mirror of
https://github.com/LearnOpenGL-CN/LearnOpenGL-CN.git
synced 2025-12-02 05:55:57 +08:00
校对 04/10
This commit is contained in:
@@ -1,31 +1,35 @@
|
||||
## 实例化(Instancing)
|
||||
# 实例化(Instancing)
|
||||
|
||||
本文作者JoeyDeVries,由Django翻译自http://learnopengl.com
|
||||
原文 | [Instancing](http://learnopengl.com/#!Advanced-OpenGL/Instancing)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
比如说你有一个有许多模型的场景,而这些模型的顶点数据都一样,只是进行了不同的世界变换。想象一下,有一个场景中充满了草叶:每根草都是几个三角形组成的。你可能需要绘制很多的草叶,最终一次渲染循环中就肯能有成千上万个草需要绘制了。因为每个草叶只是由几个三角形组成,绘制一个几乎是即刻完成,但是数量巨大以后,执行起来就很慢了。
|
||||
假如你有一个有许多模型的场景,而这些模型的顶点数据都一样,只是进行了不同的世界空间的变换。想象一下,有一个场景中充满了草叶:每根草都是几个三角形组成的。你可能需要绘制很多的草叶,最终一次渲染循环中就肯能有成千上万个草需要绘制了。因为每个草叶只是由几个三角形组成,绘制一个几乎是即刻完成,但是数量巨大以后,执行起来就很慢了。
|
||||
|
||||
如果我们渲染这样多的物体的时候,也许代码会写成这样:
|
||||
|
||||
```c++
|
||||
for(GLuint i = 0; i < amount_of_models_to_draw; i++)
|
||||
{
|
||||
DoSomePreparations(); // bind VAO, bind Textures, set uniforms etc.
|
||||
DoSomePreparations(); //在这里绑定VAO、绑定纹理、设置uniform变量等
|
||||
glDrawArrays(GL_TRIANGLES, 0, amount_of_vertices);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
像这样绘制出你模型的其他实例,多次绘制之后,很快将达到一个瓶颈。和渲染真实的顶点相比,告诉GPU使用像glDrawArrays或glDrawElements这样的函数,去渲染你的顶点数据,会明显降低执行效率,这是因为OpenGL比在它可以绘制你的顶点数据之前必须做一些不必要的准备工作(比如告诉GPU从哪个缓冲读取数据,以及在哪里找到顶点属性,所有这些都会是CPU到GPU的总线变慢)。所以即使渲染顶点超快,给你的GPU下达这样的渲染命令却未必。
|
||||
像这样绘制出你模型的其他实例,多次绘制之后,很快将达到一个瓶颈,这是因为你`glDrawArrays`或`glDrawElements`这样的函数(Draw call)过多。这样渲染顶点数据,会明显降低执行效率,这是因为OpenGL在它可以绘制你的顶点数据之前必须做一些准备工作(比如告诉GPU从哪个缓冲读取数据,以及在哪里找到顶点属性,所有这些都会使CPU到GPU的总线变慢)。所以即使渲染顶点超快,而多次给你的GPU下达这样的渲染命令却未必。
|
||||
|
||||
如果我们能够将数据一次发送给GPU,就会更方便,然后告诉OpenGL使用一个绘制函数,将这些数据绘制为多个物体。下面进入实例化。
|
||||
如果我们能够将数据一次发送给GPU,就会更方便,然后告诉OpenGL使用一个绘制函数,将这些数据绘制为多个物体。这就是我们将要展开讨论的**实例化(instancing)**。
|
||||
|
||||
实例化是一种只调用一次渲染函数却能绘制出很多物体的技术,它节省渲染一个物体时了从CPU到GPU的通信时间;而且只需做一次即可。要使用实例化渲染,我们必须将glDrawArrays和glDrawElements各自改为glDrawArraysInstanced和glDrawElementsInstanced。这些用于实例化的函数版本需要设置一个额外的参数,叫做实例化数量(instance count),它设置我们打算渲染实例的数量。这样我们就只需要把所有需要的数据发送给GPU一次就行了,然后告诉GPU它该如何使用一个函数来绘制所有这些实例。
|
||||
**实例化(instancing)**是一种只调用一次渲染函数却能绘制出很多物体的技术,它节省渲染物体时从CPU到GPU的通信时间,而且只需做一次即可。要使用实例化渲染,我们必须将`glDrawArrays`和`glDrawElements`各自改为`glDrawArraysInstanced`和`glDrawElementsInstanced`。这些用于实例化的函数版本需要设置一个额外的参数,叫做**实例数量(instance count)**,它设置我们打算渲染实例的数量。这样我们就只需要把所有需要的数据发送给GPU一次就行了,然后告诉GPU它该如何使用一个函数来绘制所有这些实例。
|
||||
|
||||
就其本身而言,这个函数用处不大。渲染同一个物体一千次对我们来说没用,因为每个渲染出的物体不仅相同而且还在同一个位置;我们只能看到一个物体!出于这个原因GLSL在着色器中嵌入了另一个内建变量,叫做gl_InstanceID。
|
||||
就其本身而言,这个函数用处不大。渲染同一个物体一千次对我们来说没用,因为每个渲染出的物体不仅相同而且还在同一个位置;我们只能看到一个物体!出于这个原因GLSL在着色器中嵌入了另一个内建变量,叫做**`gl_InstanceID`**。
|
||||
|
||||
当调用任何一个实例化绘制函数的时候,gl_InstanceID在每个实例渲染时都会增加1,它的初值是0。如果我们渲染43个实例,那么在顶点着色器gl_InstanceID的值最后就是42。每个实例都拥有唯一的值意味着我们可以索引到一个位置数组,并将每个实例摆放在世界空间的不同的位置上。
|
||||
在通过实例化绘制时,`gl_InstanceID`的初值是0,它在每个实例渲染时都会增加1。如果我们渲染43个实例,那么在顶点着色器`gl_InstanceID`的值最后就是42。每个实例都拥有唯一的值意味着我们可以索引到一个位置数组,并将每个实例摆放在世界空间的不同的位置上。
|
||||
|
||||
我们调用一个渲染函数,在标准化设备坐标中绘制一百个2D四边形来看看实例化绘制的效果是怎样的。通过对一个储存着100个偏移量向量的索引,我们像每个实例四边形添加一个偏移量。最后,窗口被排列精美的四边形网格填满:
|
||||
我们调用一个实例化渲染函数,在标准化设备坐标中绘制一百个2D四边形来看看实例化绘制的效果是怎样的。通过对一个储存着100个偏移量向量的索引,我们为每个实例四边形添加一个偏移量。最后,窗口被排列精美的四边形网格填满:
|
||||
|
||||
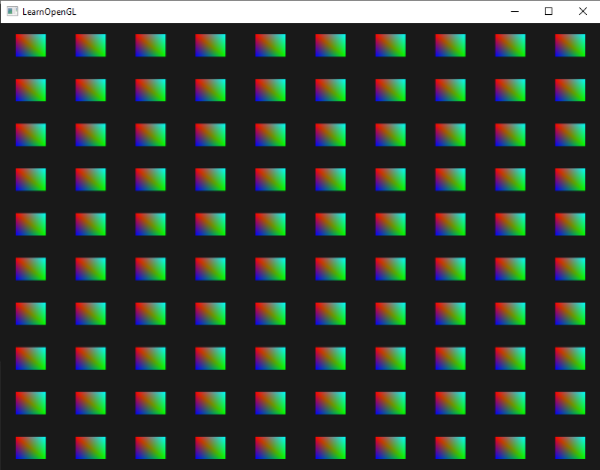
|
||||
|
||||
@@ -33,7 +37,7 @@ for(GLuint i = 0; i < amount_of_models_to_draw; i++)
|
||||
|
||||
```c++
|
||||
GLfloat quadVertices[] = {
|
||||
// Positions // Colors
|
||||
// ---位置--- ------颜色-------
|
||||
-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,
|
||||
0.05f, -0.05f, 0.0f, 1.0f, 0.0f,
|
||||
-0.05f, -0.05f, 0.0f, 0.0f, 1.0f,
|
||||
@@ -76,7 +80,7 @@ void main()
|
||||
}
|
||||
```
|
||||
|
||||
这里我们定义了一个uniform数组,叫offset,它包含100个偏移量向量。在顶点着色器里,我们接收一个对应着当前实例的偏移量,这是通过使用gl_InstanceID来索引offsets得到的。如果我们使用实例化绘制100个四边形,使用这个顶点着色器,我们就能得到100位于不同位置的四边形。
|
||||
这里我们定义了一个uniform数组,叫`offsets`,它包含100个偏移量向量。在顶点着色器里,我们接收一个对应着当前实例的偏移量,这是通过使用 `gl_InstanceID`来索引offsets得到的。如果我们使用实例化绘制100个四边形,使用这个顶点着色器,我们就能得到100位于不同位置的四边形。
|
||||
|
||||
我们一定要设置偏移位置,在游戏循环之前我们用一个嵌套for循环计算出它来:
|
||||
|
||||
@@ -96,7 +100,7 @@ for(GLint y = -10; y < 10; y += 2)
|
||||
}
|
||||
```
|
||||
|
||||
这里我们创建100个平移向量,它包含着10×10格子所有位置。除了生成translations数组外,我们还需要把数据发送到顶点着色器的uniform数组:
|
||||
这里我们创建100个平移向量,它包含着10×10格子所有位置。除了生成`translations`数组外,我们还需要把这些位移数据发送到顶点着色器的uniform数组:
|
||||
|
||||
```c++
|
||||
shader.Use();
|
||||
@@ -111,9 +115,9 @@ for(GLuint i = 0; i < 100; i++)
|
||||
}
|
||||
```
|
||||
|
||||
这一小段代码中,我们将for循环计数器i变为string,接着就能动态创建一个为请求的uniform的location创建一个location字符串。将offsets数组中的每个条目,我们都设置为相应的平移向量。
|
||||
这一小段代码中,我们将for循环计数器i变为string,接着就能动态创建一个为请求的uniform的`location`创建一个`location`字符串。将offsets数组中的每个条目,我们都设置为相应的平移向量。
|
||||
|
||||
现在所有的准备工作都结束了,我们可以开始渲染四边形了。用实例化渲染来绘制四边形,我们需要调用glDrawArraysInstanced或glDrawElementsInstanced,由于我们使用的不是索引绘制缓冲,所以我们用的是glDrawArrays对应的那个版本:
|
||||
现在所有的准备工作都结束了,我们可以开始渲染四边形了。用实例化渲染来绘制四边形,我们需要调用`glDrawArraysInstanced`或`glDrawElementsInstanced`,由于我们使用的不是索引绘制缓冲,所以我们用的是`glDrawArrays`对应的那个版本`glDrawArraysInstanced`:
|
||||
|
||||
```c++
|
||||
glBindVertexArray(quadVAO);
|
||||
@@ -121,15 +125,15 @@ glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);
|
||||
glBindVertexArray(0);
|
||||
```
|
||||
|
||||
glDrawArraysInstanced的参数和glDrawArrays一样,除了最后一个参数设置了我们打算绘制实例的数量。我们想展示100个四边形,它们以10×10网格形式展现,所以这儿就是100.运行代码,你会得到100个相似的有色四边形。
|
||||
`glDrawArraysInstanced`的参数和`glDrawArrays`一样,除了最后一个参数设置了我们打算绘制实例的数量。我们想展示100个四边形,它们以10×10网格形式展现,所以这儿就是100.运行代码,你会得到100个相似的有色四边形。
|
||||
|
||||
#### 实例数组(instanced arrays)
|
||||
## 实例化数组(instanced arrays)
|
||||
|
||||
在这种特定条件下,前面的实现很好,但是当我们有100个实例的时候(这很正常),最终我们将碰到uniform数据数量的上线。为避免这个问题另一个可替代方案是实例数组,它使用顶点属性来定义(这样就允许我们使用更多的数据了),当顶点着色器渲染一个新实例时它才会被更新。
|
||||
在这种特定条件下,前面的实现很好,但是当我们有100个实例的时候(这很正常),最终我们将碰到uniform数据数量的上线。为避免这个问题另一个可替代方案是实例化数组,它使用顶点属性来定义,这样就允许我们使用更多的数据了,当顶点着色器渲染一个新实例时它才会被更新。
|
||||
|
||||
使用顶点属性,每次运行顶点着色器都将让GLSL获取到下个顶点属性集合,它们属于当前顶点。当把顶点属性定义为实例数组时,顶点着色器只更新每个实例的顶点属性的内容而不是顶点的内容。这使我们在每个顶点数据上使用标准顶点属性,用实例数组来储存唯一的实例数据。
|
||||
|
||||
为了展示一个实例数组的例子,我们将采用前面的例子,把偏移uniform表示为一个实例数组。我们不得不增加另一个顶点属性,来更新顶点着色器。
|
||||
为了展示一个实例化数组的例子,我们将采用前面的例子,把偏移uniform表示为一个实例数组。我们不得不增加另一个顶点属性,来更新顶点着色器。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
@@ -146,9 +150,9 @@ void main()
|
||||
}
|
||||
```
|
||||
|
||||
我们不再使用gl_InstanceID,可以直接用offset属性,不用先在一个大uniform数组里进行索引。
|
||||
我们不再使用`gl_InstanceID`,可以直接用`offset`属性,不用先在一个大uniform数组里进行索引。
|
||||
|
||||
因为一个实例数组实际上就是一个和位置和颜色一样的顶点属性,我们还需要把它的内容储存为一个顶点缓冲对象里,并把它配置为一个属性指针。我们首先将平移变换数组贮存到一个新的缓冲对象上:
|
||||
因为一个实例化数组实际上就是一个和位置和颜色一样的顶点属性,我们还需要把它的内容储存为一个顶点缓冲对象里,并把它配置为一个属性指针。我们首先将平移变换数组贮存到一个新的缓冲对象上:
|
||||
|
||||
```c++
|
||||
GLuint instanceVBO;
|
||||
@@ -168,15 +172,15 @@ glBindBuffer(GL_ARRAY_BUFFER, 0);
|
||||
glVertexAttribDivisor(2, 1);
|
||||
```
|
||||
|
||||
代码中有意思的地方是,最后一行,我们调用了glVertexAttribDivisor。这个函数告诉OpenGL什么时候去更新顶点属性的内容到下个元素。它的第一个参数是提到的顶点属性,第二个参数是属性除数(attribute divisor)。默认属性除数是0,告诉OpenGL在顶点着色器的每次迭代更新顶点属性的内容。把这个属性设置为1,我们就是告诉OpenGL我们打算在开始渲染一个新的实例的时候更新顶点属性的内容。设置为2代表我们每2个实例更新内容,依此类推。把属性除数设置为1,我们可以高效地告诉OpenGL,location是2的顶点属性是一个实例数组(instanced array)。
|
||||
代码中有意思的地方是,最后一行,我们调用了 **`glVertexAttribDivisor`**。这个函数告诉OpenGL什么时候去更新顶点属性的内容到下个元素。它的第一个参数是提到的顶点属性,第二个参数是属性除数(attribute divisor)。默认属性除数是0,告诉OpenGL在顶点着色器的每次迭代更新顶点属性的内容。把这个属性设置为1,我们就是告诉OpenGL我们打算在开始渲染一个新的实例的时候更新顶点属性的内容。设置为2代表我们每2个实例更新内容,依此类推。把属性除数设置为1,我们可以高效地告诉OpenGL,location是2的顶点属性是一个实例数组(instanced array)。
|
||||
|
||||
如果我们现在再次使用glDrawArraysInstanced渲染四边形,我们会得到下面的输出:
|
||||
如果我们现在再次使用`glDrawArraysInstanced`渲染四边形,我们会得到下面的输出:
|
||||
|
||||

|
||||
|
||||
和前面的一样,但这次是使用实例数组实现的,它使我们为绘制实例向顶点着色器传递更多的数据(内存允许我们存多少就能存多少)。
|
||||
|
||||
你还可以使用gl_InstanceID从右上向左下缩小每个四边形。
|
||||
你还可以使`用gl_InstanceID`从右上向左下缩小每个四边形。
|
||||
|
||||
```c++
|
||||
void main()
|
||||
@@ -187,21 +191,21 @@ void main()
|
||||
}
|
||||
```
|
||||
|
||||
结果是第一个实例的四边形被绘制的非常小,随着绘制实例的增加,gl_InstanceID越来越接近100,这样更多的四边形会更接近它们原来的大小。这是一种很好的将gl_InstanceID与实例数组结合使用的法则:
|
||||
结果是第一个实例的四边形被绘制的非常小,随着绘制实例的增加,`gl_InstanceID`越来越接近100,这样更多的四边形会更接近它们原来的大小。这是一种很好的将`gl_InstanceID`与实例数组结合使用的法则:
|
||||
|
||||
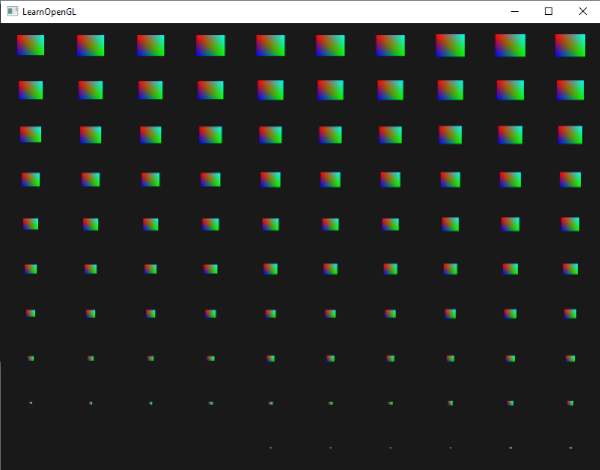
|
||||
|
||||
如果你仍然不确定实例渲染如何工作,或者想看看上面的代码是如何组合起来的,你可以在这里找到应用的源码。
|
||||
如果你仍然不确定实例渲染如何工作,或者想看看上面的代码是如何组合起来的,你可以在[这里找到应用的源码](http://learnopengl.com/code_viewer.php?code=advanced/instancing_quads)。
|
||||
|
||||
这些例子不是实例的好例子,不过挺有意思的。它们可以让你对实例的工作方式有一个概括的理解,但是当绘制拥有极大数量的相同物体的时候,它极其有用,现在我们还没有展示呢。出于这个原因,我们将咋接下来的部分进入太空来看看实例渲染的威力。
|
||||
这些例子不是实例的好例子,不过挺有意思的。它们可以让你对实例的工作方式有一个概括的理解,但是当绘制拥有极大数量的相同物体的时候,它极其有用,现在我们还没有展示呢。出于这个原因,我们将在接下来的部分进入太空来看看实例渲染的威力。
|
||||
|
||||
#### 小行星带
|
||||
### 小行星带
|
||||
|
||||
想象一下,在一个场景中有一个很大的行星,行星周围有一圈小行星带。这样一个小行星大可能包含成千上万的石块,对于大多数显卡来说几乎是难以完成的渲染任务。这个场景对于实例渲染来说却不再话下,由于所有小行星可以使用一个模型来表示。每个小行星使用一个变换矩阵就是一个经过少量变化的独一无二的小行星了。
|
||||
|
||||
为了展示实例渲染的影响,我们先不使用实例渲染,来渲染一个小行星围绕行星飞行的场景。这个场景的大天体可以从这里下载,此外要把小行星放在合适的位置上。小行星可以从这里下载。
|
||||
为了展示实例渲染的影响,我们先不使用实例渲染,来渲染一个小行星围绕行星飞行的场景。这个场景的大天体可以[从这里下载](http://learnopengl.com/data/models/planet.rar),此外要把小行星放在合适的位置上。小行星可以[从这里下载](http://learnopengl.com/data/models/rock.rar)。
|
||||
|
||||
为了得到我们理想中的效果,我们将为每个小行星生成一个变换矩阵,作为它们的模型矩阵。变换矩阵先将小行星平移到行星带上,我们还要添加一个随机位移值来作为偏移量,这样才能使行星带更自然。接着我们应用一个随机缩放,以及一个随机旋转向量。最后,变换矩阵就会将小行星变换到猩猩的周围,同时使它们更自然,每个行星都有别于其他的。
|
||||
为了得到我们理想中的效果,我们将为每个小行星生成一个变换矩阵,作为它们的模型矩阵。变换矩阵先将小行星平移到行星带上,我们还要添加一个随机位移值来作为偏移量,这样才能使行星带更自然。接着我们应用一个随机缩放,以及一个随机旋转向量。最后,变换矩阵就会将小行星变换到行星的周围,同时使它们更自然,每个行星都有别于其他的。
|
||||
|
||||
```c++
|
||||
GLuint amount = 1000;
|
||||
@@ -238,7 +242,7 @@ for(GLuint i = 0; i < amount; i++)
|
||||
加载完天体和小行星模型后,编译着色器,渲染代码是这样的:
|
||||
|
||||
```c++
|
||||
// Draw Planet
|
||||
// 绘制行星
|
||||
shader.Use();
|
||||
glm::mat4 model;
|
||||
model = glm::translate(model, glm::vec3(0.0f, -5.0f, 0.0f));
|
||||
@@ -246,7 +250,7 @@ model = glm::scale(model, glm::vec3(4.0f, 4.0f, 4.0f));
|
||||
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));
|
||||
planet.Draw(shader);
|
||||
|
||||
// Draw Asteroid circle
|
||||
// 绘制石头
|
||||
for(GLuint i = 0; i < amount; i++)
|
||||
{
|
||||
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(modelMatrices[i]));
|
||||
@@ -260,7 +264,7 @@ for(GLuint i = 0; i < amount; i++)
|
||||
|
||||
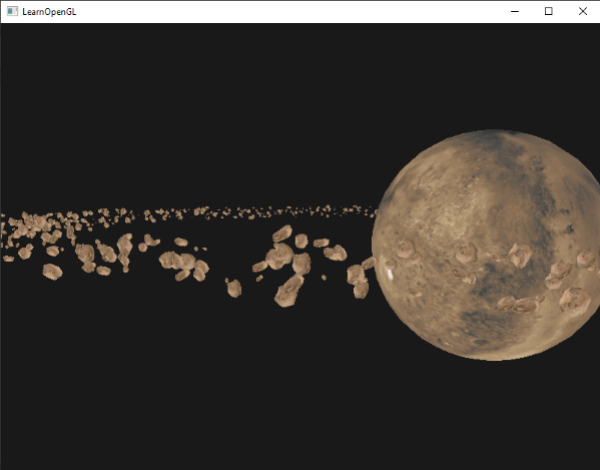
|
||||
|
||||
这个场景包含1001次渲染函数调用,每帧渲染1000个小行星模型。你可以在这里找到场景的源码。
|
||||
这个场景包含1001次渲染函数调用,每帧渲染1000个小行星模型。你可以在这里找到[场景的源码](http://learnopengl.com/code_viewer.php?code=advanced/instancing_asteroids_normal),以及[顶点](http://learnopengl.com/code_viewer.php?code=advanced/instancing&type=vertex)和[片段](http://learnopengl.com/code_viewer.php?code=advanced/instancing&type=fragment)着色器。
|
||||
|
||||
当我们开始增加数量的时候,很快就会注意到帧数的下降,而且下降的厉害。当我们设置为2000的时候,场景慢得已经难以移动了。
|
||||
|
||||
@@ -320,7 +324,7 @@ for(GLuint i = 0; i < rock.meshes.size(); i++)
|
||||
|
||||
要注意的是我们将Mesh的VAO变量声明为一个public(公有)变量,而不是一个private(私有)变量,所以我们可以获取它的顶点数组对象。这不是最干净的方案,但这能较好的适应本教程。若没有这点hack,代码就干净了。我们声明了OpenGL该如何为每个矩阵的顶点属性的缓冲进行解释,每个顶点属性都是一个实例数组。
|
||||
|
||||
下一步我们再次获得网格的VAO,这次使用glDrawElementsInstanced进行绘制:
|
||||
下一步我们再次获得网格的VAO,这次使用`glDrawElementsInstanced`进行绘制:
|
||||
|
||||
```c++
|
||||
// Draw meteorites
|
||||
@@ -339,7 +343,7 @@ for(GLuint i = 0; i < rock.meshes.size(); i++)
|
||||
|
||||
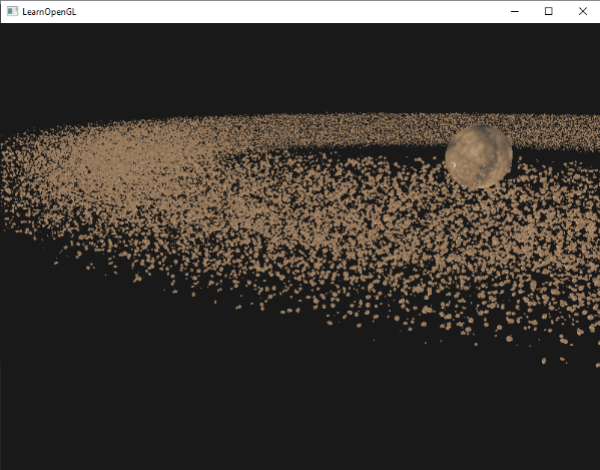
|
||||
|
||||
上图渲染了十万小行星,半径为150.0f,偏移等于25.0f。你可以在这里找到这个演示实例渲染的源码。
|
||||
上图渲染了十万小行星,半径为150.0f,偏移等于25.0f。你可以在这里找到这个演示实例渲染的[源码](http://learnopengl.com/code_viewer.php?code=advanced/instancing_asteroids_instanced)。
|
||||
|
||||
!!! Important
|
||||
|
||||
|
||||
Reference in New Issue
Block a user