而比如立方体的侧面这种表面得到的偏移就更大。下图展示了同一个场景,但使用了阴影偏移,效果的确更好:
|
||||
|
||||
|
||||
|
||||
选用正确的偏移数值,在不同的场景中需要一些像这样的轻微调校,但大多情况下,实际上就是增加偏移量直到所有失真都被移除的问题。
|
||||
|
||||
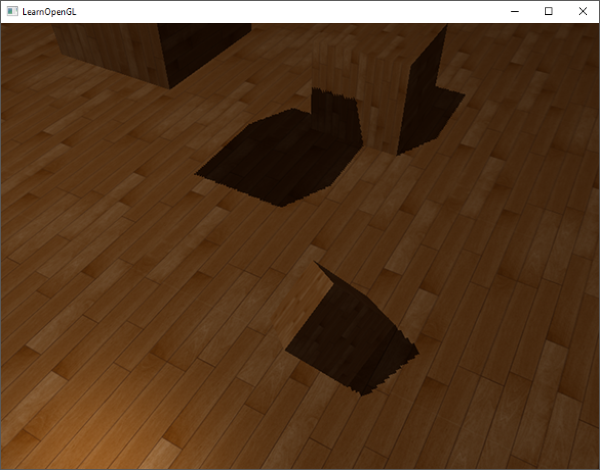
#### 悬浮
|
||||
|
||||
使用阴影偏移的一个缺点是你对物体的实际深度应用了平移。偏移有可能足够大,以至于可以很清楚的看到阴影和实际物体之间的偏移量,你可以从下图看到这个现象(这是一个夸张的偏移值):
|
||||
|
||||
|
||||
|
||||
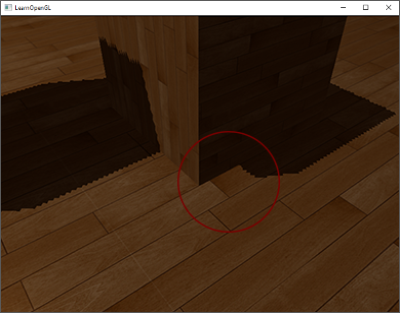
这个阴影失真叫做Peter panning,因为物体看起来轻轻悬浮在表面之上(译注Peter Pan就是童话彼得潘,而panning有平移、悬浮之意,而且彼得潘是个会飞的男孩…)。我们可以使用一个叫技巧解决大部分的Peter panning问题:当渲染深度贴图时候使用正面剔除(front face culling)你也许记得在面剔除教程中OpenGL默认是背面剔除。我们要告诉OpenGL我们要剔除正面。
|
||||
|
||||
因为我们只需要深度贴图的深度值,对于实体物体无论我们用它们的正面还是背面都没问题。使用背面深度不会有错误,因为阴影在物体内部有错误我们也看不见。
|
||||
|
||||
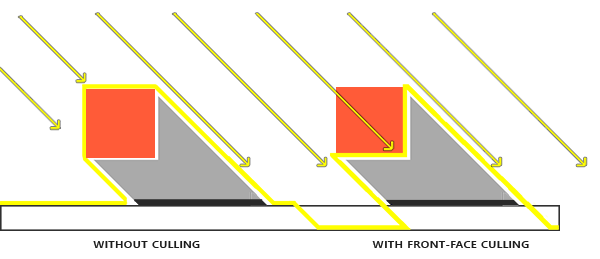
|
||||
|
||||
为了修复peter游移,我们要进行正面剔除,先必须开启GL_CULL_FACE:
|
||||
|
||||
```c++
|
||||
glCullFace(GL_FRONT);
|
||||
RenderSceneToDepthMap();
|
||||
glCullFace(GL_BACK); // don't forget to reset original culling face
|
||||
```
|
||||
|
||||
这十分有效地解决了peter panning的问题,但只针对实体物体,内部不会对外开口。我们的场景中,在立方体上工作的很好,但在地板上无效,因为正面剔除完全移除了地板。地面是一个单独的平面,不会被完全剔除。如果有人打算使用这个技巧解决peter panning必须考虑到只有剔除物体的正面才有意义。
|
||||
|
||||
另一个要考虑到的地方是接近阴影的物体仍然会出现不正确的效果。必须考虑到何时使用正面剔除对物体才有意义。不过使用普通的偏移值通常就能避免peter panning。
|
||||
|
||||
#### 采样超出
|
||||
|
||||
无论你喜不喜欢还有一个视觉差异,就是光的视锥不可见的区域一律被认为是处于阴影中,不管它真的处于阴影之中。出现这个状况是因为超出光的视锥的投影坐标比1.0大,这样采样的深度纹理就会超出他默认的0到1的范围。根据纹理环绕方式,我们将会得到不正确的深度结果,它不是基于真实的来自光源的深度值。
|
||||
|
||||
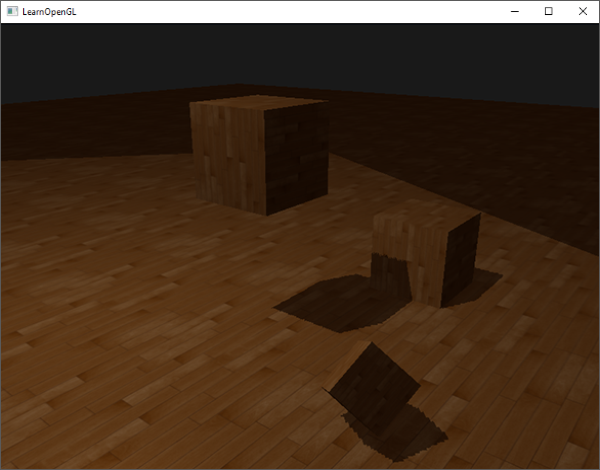
|
||||
|
||||
你可以在图中看到,光照有一个区域,超出该区域就成为了阴影;这个区域实际上代表着深度贴图的大小,这个贴图投影到了地板上。发生这种情况的原因是我们之前将深度贴图的环绕方式设置成了GL_REPEAT。
|
||||
|
||||
我们宁可让所有超出深度贴图的坐标的深度范围是1.0,这样超出的坐标将永远不在阴影之中。我们可以储存一个边框颜色,然后把深度贴图的纹理环绕选项设置为GL_CLAMP_TO_BORDER:
|
||||
|
||||
```c++
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_BORDER);
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_BORDER);
|
||||
GLfloat borderColor[] = { 1.0, 1.0, 1.0, 1.0 };
|
||||
glTexParameterfv(GL_TEXTURE_2D, GL_TEXTURE_BORDER_COLOR, borderColor);
|
||||
```
|
||||
|
||||
现在如果我们采样深度贴图0到1坐标范围以外的区域,纹理函数总会返回一个1.0的深度值,阴影值为0.0。结果看起来会更真实:
|
||||
|
||||
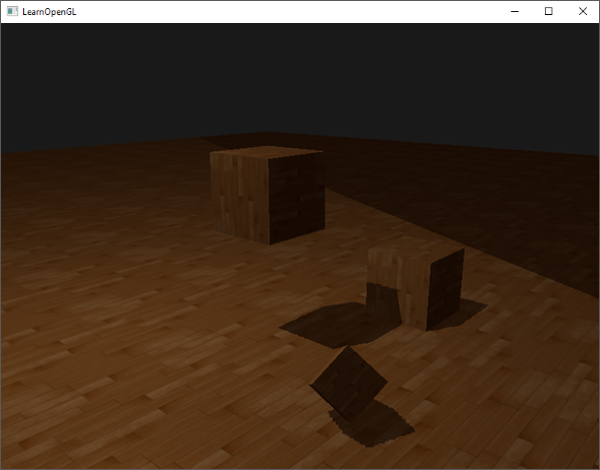
|
||||
|
||||
仍有一部分是黑暗区域。那里的坐标超出了光的正交视锥的远平面。你可以看到这片黑色区域总是出现在光源视锥的极远处。
|
||||
|
||||
一个投影坐标当它的z坐标大于1.0时,它比光的远平面还要远。这种情况下,GL_CLAMP_TO_BORDER环绕方式不起作用,因为我们把坐标的z元素和深度贴图的值进行了对比;它总是为大于1.0的z返回true。
|
||||
|
||||
解决这个问题也很简单,我们简单的强制把shadow的值设为0.0,不管投影向量的z坐标是否大于1.0:
|
||||
|
||||
```c++
|
||||
float ShadowCalculation(vec4 fragPosLightSpace)
|
||||
{
|
||||
[...]
|
||||
if(projCoords.z > 1.0)
|
||||
shadow = 0.0;
|
||||
|
||||
return shadow;
|
||||
}
|
||||
```
|
||||
|
||||
检查院平面,并将深度贴图限制为一个手工指定的边界颜色,就能解决深度贴图采样超出的问题,我们最终会得到下面我们所追求的效果:
|
||||
|
||||
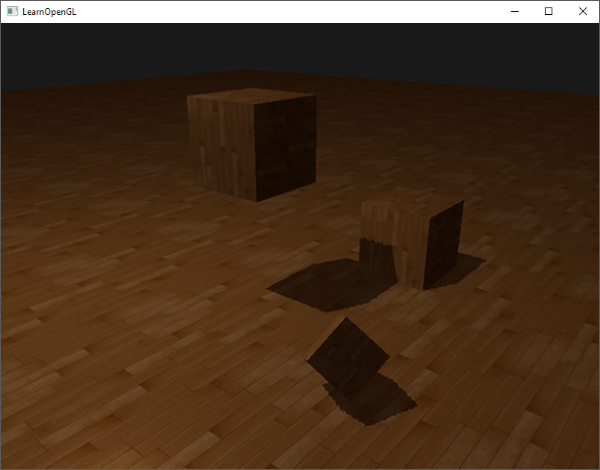
|
||||
|
||||
这些结果意味着,只有在深度贴图范围以内的被投影的fragment坐标才有阴影,所以任何超出范围的都将会没有阴影。由于在游戏中通常这只发生在远处,就会比我们之前的那个明显的黑色区域效果更真实。
|
||||
|
||||
#### PCF
|
||||
|
||||
阴影现在已经附着到场景中了,不过这仍不是我们想要的。如果你放大看阴影,阴影映射对解析度的依赖很快变得很明显。
|
||||
|
||||

|
||||
|
||||
因为深度贴图有一个固定的解析度,多个fragment对应于一个纹理像素。结果就是多个fragment会从深度贴图的同一个深度值进行采样,这几个fragment便得到的是同一个阴影,这就会产生锯齿边。
|
||||
|
||||
你可以通过增加深度贴图解析度的方式来降低锯齿块,也可以尝试尽可能的让光的视锥接近场景。
|
||||
|
||||
另一个(并不完整的)解决方案叫做PCF(percentage-closer filtering),这是一种多个不同过滤方式的组合,它产生柔和阴影,使它们出现更少的锯齿块和硬边。核心思想是从深度贴图中多次采样,每一次采样的纹理坐标都稍有不同。每个独立的样本可能在也可能不再阴影中。所有的次生结果接着结合在一起,进行平均化,我们就得到了柔和阴影。
|
||||
|
||||
一个简单的PCF的实现是简单的从纹理像素四周对深度贴图采样,然后平均化结果:
|
||||
|
||||
```c++
|
||||
float shadow = 0.0;
|
||||
vec2 texelSize = 1.0 / textureSize(shadowMap, 0);
|
||||
for(int x = -1; x <= 1; ++x)
|
||||
{
|
||||
for(int y = -1; y <= 1; ++y)
|
||||
{
|
||||
float pcfDepth = texture(shadowMap, projCoords.xy + vec2(x, y) * texelSize).r;
|
||||
shadow += currentDepth - bias > pcfDepth ? 1.0 : 0.0;
|
||||
}
|
||||
}
|
||||
shadow /= 9.0;
|
||||
```
|
||||
|
||||
这个textureSize返回一个给定采样器纹理的0级mipmap的vec2类型的宽和高。用1除以它返回一个单独纹理像素的大小,我们用以对纹理坐标进行偏移,确保每个新样本,来自不同的深度值。这里我们采样得到9个值,它们在投影坐标的x和y值的周围,为阴影阻挡进行测试,并最终通过样本的总数目将结果平均化。
|
||||
|
||||
使用更多的样本,更改texelSize变量,你就可以增加阴影的柔和程度。下面你可以看到应用了PCF的阴影:
|
||||
|
||||
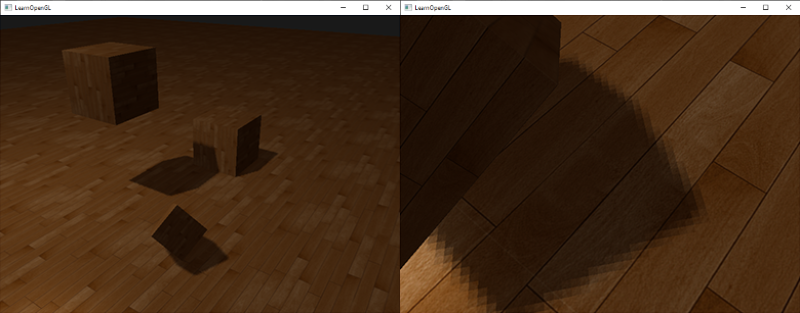
|
||||
|
||||
从稍微远一点的距离看去,阴影效果好多了,也不那么生硬了。如果你放大,仍会看到阴影贴图解析度的不真实感,但通常对于大多数应用来说效果已经很好了。
|
||||
|
||||
你可以从这里找到这个例子的全部源码和第二个阶段的像素和顶点着色器。
|
||||
|
||||
实际上PCF还有更多的内容,以及很多技术要点需要考虑以提升柔和阴影的效果,但处于本章内容长度考虑,我们将留在以后讨论。
|
||||
|
||||
|
||||
|
||||
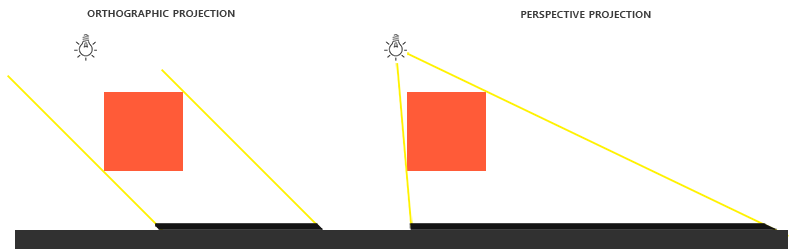
### 正交 vs 投影
|
||||
|
||||
在渲染深度贴图的时候,正交和投影矩阵之间有所不同。正交投影矩阵并不会将场景用透视图进行变形,所有视线/光线都是平行的,这使它对于定向光来说是个很好的投影矩阵。然而透视投影矩阵,会将所有顶点根据透视关系进行变形,结果因此而不同。下图展示了两种投影方式所产生的不同阴影区域:
|
||||
|
||||
|
||||
|
||||
透视投影对于光源来说更合理,不像定向光,它是有自己的位置的。透视投影因此更经常用在点光源和聚光灯上,而正交投影经常用在定向光上。
|
||||
|
||||
另一个细微差别是,透视投影矩阵,将深度缓冲视觉化经常会得到一个几乎全白的结果。发生这个是因为透视投影下,深度变成了非线性的深度值,它的大多数可辨范围接近于近平面。为了可以像使用正交投影一样合适的观察到深度值,你必须先讲过非线性深度值转变为线性的,我们在深度测试教程中已经讨论过。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 color;
|
||||
in vec2 TexCoords;
|
||||
|
||||
uniform sampler2D depthMap;
|
||||
uniform float near_plane;
|
||||
uniform float far_plane;
|
||||
|
||||
float LinearizeDepth(float depth)
|
||||
{
|
||||
float z = depth * 2.0 - 1.0; // Back to NDC
|
||||
return (2.0 * near_plane * far_plane) / (far_plane + near_plane - z * (far_plane - near_plane));
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
float depthValue = texture(depthMap, TexCoords).r;
|
||||
color = vec4(vec3(LinearizeDepth(depthValue) / far_plane), 1.0); // perspective
|
||||
// color = vec4(vec3(depthValue), 1.0); // orthographic
|
||||
}
|
||||
```
|
||||
|
||||
这个深度值与我们见到的用正交投影的很相似。需要注意的是,这个只适用于调试;正交或投影矩阵的深度检查仍然保持原样,因为相关的深度并没有改变。
|
||||
|
||||
### 附加资源
|
||||
|
||||
[Tutorial 16 : Shadow](http://www.opengl-tutorial.org/intermediate-tutorials/tutorial-16-shadow-mapping/)
|
||||
|
||||
[mapping:opengl-tutorial.org](http://ogldev.atspace.co.uk/www/tutorial23/tutorial23.html) 提供的类似的阴影映射教程,里面有一些额外的解释。
|
||||
|
||||
[Shadow Mapping – Part 1:ogldev](http://ogldev.atspace.co.uk/www/tutorial23/tutorial23.html)提供的另一个阴影映射教程。
|
||||
|
||||
[How Shadow Mapping Works](https://www.youtube.com/watch?v=EsccgeUpdsM):的一个第三方YouTube视频教程,里面解释了阴影映射及其实现。
|
||||
|
||||
[Common Techniques to Improve Shadow Depth Maps](https://msdn.microsoft.com/en-us/library/windows/desktop/ee416324%28v=vs.85%29.aspx):微软的一篇好文章,其中理出了很多提升阴影贴图质量的技术。
|
||||
481
05 Advanced Lighting/03 Shadows/02 Point Shadows.md
Normal file
481
05 Advanced Lighting/03 Shadows/02 Point Shadows.md
Normal file
@@ -0,0 +1,481 @@
|
||||
本文作者JoeyDeVries,由Django翻译自[http://learnopengl.com](http://learnopengl.com)
|
||||
|
||||
## 点光源阴影(Shadow Mapping)
|
||||
|
||||
上个教程我们学到了如何使用阴影映射技术创建动态阴影。效果不错,但它只适合定向光,因为阴影只是在单一定向光源下生成的。所以它也叫定向阴影映射,深度(阴影)贴图生成自定向光的视角。
|
||||
|
||||
!!! Important
|
||||
|
||||
本节我们的焦点是在各种方向生成动态阴影。这个技术可以适用于点光源,生成所有方向上的阴影。
|
||||
|
||||
这个技术叫做点光阴影,过去的名字是万向阴影贴图(omnidirectional shadow maps)技术。
|
||||
|
||||
本节代码基于前面的阴影映射教程,所以如果你对传统阴影映射不熟悉,还是建议先读一读阴影映射教程。
|
||||
算法和定向阴影映射差不多:我们从光的透视图生成一个深度贴图,基于当前fragment位置来对深度贴图采样,然后用储存的深度值和每个fragment进行对比,看看它是否在阴影中。定向阴影映射和万向阴影映射的主要不同在于深度贴图的使用上。
|
||||
|
||||
对于深度贴图,我们需要从一个点光源的所有渲染场景,普通2D深度贴图不能工作;如果我们使用cubemap会怎样?因为cubemap可以储存6个面的环境数据,它可以将整个场景渲染到cubemap的每个面上,把它们当作点光源四周的深度值来采样。
|
||||
|
||||
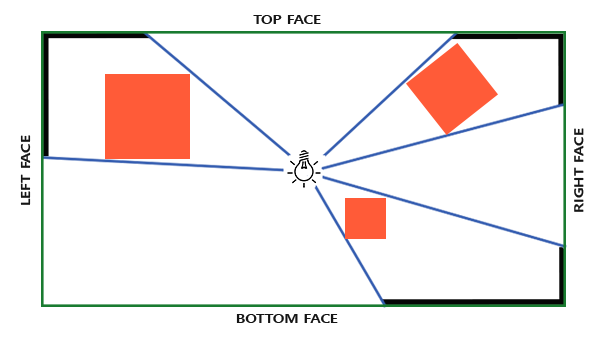
|
||||
|
||||
生成后的深度cubemap被传递到光照像素着色器,它会用一个方向向量来采样cubemap,从而得到当前的fragment的深度(从光的透视图)。大部分复杂的事情已经在阴影映射教程中讨论过了。算法只是在深度cubemap生成上稍微复杂一点。
|
||||
|
||||
#### 生成深度cubemap
|
||||
|
||||
为创建一个光周围的深度值的cubemap,我们必须渲染场景6次:每次一个面。显然渲染场景6次需要6个不同的视图矩阵,每次把一个不同的cubemap面附加到帧缓冲对象上。这看起来是这样的:
|
||||
|
||||
```c++
|
||||
for(int i = 0; i < 6; i++)
|
||||
{
|
||||
GLuint face = GL_TEXTURE_CUBE_MAP_POSITIVE_X + i;
|
||||
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, face, depthCubemap, 0);
|
||||
BindViewMatrix(lightViewMatrices[i]);
|
||||
RenderScene();
|
||||
}
|
||||
```
|
||||
|
||||
这会很耗费性能因为一个深度贴图下需要进行很多渲染调用。这个教程中我们将转而使用另外的一个小技巧来做这件事,几何着色器允许我们使用一次渲染过程来建立深度cubemap。
|
||||
|
||||
首先,我们需要创建一个cubemap:
|
||||
|
||||
```c++
|
||||
GLuint depthCubemap;
|
||||
glGenTextures(1, &depthCubemap);
|
||||
```
|
||||
|
||||
然后生成cubemap的每个面,将它们作为2D深度值纹理图像:
|
||||
|
||||
```c++
|
||||
const GLuint SHADOW_WIDTH = 1024, SHADOW_HEIGHT = 1024;
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, depthCubemap);
|
||||
for (GLuint i = 0; i < 6; ++i)
|
||||
glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0, GL_DEPTH_COMPONENT,
|
||||
SHADOW_WIDTH, SHADOW_HEIGHT, 0, GL_DEPTH_COMPONENT, GL_FLOAT, NULL);
|
||||
```
|
||||
|
||||
不要忘记设置合适的纹理参数:
|
||||
|
||||
```c++
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
|
||||
```
|
||||
|
||||
正常情况下,我们把cubemap纹理的一个面附加到帧缓冲对象上,渲染场景6次,每次将帧缓冲的深度缓冲目标改成不同cubemap面。由于我们将使用一个几何着色器,它允许我们把所有面在一个过程渲染,我们可以使用glFramebufferTexture直接把cubemap附加成帧缓冲的深度附件:
|
||||
|
||||
```c++
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
|
||||
glFramebufferTexture(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, depthCubemap, 0);
|
||||
glDrawBuffer(GL_NONE);
|
||||
glReadBuffer(GL_NONE);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
```
|
||||
|
||||
还要记得调用glDrawBuffer和glReadBuffer:当生成一个深度cubemap时我们只关心深度值,所以我们必须显式告诉OpenGL这个帧缓冲对象不会渲染到一个颜色缓冲里。
|
||||
|
||||
万向阴影贴图有两个渲染阶段:首先我们生成深度贴图,然后我们正常使用深度贴图渲染,在场景中创建阴影。帧缓冲对象和cubemap的处理看起是这样的:
|
||||
|
||||
```c++
|
||||
// 1. first render to depth cubemap
|
||||
glViewport(0, 0, SHADOW_WIDTH, SHADOW_HEIGHT);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
|
||||
glClear(GL_DEPTH_BUFFER_BIT);
|
||||
ConfigureShaderAndMatrices();
|
||||
RenderScene();
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
// 2. then render scene as normal with shadow mapping (using depth cubemap)
|
||||
glViewport(0, 0, SCR_WIDTH, SCR_HEIGHT);
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
|
||||
ConfigureShaderAndMatrices();
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, depthCubemap);
|
||||
RenderScene();
|
||||
```
|
||||
|
||||
这个过程和默认的阴影映射一样,尽管这次我们渲染和使用的是一个cubemap深度纹理,而不是2D深度纹理。在我们实际开始从光的视角的所有方向渲染场景之前,我们先得计算出合适的变换矩阵。
|
||||
|
||||
### 光空间的变换
|
||||
|
||||
设置了帧缓冲和cubemap,我们需要一些方法来讲场景的所有几何体变换到6个光的方向中相应的光空间。与阴影映射教程类似,我们将需要一个光空间的变换矩阵T,但是这次是每个面都有一个。
|
||||
|
||||
每个光空间的变换矩阵包含了投影和视图矩阵。对于投影矩阵来说,我们将使用一个透视投影矩阵;光源代表一个空间中的点,所以透视投影矩阵更有意义。每个光空间变换矩阵使用同样的投影矩阵:
|
||||
|
||||
```c++
|
||||
GLfloat aspect = (GLfloat)SHADOW_WIDTH/(GLfloat)SHADOW_HEIGHT;
|
||||
GLfloat near = 1.0f;
|
||||
GLfloat far = 25.0f;
|
||||
glm::mat4 shadowProj = glm::perspective(90.0f, aspect, near, far);
|
||||
```
|
||||
|
||||
非常重要的一点是,这里glm::perspective的视野参数,设置为90度。90度我们才能保证视野足够大到可以合适地填满cubemap的一个面,cubemap的所有面都能与其他面在边缘对齐。
|
||||
|
||||
因为投影矩阵在每个方向上并不会改变,我们可以在6个变换矩阵中重复使用。我们要为每个方向提供一个不同的视图矩阵。用glm::lookAt创建6个观察方向,每个都按顺序注视着cubemap的的一个方向:右、左、上、下、近、远:
|
||||
|
||||
```c++
|
||||
std::vector<glm::mat4> shadowTransforms;
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(1.0,0.0,0.0), glm::vec3(0.0,-1.0,0.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(-1.0,0.0,0.0), glm::vec3(0.0,-1.0,0.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,1.0,0.0), glm::vec3(0.0,0.0,1.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,-1.0,0.0), glm::vec3(0.0,0.0,-1.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,0.0,1.0), glm::vec3(0.0,-1.0,0.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,0.0,-1.0), glm::vec3(0.0,-1.0,0.0));
|
||||
```
|
||||
|
||||
这里我们创建了6个视图矩阵,把它们乘以投影矩阵,来得到6个不同的光空间变换矩阵。glm::lookAt的target参数是它注视的cubemap的面的一个方向。
|
||||
|
||||
这些变换矩阵发送到着色器渲染到cubemap里。
|
||||
|
||||
|
||||
|
||||
### 深度着色器
|
||||
|
||||
为了把值渲染到深度cubemap,我们将需要3个着色器:顶点和像素着色器,以及一个它们之间的几何着色器。
|
||||
|
||||
几何着色器是负责将所有世界空间的顶点变换到6个不同的光空间的着色器。因此顶点着色器简单地将顶点变换到世界空间,然后直接发送到几何着色器:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
|
||||
uniform mat4 model;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = model * vec4(position, 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
紧接着几何着色器以3个三角形的顶点作为输入,它还有一个光空间变换矩阵的uniform数组。几何着色器接下来会负责将顶点变换到光空间;这里它开始变得有趣了。
|
||||
|
||||
几何着色器有一个内建变量叫做gl_Layer,它指定发散出基本图形送到cubemap的哪个面。当不管它时,几何着色器就会像往常一样把它的基本图形发送到输送管道的下一阶段,但当我们更新这个变量就能控制每个基本图形将渲染到cubemap的哪一个面。当然这只有当我们有了一个附加到激活的帧缓冲的cubemap纹理才有效:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (triangles) in;
|
||||
layout (triangle_strip, max_vertices=18) out;
|
||||
|
||||
uniform mat4 shadowMatrices[6];
|
||||
|
||||
out vec4 FragPos; // FragPos from GS (output per emitvertex)
|
||||
|
||||
void main()
|
||||
{
|
||||
for(int face = 0; face < 6; ++face)
|
||||
{
|
||||
gl_Layer = face; // built-in variable that specifies to which face we render.
|
||||
for(int i = 0; i < 3; ++i) // for each triangle's vertices
|
||||
{
|
||||
FragPos = gl_in[i].gl_Position;
|
||||
gl_Position = shadowMatrices[face] * FragPos;
|
||||
EmitVertex();
|
||||
}
|
||||
EndPrimitive();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
几何着色器相对简单。我们输入一个三角形,输出总共6个三角形(6*3顶点,所以总共18个顶点)。在main函数中,我们遍历cubemap的6个面,我们每个面指定为一个输出面,把这个面的interger(整数)存到gl_Layer。然后,我们通过把面的光空间变换矩阵乘以FragPos,将每个世界空间顶点变换到相关的光空间,生成每个三角形。注意,我们还要将最后的FragPos变量发送给像素着色器,我们需要计算一个深度值。
|
||||
|
||||
上个教程,我们使用的是一个空的像素着色器,让OpenGL配置深度贴图的深度值。这次我们将计算自己的深度,这个深度就是每个fragment位置和光源位置之间的线性距离。计算自己的深度值使得之后的阴影计算更加直观。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
in vec4 FragPos;
|
||||
|
||||
uniform vec3 lightPos;
|
||||
uniform float far_plane;
|
||||
|
||||
void main()
|
||||
{
|
||||
// get distance between fragment and light source
|
||||
float lightDistance = length(FragPos.xyz - lightPos);
|
||||
|
||||
// map to [0;1] range by dividing by far_plane
|
||||
lightDistance = lightDistance / far_plane;
|
||||
|
||||
// Write this as modified depth
|
||||
gl_FragDepth = gl_FragCoord.z;
|
||||
}
|
||||
```
|
||||
|
||||
像素着色器将来自几何着色器的FragPos、光的位置向量和视锥的远平面值作为输入。这里我们把fragment和光源之间的距离,映射到0到1的范围,把它写入为fragment的深度值。
|
||||
|
||||
使用这些着色器渲染场景,cubemap附加的帧缓冲对象激活以后,你会得到一个完全填充的深度cubemap,以便于进行第二阶段的阴影计算。
|
||||
|
||||
### 万向阴影贴图
|
||||
|
||||
所有事情都做好了,是时候来渲染万向阴影了。这个过程和定向阴影映射教程相似,尽管这次我们绑定的深度贴图是一个cubemap,而不是2D纹理,并且将光的投影的远平面发送给了着色器。
|
||||
|
||||
```c++
|
||||
glViewport(0, 0, SCR_WIDTH, SCR_HEIGHT);
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
|
||||
shader.Use();
|
||||
// ... send uniforms to shader (including light's far_plane value)
|
||||
glActiveTexture(GL_TEXTURE0);
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, depthCubemap);
|
||||
// ... bind other textures
|
||||
RenderScene();
|
||||
```
|
||||
|
||||
这里的renderScene函数在一个大立方体房间中渲染一些立方体,它们散落在大立方体各处,光源在场景中央。
|
||||
|
||||
顶点着色器和像素着色器和原来的阴影映射着色器大部分都一样:不同之处是在光空间中像素着色器不再需要一个fragment位置,现在我们可以使用一个方向向量采样深度值。
|
||||
|
||||
因为这个顶点着色器不再需要将他的位置向量变换到光空间,所以我们可以去掉FragPosLightSpace变量:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
layout (location = 1) in vec3 normal;
|
||||
layout (location = 2) in vec2 texCoords;
|
||||
|
||||
out vec2 TexCoords;
|
||||
|
||||
out VS_OUT {
|
||||
vec3 FragPos;
|
||||
vec3 Normal;
|
||||
vec2 TexCoords;
|
||||
} vs_out;
|
||||
|
||||
uniform mat4 projection;
|
||||
uniform mat4 view;
|
||||
uniform mat4 model;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0f);
|
||||
vs_out.FragPos = vec3(model * vec4(position, 1.0));
|
||||
vs_out.Normal = transpose(inverse(mat3(model))) * normal;
|
||||
vs_out.TexCoords = texCoords;
|
||||
}
|
||||
```
|
||||
|
||||
片段着色器的Blinn-Phong光照代码和我们之前阴影相乘的结尾部分一样:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 FragColor;
|
||||
|
||||
in VS_OUT {
|
||||
vec3 FragPos;
|
||||
vec3 Normal;
|
||||
vec2 TexCoords;
|
||||
} fs_in;
|
||||
|
||||
uniform sampler2D diffuseTexture;
|
||||
uniform samplerCube depthMap;
|
||||
|
||||
uniform vec3 lightPos;
|
||||
uniform vec3 viewPos;
|
||||
|
||||
uniform float far_plane;
|
||||
|
||||
float ShadowCalculation(vec3 fragPos)
|
||||
{
|
||||
[...]
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
vec3 color = texture(diffuseTexture, fs_in.TexCoords).rgb;
|
||||
vec3 normal = normalize(fs_in.Normal);
|
||||
vec3 lightColor = vec3(0.3);
|
||||
// Ambient
|
||||
vec3 ambient = 0.3 * color;
|
||||
// Diffuse
|
||||
vec3 lightDir = normalize(lightPos - fs_in.FragPos);
|
||||
float diff = max(dot(lightDir, normal), 0.0);
|
||||
vec3 diffuse = diff * lightColor;
|
||||
// Specular
|
||||
vec3 viewDir = normalize(viewPos - fs_in.FragPos);
|
||||
vec3 reflectDir = reflect(-lightDir, normal);
|
||||
float spec = 0.0;
|
||||
vec3 halfwayDir = normalize(lightDir + viewDir);
|
||||
spec = pow(max(dot(normal, halfwayDir), 0.0), 64.0);
|
||||
vec3 specular = spec * lightColor;
|
||||
// Calculate shadow
|
||||
float shadow = ShadowCalculation(fs_in.FragPos);
|
||||
vec3 lighting = (ambient + (1.0 - shadow) * (diffuse + specular)) * color;
|
||||
|
||||
FragColor = vec4(lighting, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
有一些细微的不同:光照代码一样,但我们现在有了一个uniform变量samplerCube,shadowCalculation函数用fragment的位置作为它的参数,取代了光空间的fragment位置。我们现在还要引入光的视锥的远平面值,后面我们会需要它。像素着色器的最后,我们计算出阴影元素,当fragment在阴影中时它是1.0,不在阴影中时是0.0。我们使用计算出来的阴影元素去影响光照的diffuse和specular元素。
|
||||
|
||||
在ShadowCalculation函数中有很多不同之处,现在是从cubemap中进行采样,不再使用2D纹理了。我们来一步一步的讨论一下的它的内容。
|
||||
|
||||
我们需要做的第一件事是获取cubemap的森都。你可能已经从教程的cubemap部分想到,我们已经将深度储存为fragment和光位置之间的距离了;我们这里采用相似的处理方式:
|
||||
|
||||
```c++
|
||||
float ShadowCalculation(vec3 fragPos)
|
||||
{
|
||||
vec3 fragToLight = fragPos - lightPos;
|
||||
float closestDepth = texture(depthMap, fragToLight).r;
|
||||
}
|
||||
```
|
||||
|
||||
在这里,我们得到了fragment的位置与光的位置之间的不同的向量,使用这个向量作为一个方向向量去对cubemap进行采样。方向向量不需要是单位向量,所以无需对它进行标准化。最后的closestDepth是光源和它最接近的可见fragment之间的标准化的深度值。
|
||||
|
||||
closestDepth值现在在0到1的范围内了,所以我们先将其转换会0到far_plane的范围,这需要把他乘以far_plane:
|
||||
|
||||
```c++
|
||||
closestDepth *= far_plane;
|
||||
```
|
||||
|
||||
下一步我们获取当前fragment和光源之间的深度值,我们可以简单的使用fragToLight的长度来获取它,这取决于我们如何计算cubemap中的深度值:
|
||||
|
||||
```c++
|
||||
float currentDepth = length(fragToLight);
|
||||
```
|
||||
|
||||
返回的是和closestDepth范围相同的深度值。
|
||||
|
||||
现在我们可以将两个深度值对比一下,看看哪一个更接近,以此决定当前的fragment是否在阴影当中。我们还要包含一个阴影偏移,所以才能避免阴影失真,这在前面教程中已经讨论过了。
|
||||
|
||||
```c++
|
||||
float bias = 0.05;
|
||||
float shadow = currentDepth - bias > closestDepth ? 1.0 : 0.0;
|
||||
```
|
||||
|
||||
完整的ShadowCalculation现在变成了这样:
|
||||
|
||||
```c++
|
||||
float ShadowCalculation(vec3 fragPos)
|
||||
{
|
||||
// Get vector between fragment position and light position
|
||||
vec3 fragToLight = fragPos - lightPos;
|
||||
// Use the light to fragment vector to sample from the depth map
|
||||
float closestDepth = texture(depthMap, fragToLight).r;
|
||||
// It is currently in linear range between [0,1]. Re-transform back to original value
|
||||
closestDepth *= far_plane;
|
||||
// Now get current linear depth as the length between the fragment and light position
|
||||
float currentDepth = length(fragToLight);
|
||||
// Now test for shadows
|
||||
float bias = 0.05;
|
||||
float shadow = currentDepth - bias > closestDepth ? 1.0 : 0.0;
|
||||
|
||||
return shadow;
|
||||
}
|
||||
```
|
||||
|
||||
有了这些着色器,我们已经能得到非常好的阴影效果了,这次从一个点光源所有周围方向上都有阴影。有一个位于场景中心的点光源,看起来会像这样:
|
||||
|
||||
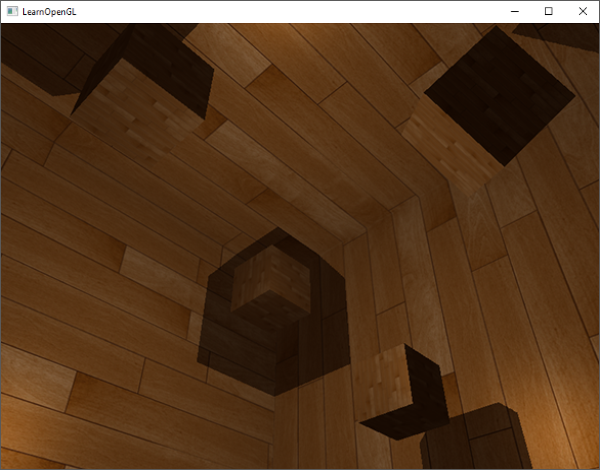
|
||||
|
||||
你可以从这里找到这个[demo的源码](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/point_shadows)、[顶点](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/point_shadows&type=vertex)和[片段](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/point_shadows&type=fragment)着色器。
|
||||
|
||||
#### 把cubemap深度缓冲显示出来
|
||||
|
||||
如果你想我一样第一次并没有做对,那么就要进行调试排错,将深度贴图显示出来以检查其是否正确。因为我们不再用2D深度贴图纹理,深度贴图的显示不会那么显而易见。
|
||||
|
||||
一个简单的把深度缓冲显示出来的技巧是,在ShadowCalculation函数中计算标准化的closestDepth变量,把变量显示为:
|
||||
|
||||
```c++
|
||||
FragColor = vec4(vec3(closestDepth / far_plane), 1.0);
|
||||
```
|
||||
|
||||
结果是一个灰度场景,每个颜色代表着场景的线性深度值:
|
||||
|
||||
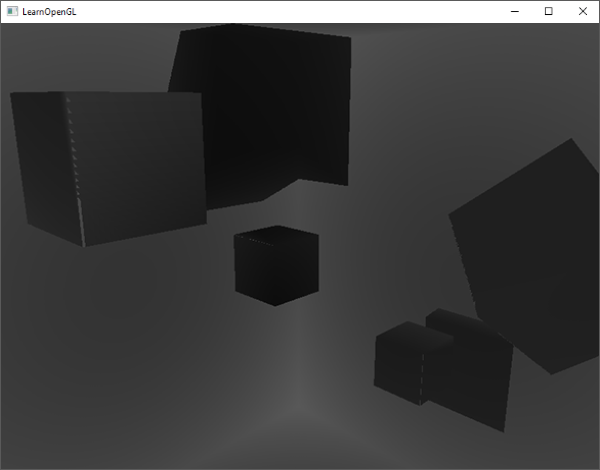
|
||||
|
||||
你可能也注意到了带阴影部分在墙外。如果看起来和这个差不多,你就知道深度cubemap生成的没错。否则你可能做错了什么,也许是closestDepth仍然还在0到far_plane的范围。
|
||||
|
||||
#### PCF
|
||||
|
||||
由于万向阴影贴图基于传统阴影映射的原则,它便也继承了由解析度产生的非真实感。如果你放大就会看到锯齿边了。PCF或称Percentage-closer filtering允许我们通过对fragment位置周围过滤多个样本,并对结果平均化。
|
||||
|
||||
如果我们用和前面教程同样的那个简单的PCF过滤器,并加入第三个维度,就是这样的:
|
||||
|
||||
```c+++
|
||||
float shadow = 0.0;
|
||||
float bias = 0.05;
|
||||
float samples = 4.0;
|
||||
float offset = 0.1;
|
||||
for(float x = -offset; x < offset; x += offset / (samples * 0.5))
|
||||
{
|
||||
for(float y = -offset; y < offset; y += offset / (samples * 0.5))
|
||||
{
|
||||
for(float z = -offset; z < offset; z += offset / (samples * 0.5))
|
||||
{
|
||||
float closestDepth = texture(depthMap, fragToLight + vec3(x, y, z)).r;
|
||||
closestDepth *= far_plane; // Undo mapping [0;1]
|
||||
if(currentDepth - bias > closestDepth)
|
||||
shadow += 1.0;
|
||||
}
|
||||
}
|
||||
}
|
||||
shadow /= (samples * samples * samples);
|
||||
```
|
||||
|
||||
这段代码和我们传统的阴影映射没有多少不同。这里我们根据样本的数量动态计算了纹理偏移量,我们在三个轴向采样三次,最后对子样本进行平均化。
|
||||
|
||||
现在阴影看起来更加柔和平滑了,由此得到更加真实的效果:
|
||||
|
||||
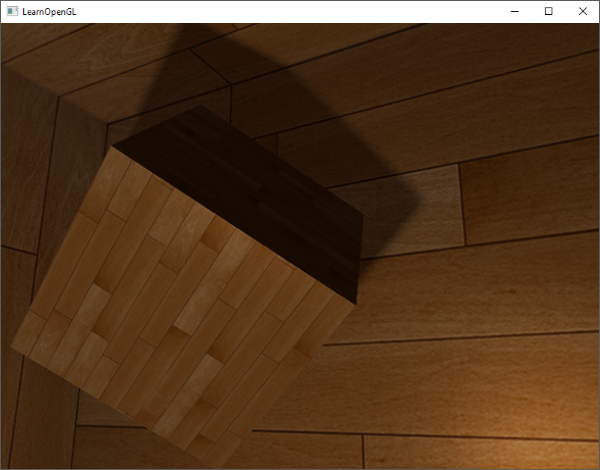
|
||||
|
||||
然而,samples设置为4.0,每个fragment我们会得到总共64个样本,这太多了!
|
||||
|
||||
大多数这些样本都是多余的,它们在原始方向向量近处采样,不如在采样方向向量的垂直方向进行采样更有意义。可是,没有(简单的)方式能够指出哪一个子方向是多余的,这就难了。有个技巧可以使用,用一个偏移量方向数组,它们差不多都是分开的,每一个指向完全不同的方向,剔除彼此接近的那些子方向。下面就是一个有着20个偏移方向的数组:
|
||||
|
||||
```c++
|
||||
vec3 sampleOffsetDirections[20] = vec3[]
|
||||
(
|
||||
vec3( 1, 1, 1), vec3( 1, -1, 1), vec3(-1, -1, 1), vec3(-1, 1, 1),
|
||||
vec3( 1, 1, -1), vec3( 1, -1, -1), vec3(-1, -1, -1), vec3(-1, 1, -1),
|
||||
vec3( 1, 1, 0), vec3( 1, -1, 0), vec3(-1, -1, 0), vec3(-1, 1, 0),
|
||||
vec3( 1, 0, 1), vec3(-1, 0, 1), vec3( 1, 0, -1), vec3(-1, 0, -1),
|
||||
vec3( 0, 1, 1), vec3( 0, -1, 1), vec3( 0, -1, -1), vec3( 0, 1, -1)
|
||||
);
|
||||
```
|
||||
|
||||
然后我们把PCF算法与从sampleOffsetDirections得到的样本数量进行适配,使用它们从cubemap里采样。这么做的好处是与之前的PCF算法相比,我们需要的样本数量变少了。
|
||||
|
||||
```c++
|
||||
float shadow = 0.0;
|
||||
float bias = 0.15;
|
||||
int samples = 20;
|
||||
float viewDistance = length(viewPos - fragPos);
|
||||
float diskRadius = 0.05;
|
||||
for(int i = 0; i < samples; ++i)
|
||||
{
|
||||
float closestDepth = texture(depthMap, fragToLight + sampleOffsetDirections[i] * diskRadius).r;
|
||||
closestDepth *= far_plane; // Undo mapping [0;1]
|
||||
if(currentDepth - bias > closestDepth)
|
||||
shadow += 1.0;
|
||||
}
|
||||
shadow /= float(samples);
|
||||
```
|
||||
|
||||
这里我们把一个偏移量添加到指定的diskRadius中,它在fragToLight方向向量周围从cubemap里采样。
|
||||
|
||||
另一个在这里可以应用的有意思的技巧是,我们可以基于观察者里一个fragment的距离来改变diskRadius;这样我们就能根据观察者的距离来增加偏移半径了,当距离更远的时候阴影更柔和,更近了就更锐利。
|
||||
|
||||
```c++
|
||||
float diskRadius = (1.0 + (viewDistance / far_plane)) / 25.0;
|
||||
```
|
||||
|
||||
PCF算法的结果如果没有变得更好,也是非常不错的,这是柔和的阴影效果:
|
||||
|
||||
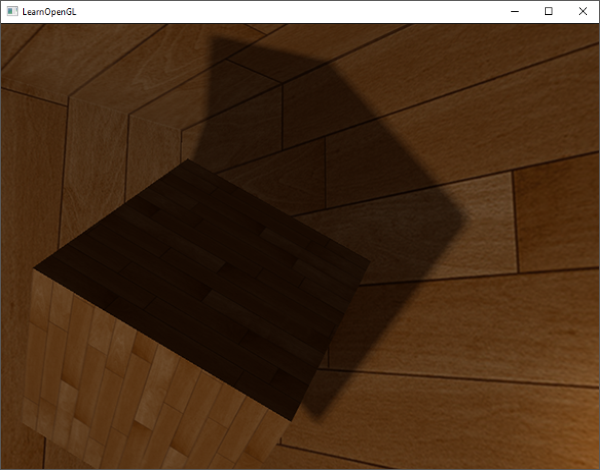
|
||||
|
||||
当然了,我们添加到每个样本的bias(偏移)高度依赖于上下文,总是要根据场景进行微调的。试试这些值,看看怎样影响了场景。
|
||||
这里是最终版本的顶点和像素着色器。
|
||||
|
||||
我还要提醒一下使用几何着色器来生成深度贴图不会一定比每个面渲染场景6次更快。使用几何着色器有它自己的性能局限,在第一个阶段使用它可能获得更好的性能表现。这取决于环境的类型,以及特定的显卡驱动等等,所以如果你很关心性能,就要确保对两种方法有大致了解,然后选择对你场景来说更高效的那个。我个人还是喜欢使用几何着色器来进行阴影映射,原因很简单,因为它们使用起来更简单。
|
||||
|
||||
|
||||
|
||||
### 附加资源
|
||||
|
||||
[Shadow Mapping for point light sources in OpenGL](http://www.sunandblackcat.com/tipFullView.php?l=eng&topicid=36):sunandblackcat的万向阴影映射教程。
|
||||
|
||||
[Multipass Shadow Mapping With Point Lights](http://ogldev.atspace.co.uk/www/tutorial43/tutorial43.html):ogldev的万向阴影映射教程。
|
||||
|
||||
[Omni-directional Shadows](http://www.cg.tuwien.ac.at/~husky/RTR/OmnidirShadows-whyCaps.pdf):Peter Houska的关于万向阴影映射的一组很好的ppt。
|
||||
0
05 Advanced Lighting/03 Shadows/03 CMS.md
Normal file
0
05 Advanced Lighting/03 Shadows/03 CMS.md
Normal file
481
05 Advanced Lighting/04 Shadow Mapping.md
Normal file
481
05 Advanced Lighting/04 Shadow Mapping.md
Normal file
@@ -0,0 +1,481 @@
|
||||
本文作者JoeyDeVries,由Django翻译自[http://learnopengl.com](http://learnopengl.com)
|
||||
|
||||
## 点光源阴影(Point Shadows)
|
||||
|
||||
上个教程我们学到了如何使用阴影映射技术创建动态阴影。效果不错,但它只适合定向光,因为阴影只是在单一定向光源下生成的。所以它也叫定向阴影映射,深度(阴影)贴图生成自定向光的视角。
|
||||
|
||||
!!! Important
|
||||
|
||||
本节我们的焦点是在各种方向生成动态阴影。这个技术可以适用于点光源,生成所有方向上的阴影。
|
||||
|
||||
这个技术叫做点光阴影,过去的名字是万向阴影贴图(omnidirectional shadow maps)技术。
|
||||
|
||||
本节代码基于前面的阴影映射教程,所以如果你对传统阴影映射不熟悉,还是建议先读一读阴影映射教程。
|
||||
算法和定向阴影映射差不多:我们从光的透视图生成一个深度贴图,基于当前fragment位置来对深度贴图采样,然后用储存的深度值和每个fragment进行对比,看看它是否在阴影中。定向阴影映射和万向阴影映射的主要不同在于深度贴图的使用上。
|
||||
|
||||
对于深度贴图,我们需要从一个点光源的所有渲染场景,普通2D深度贴图不能工作;如果我们使用cubemap会怎样?因为cubemap可以储存6个面的环境数据,它可以将整个场景渲染到cubemap的每个面上,把它们当作点光源四周的深度值来采样。
|
||||
|
||||

|
||||
|
||||
生成后的深度cubemap被传递到光照像素着色器,它会用一个方向向量来采样cubemap,从而得到当前的fragment的深度(从光的透视图)。大部分复杂的事情已经在阴影映射教程中讨论过了。算法只是在深度cubemap生成上稍微复杂一点。
|
||||
|
||||
#### 生成深度cubemap
|
||||
|
||||
为创建一个光周围的深度值的cubemap,我们必须渲染场景6次:每次一个面。显然渲染场景6次需要6个不同的视图矩阵,每次把一个不同的cubemap面附加到帧缓冲对象上。这看起来是这样的:
|
||||
|
||||
```c++
|
||||
for(int i = 0; i < 6; i++)
|
||||
{
|
||||
GLuint face = GL_TEXTURE_CUBE_MAP_POSITIVE_X + i;
|
||||
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, face, depthCubemap, 0);
|
||||
BindViewMatrix(lightViewMatrices[i]);
|
||||
RenderScene();
|
||||
}
|
||||
```
|
||||
|
||||
这会很耗费性能因为一个深度贴图下需要进行很多渲染调用。这个教程中我们将转而使用另外的一个小技巧来做这件事,几何着色器允许我们使用一次渲染过程来建立深度cubemap。
|
||||
|
||||
首先,我们需要创建一个cubemap:
|
||||
|
||||
```c++
|
||||
GLuint depthCubemap;
|
||||
glGenTextures(1, &depthCubemap);
|
||||
```
|
||||
|
||||
然后生成cubemap的每个面,将它们作为2D深度值纹理图像:
|
||||
|
||||
```c++
|
||||
const GLuint SHADOW_WIDTH = 1024, SHADOW_HEIGHT = 1024;
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, depthCubemap);
|
||||
for (GLuint i = 0; i < 6; ++i)
|
||||
glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0, GL_DEPTH_COMPONENT,
|
||||
SHADOW_WIDTH, SHADOW_HEIGHT, 0, GL_DEPTH_COMPONENT, GL_FLOAT, NULL);
|
||||
```
|
||||
|
||||
不要忘记设置合适的纹理参数:
|
||||
|
||||
```c++
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
|
||||
```
|
||||
|
||||
正常情况下,我们把cubemap纹理的一个面附加到帧缓冲对象上,渲染场景6次,每次将帧缓冲的深度缓冲目标改成不同cubemap面。由于我们将使用一个几何着色器,它允许我们把所有面在一个过程渲染,我们可以使用glFramebufferTexture直接把cubemap附加成帧缓冲的深度附件:
|
||||
|
||||
```c++
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
|
||||
glFramebufferTexture(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, depthCubemap, 0);
|
||||
glDrawBuffer(GL_NONE);
|
||||
glReadBuffer(GL_NONE);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
```
|
||||
|
||||
还要记得调用glDrawBuffer和glReadBuffer:当生成一个深度cubemap时我们只关心深度值,所以我们必须显式告诉OpenGL这个帧缓冲对象不会渲染到一个颜色缓冲里。
|
||||
|
||||
万向阴影贴图有两个渲染阶段:首先我们生成深度贴图,然后我们正常使用深度贴图渲染,在场景中创建阴影。帧缓冲对象和cubemap的处理看起是这样的:
|
||||
|
||||
```c++
|
||||
// 1. first render to depth cubemap
|
||||
glViewport(0, 0, SHADOW_WIDTH, SHADOW_HEIGHT);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO);
|
||||
glClear(GL_DEPTH_BUFFER_BIT);
|
||||
ConfigureShaderAndMatrices();
|
||||
RenderScene();
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
// 2. then render scene as normal with shadow mapping (using depth cubemap)
|
||||
glViewport(0, 0, SCR_WIDTH, SCR_HEIGHT);
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
|
||||
ConfigureShaderAndMatrices();
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, depthCubemap);
|
||||
RenderScene();
|
||||
```
|
||||
|
||||
这个过程和默认的阴影映射一样,尽管这次我们渲染和使用的是一个cubemap深度纹理,而不是2D深度纹理。在我们实际开始从光的视角的所有方向渲染场景之前,我们先得计算出合适的变换矩阵。
|
||||
|
||||
### 光空间的变换
|
||||
|
||||
设置了帧缓冲和cubemap,我们需要一些方法来讲场景的所有几何体变换到6个光的方向中相应的光空间。与阴影映射教程类似,我们将需要一个光空间的变换矩阵T,但是这次是每个面都有一个。
|
||||
|
||||
每个光空间的变换矩阵包含了投影和视图矩阵。对于投影矩阵来说,我们将使用一个透视投影矩阵;光源代表一个空间中的点,所以透视投影矩阵更有意义。每个光空间变换矩阵使用同样的投影矩阵:
|
||||
|
||||
```c++
|
||||
GLfloat aspect = (GLfloat)SHADOW_WIDTH/(GLfloat)SHADOW_HEIGHT;
|
||||
GLfloat near = 1.0f;
|
||||
GLfloat far = 25.0f;
|
||||
glm::mat4 shadowProj = glm::perspective(90.0f, aspect, near, far);
|
||||
```
|
||||
|
||||
非常重要的一点是,这里glm::perspective的视野参数,设置为90度。90度我们才能保证视野足够大到可以合适地填满cubemap的一个面,cubemap的所有面都能与其他面在边缘对齐。
|
||||
|
||||
因为投影矩阵在每个方向上并不会改变,我们可以在6个变换矩阵中重复使用。我们要为每个方向提供一个不同的视图矩阵。用glm::lookAt创建6个观察方向,每个都按顺序注视着cubemap的的一个方向:右、左、上、下、近、远:
|
||||
|
||||
```c++
|
||||
std::vector<glm::mat4> shadowTransforms;
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(1.0,0.0,0.0), glm::vec3(0.0,-1.0,0.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(-1.0,0.0,0.0), glm::vec3(0.0,-1.0,0.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,1.0,0.0), glm::vec3(0.0,0.0,1.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,-1.0,0.0), glm::vec3(0.0,0.0,-1.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,0.0,1.0), glm::vec3(0.0,-1.0,0.0));
|
||||
shadowTransforms.push_back(shadowProj *
|
||||
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,0.0,-1.0), glm::vec3(0.0,-1.0,0.0));
|
||||
```
|
||||
|
||||
这里我们创建了6个视图矩阵,把它们乘以投影矩阵,来得到6个不同的光空间变换矩阵。glm::lookAt的target参数是它注视的cubemap的面的一个方向。
|
||||
|
||||
这些变换矩阵发送到着色器渲染到cubemap里。
|
||||
|
||||
|
||||
|
||||
### 深度着色器
|
||||
|
||||
为了把值渲染到深度cubemap,我们将需要3个着色器:顶点和像素着色器,以及一个它们之间的几何着色器。
|
||||
|
||||
几何着色器是负责将所有世界空间的顶点变换到6个不同的光空间的着色器。因此顶点着色器简单地将顶点变换到世界空间,然后直接发送到几何着色器:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
|
||||
uniform mat4 model;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = model * vec4(position, 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
紧接着几何着色器以3个三角形的顶点作为输入,它还有一个光空间变换矩阵的uniform数组。几何着色器接下来会负责将顶点变换到光空间;这里它开始变得有趣了。
|
||||
|
||||
几何着色器有一个内建变量叫做gl_Layer,它指定发散出基本图形送到cubemap的哪个面。当不管它时,几何着色器就会像往常一样把它的基本图形发送到输送管道的下一阶段,但当我们更新这个变量就能控制每个基本图形将渲染到cubemap的哪一个面。当然这只有当我们有了一个附加到激活的帧缓冲的cubemap纹理才有效:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (triangles) in;
|
||||
layout (triangle_strip, max_vertices=18) out;
|
||||
|
||||
uniform mat4 shadowMatrices[6];
|
||||
|
||||
out vec4 FragPos; // FragPos from GS (output per emitvertex)
|
||||
|
||||
void main()
|
||||
{
|
||||
for(int face = 0; face < 6; ++face)
|
||||
{
|
||||
gl_Layer = face; // built-in variable that specifies to which face we render.
|
||||
for(int i = 0; i < 3; ++i) // for each triangle's vertices
|
||||
{
|
||||
FragPos = gl_in[i].gl_Position;
|
||||
gl_Position = shadowMatrices[face] * FragPos;
|
||||
EmitVertex();
|
||||
}
|
||||
EndPrimitive();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
几何着色器相对简单。我们输入一个三角形,输出总共6个三角形(6*3顶点,所以总共18个顶点)。在main函数中,我们遍历cubemap的6个面,我们每个面指定为一个输出面,把这个面的interger(整数)存到gl_Layer。然后,我们通过把面的光空间变换矩阵乘以FragPos,将每个世界空间顶点变换到相关的光空间,生成每个三角形。注意,我们还要将最后的FragPos变量发送给像素着色器,我们需要计算一个深度值。
|
||||
|
||||
上个教程,我们使用的是一个空的像素着色器,让OpenGL配置深度贴图的深度值。这次我们将计算自己的深度,这个深度就是每个fragment位置和光源位置之间的线性距离。计算自己的深度值使得之后的阴影计算更加直观。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
in vec4 FragPos;
|
||||
|
||||
uniform vec3 lightPos;
|
||||
uniform float far_plane;
|
||||
|
||||
void main()
|
||||
{
|
||||
// get distance between fragment and light source
|
||||
float lightDistance = length(FragPos.xyz - lightPos);
|
||||
|
||||
// map to [0;1] range by dividing by far_plane
|
||||
lightDistance = lightDistance / far_plane;
|
||||
|
||||
// Write this as modified depth
|
||||
gl_FragDepth = gl_FragCoord.z;
|
||||
}
|
||||
```
|
||||
|
||||
像素着色器将来自几何着色器的FragPos、光的位置向量和视锥的远平面值作为输入。这里我们把fragment和光源之间的距离,映射到0到1的范围,把它写入为fragment的深度值。
|
||||
|
||||
使用这些着色器渲染场景,cubemap附加的帧缓冲对象激活以后,你会得到一个完全填充的深度cubemap,以便于进行第二阶段的阴影计算。
|
||||
|
||||
### 万向阴影贴图
|
||||
|
||||
所有事情都做好了,是时候来渲染万向阴影了。这个过程和定向阴影映射教程相似,尽管这次我们绑定的深度贴图是一个cubemap,而不是2D纹理,并且将光的投影的远平面发送给了着色器。
|
||||
|
||||
```c++
|
||||
glViewport(0, 0, SCR_WIDTH, SCR_HEIGHT);
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
|
||||
shader.Use();
|
||||
// ... send uniforms to shader (including light's far_plane value)
|
||||
glActiveTexture(GL_TEXTURE0);
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, depthCubemap);
|
||||
// ... bind other textures
|
||||
RenderScene();
|
||||
```
|
||||
|
||||
这里的renderScene函数在一个大立方体房间中渲染一些立方体,它们散落在大立方体各处,光源在场景中央。
|
||||
|
||||
顶点着色器和像素着色器和原来的阴影映射着色器大部分都一样:不同之处是在光空间中像素着色器不再需要一个fragment位置,现在我们可以使用一个方向向量采样深度值。
|
||||
|
||||
因为这个顶点着色器不再需要将他的位置向量变换到光空间,所以我们可以去掉FragPosLightSpace变量:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
layout (location = 1) in vec3 normal;
|
||||
layout (location = 2) in vec2 texCoords;
|
||||
|
||||
out vec2 TexCoords;
|
||||
|
||||
out VS_OUT {
|
||||
vec3 FragPos;
|
||||
vec3 Normal;
|
||||
vec2 TexCoords;
|
||||
} vs_out;
|
||||
|
||||
uniform mat4 projection;
|
||||
uniform mat4 view;
|
||||
uniform mat4 model;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0f);
|
||||
vs_out.FragPos = vec3(model * vec4(position, 1.0));
|
||||
vs_out.Normal = transpose(inverse(mat3(model))) * normal;
|
||||
vs_out.TexCoords = texCoords;
|
||||
}
|
||||
```
|
||||
|
||||
片段着色器的Blinn-Phong光照代码和我们之前阴影相乘的结尾部分一样:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 FragColor;
|
||||
|
||||
in VS_OUT {
|
||||
vec3 FragPos;
|
||||
vec3 Normal;
|
||||
vec2 TexCoords;
|
||||
} fs_in;
|
||||
|
||||
uniform sampler2D diffuseTexture;
|
||||
uniform samplerCube depthMap;
|
||||
|
||||
uniform vec3 lightPos;
|
||||
uniform vec3 viewPos;
|
||||
|
||||
uniform float far_plane;
|
||||
|
||||
float ShadowCalculation(vec3 fragPos)
|
||||
{
|
||||
[...]
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
vec3 color = texture(diffuseTexture, fs_in.TexCoords).rgb;
|
||||
vec3 normal = normalize(fs_in.Normal);
|
||||
vec3 lightColor = vec3(0.3);
|
||||
// Ambient
|
||||
vec3 ambient = 0.3 * color;
|
||||
// Diffuse
|
||||
vec3 lightDir = normalize(lightPos - fs_in.FragPos);
|
||||
float diff = max(dot(lightDir, normal), 0.0);
|
||||
vec3 diffuse = diff * lightColor;
|
||||
// Specular
|
||||
vec3 viewDir = normalize(viewPos - fs_in.FragPos);
|
||||
vec3 reflectDir = reflect(-lightDir, normal);
|
||||
float spec = 0.0;
|
||||
vec3 halfwayDir = normalize(lightDir + viewDir);
|
||||
spec = pow(max(dot(normal, halfwayDir), 0.0), 64.0);
|
||||
vec3 specular = spec * lightColor;
|
||||
// Calculate shadow
|
||||
float shadow = ShadowCalculation(fs_in.FragPos);
|
||||
vec3 lighting = (ambient + (1.0 - shadow) * (diffuse + specular)) * color;
|
||||
|
||||
FragColor = vec4(lighting, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
有一些细微的不同:光照代码一样,但我们现在有了一个uniform变量samplerCube,shadowCalculation函数用fragment的位置作为它的参数,取代了光空间的fragment位置。我们现在还要引入光的视锥的远平面值,后面我们会需要它。像素着色器的最后,我们计算出阴影元素,当fragment在阴影中时它是1.0,不在阴影中时是0.0。我们使用计算出来的阴影元素去影响光照的diffuse和specular元素。
|
||||
|
||||
在ShadowCalculation函数中有很多不同之处,现在是从cubemap中进行采样,不再使用2D纹理了。我们来一步一步的讨论一下的它的内容。
|
||||
|
||||
我们需要做的第一件事是获取cubemap的森都。你可能已经从教程的cubemap部分想到,我们已经将深度储存为fragment和光位置之间的距离了;我们这里采用相似的处理方式:
|
||||
|
||||
```c++
|
||||
float ShadowCalculation(vec3 fragPos)
|
||||
{
|
||||
vec3 fragToLight = fragPos - lightPos;
|
||||
float closestDepth = texture(depthMap, fragToLight).r;
|
||||
}
|
||||
```
|
||||
|
||||
在这里,我们得到了fragment的位置与光的位置之间的不同的向量,使用这个向量作为一个方向向量去对cubemap进行采样。方向向量不需要是单位向量,所以无需对它进行标准化。最后的closestDepth是光源和它最接近的可见fragment之间的标准化的深度值。
|
||||
|
||||
closestDepth值现在在0到1的范围内了,所以我们先将其转换会0到far_plane的范围,这需要把他乘以far_plane:
|
||||
|
||||
```c++
|
||||
closestDepth *= far_plane;
|
||||
```
|
||||
|
||||
下一步我们获取当前fragment和光源之间的深度值,我们可以简单的使用fragToLight的长度来获取它,这取决于我们如何计算cubemap中的深度值:
|
||||
|
||||
```c++
|
||||
float currentDepth = length(fragToLight);
|
||||
```
|
||||
|
||||
返回的是和closestDepth范围相同的深度值。
|
||||
|
||||
现在我们可以将两个深度值对比一下,看看哪一个更接近,以此决定当前的fragment是否在阴影当中。我们还要包含一个阴影偏移,所以才能避免阴影失真,这在前面教程中已经讨论过了。
|
||||
|
||||
```c++
|
||||
float bias = 0.05;
|
||||
float shadow = currentDepth - bias > closestDepth ? 1.0 : 0.0;
|
||||
```
|
||||
|
||||
完整的ShadowCalculation现在变成了这样:
|
||||
|
||||
```c++
|
||||
float ShadowCalculation(vec3 fragPos)
|
||||
{
|
||||
// Get vector between fragment position and light position
|
||||
vec3 fragToLight = fragPos - lightPos;
|
||||
// Use the light to fragment vector to sample from the depth map
|
||||
float closestDepth = texture(depthMap, fragToLight).r;
|
||||
// It is currently in linear range between [0,1]. Re-transform back to original value
|
||||
closestDepth *= far_plane;
|
||||
// Now get current linear depth as the length between the fragment and light position
|
||||
float currentDepth = length(fragToLight);
|
||||
// Now test for shadows
|
||||
float bias = 0.05;
|
||||
float shadow = currentDepth - bias > closestDepth ? 1.0 : 0.0;
|
||||
|
||||
return shadow;
|
||||
}
|
||||
```
|
||||
|
||||
有了这些着色器,我们已经能得到非常好的阴影效果了,这次从一个点光源所有周围方向上都有阴影。有一个位于场景中心的点光源,看起来会像这样:
|
||||
|
||||

|
||||
|
||||
你可以从这里找到这个[demo的源码](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/point_shadows)、[顶点](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/point_shadows&type=vertex)和[片段](http://www.learnopengl.com/code_viewer.php?code=advanced-lighting/point_shadows&type=fragment)着色器。
|
||||
|
||||
#### 把cubemap深度缓冲显示出来
|
||||
|
||||
如果你想我一样第一次并没有做对,那么就要进行调试排错,将深度贴图显示出来以检查其是否正确。因为我们不再用2D深度贴图纹理,深度贴图的显示不会那么显而易见。
|
||||
|
||||
一个简单的把深度缓冲显示出来的技巧是,在ShadowCalculation函数中计算标准化的closestDepth变量,把变量显示为:
|
||||
|
||||
```c++
|
||||
FragColor = vec4(vec3(closestDepth / far_plane), 1.0);
|
||||
```
|
||||
|
||||
结果是一个灰度场景,每个颜色代表着场景的线性深度值:
|
||||
|
||||

|
||||
|
||||
你可能也注意到了带阴影部分在墙外。如果看起来和这个差不多,你就知道深度cubemap生成的没错。否则你可能做错了什么,也许是closestDepth仍然还在0到far_plane的范围。
|
||||
|
||||
#### PCF
|
||||
|
||||
由于万向阴影贴图基于传统阴影映射的原则,它便也继承了由解析度产生的非真实感。如果你放大就会看到锯齿边了。PCF或称Percentage-closer filtering允许我们通过对fragment位置周围过滤多个样本,并对结果平均化。
|
||||
|
||||
如果我们用和前面教程同样的那个简单的PCF过滤器,并加入第三个维度,就是这样的:
|
||||
|
||||
```c+++
|
||||
float shadow = 0.0;
|
||||
float bias = 0.05;
|
||||
float samples = 4.0;
|
||||
float offset = 0.1;
|
||||
for(float x = -offset; x < offset; x += offset / (samples * 0.5))
|
||||
{
|
||||
for(float y = -offset; y < offset; y += offset / (samples * 0.5))
|
||||
{
|
||||
for(float z = -offset; z < offset; z += offset / (samples * 0.5))
|
||||
{
|
||||
float closestDepth = texture(depthMap, fragToLight + vec3(x, y, z)).r;
|
||||
closestDepth *= far_plane; // Undo mapping [0;1]
|
||||
if(currentDepth - bias > closestDepth)
|
||||
shadow += 1.0;
|
||||
}
|
||||
}
|
||||
}
|
||||
shadow /= (samples * samples * samples);
|
||||
```
|
||||
|
||||
这段代码和我们传统的阴影映射没有多少不同。这里我们根据样本的数量动态计算了纹理偏移量,我们在三个轴向采样三次,最后对子样本进行平均化。
|
||||
|
||||
现在阴影看起来更加柔和平滑了,由此得到更加真实的效果:
|
||||
|
||||

|
||||
|
||||
然而,samples设置为4.0,每个fragment我们会得到总共64个样本,这太多了!
|
||||
|
||||
大多数这些样本都是多余的,它们在原始方向向量近处采样,不如在采样方向向量的垂直方向进行采样更有意义。可是,没有(简单的)方式能够指出哪一个子方向是多余的,这就难了。有个技巧可以使用,用一个偏移量方向数组,它们差不多都是分开的,每一个指向完全不同的方向,剔除彼此接近的那些子方向。下面就是一个有着20个偏移方向的数组:
|
||||
|
||||
```c++
|
||||
vec3 sampleOffsetDirections[20] = vec3[]
|
||||
(
|
||||
vec3( 1, 1, 1), vec3( 1, -1, 1), vec3(-1, -1, 1), vec3(-1, 1, 1),
|
||||
vec3( 1, 1, -1), vec3( 1, -1, -1), vec3(-1, -1, -1), vec3(-1, 1, -1),
|
||||
vec3( 1, 1, 0), vec3( 1, -1, 0), vec3(-1, -1, 0), vec3(-1, 1, 0),
|
||||
vec3( 1, 0, 1), vec3(-1, 0, 1), vec3( 1, 0, -1), vec3(-1, 0, -1),
|
||||
vec3( 0, 1, 1), vec3( 0, -1, 1), vec3( 0, -1, -1), vec3( 0, 1, -1)
|
||||
);
|
||||
```
|
||||
|
||||
然后我们把PCF算法与从sampleOffsetDirections得到的样本数量进行适配,使用它们从cubemap里采样。这么做的好处是与之前的PCF算法相比,我们需要的样本数量变少了。
|
||||
|
||||
```c++
|
||||
float shadow = 0.0;
|
||||
float bias = 0.15;
|
||||
int samples = 20;
|
||||
float viewDistance = length(viewPos - fragPos);
|
||||
float diskRadius = 0.05;
|
||||
for(int i = 0; i < samples; ++i)
|
||||
{
|
||||
float closestDepth = texture(depthMap, fragToLight + sampleOffsetDirections[i] * diskRadius).r;
|
||||
closestDepth *= far_plane; // Undo mapping [0;1]
|
||||
if(currentDepth - bias > closestDepth)
|
||||
shadow += 1.0;
|
||||
}
|
||||
shadow /= float(samples);
|
||||
```
|
||||
|
||||
这里我们把一个偏移量添加到指定的diskRadius中,它在fragToLight方向向量周围从cubemap里采样。
|
||||
|
||||
另一个在这里可以应用的有意思的技巧是,我们可以基于观察者里一个fragment的距离来改变diskRadius;这样我们就能根据观察者的距离来增加偏移半径了,当距离更远的时候阴影更柔和,更近了就更锐利。
|
||||
|
||||
```c++
|
||||
float diskRadius = (1.0 + (viewDistance / far_plane)) / 25.0;
|
||||
```
|
||||
|
||||
PCF算法的结果如果没有变得更好,也是非常不错的,这是柔和的阴影效果:
|
||||
|
||||

|
||||
|
||||
当然了,我们添加到每个样本的bias(偏移)高度依赖于上下文,总是要根据场景进行微调的。试试这些值,看看怎样影响了场景。
|
||||
这里是最终版本的顶点和像素着色器。
|
||||
|
||||
我还要提醒一下使用几何着色器来生成深度贴图不会一定比每个面渲染场景6次更快。使用几何着色器有它自己的性能局限,在第一个阶段使用它可能获得更好的性能表现。这取决于环境的类型,以及特定的显卡驱动等等,所以如果你很关心性能,就要确保对两种方法有大致了解,然后选择对你场景来说更高效的那个。我个人还是喜欢使用几何着色器来进行阴影映射,原因很简单,因为它们使用起来更简单。
|
||||
|
||||
|
||||
|
||||
### 附加资源
|
||||
|
||||
[Shadow Mapping for point light sources in OpenGL](http://www.sunandblackcat.com/tipFullView.php?l=eng&topicid=36):sunandblackcat的万向阴影映射教程。
|
||||
|
||||
[Multipass Shadow Mapping With Point Lights](http://ogldev.atspace.co.uk/www/tutorial43/tutorial43.html):ogldev的万向阴影映射教程。
|
||||
|
||||
[Omni-directional Shadows](http://www.cg.tuwien.ac.at/~husky/RTR/OmnidirShadows-whyCaps.pdf):Peter Houska的关于万向阴影映射的一组很好的ppt。
|
||||
BIN
img/05_01_01.png
Normal file
BIN
img/05_01_01.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 18 KiB |
Reference in New Issue
Block a user