mirror of
https://github.com/LearnOpenGL-CN/LearnOpenGL-CN.git
synced 2025-12-02 05:55:57 +08:00
Revert all the changes since 851f9ec
This commit is contained in:
195
04 Advanced OpenGL/01 Depth testing.md
Normal file
195
04 Advanced OpenGL/01 Depth testing.md
Normal file
@@ -0,0 +1,195 @@
|
||||
# 深度测试(Depth testing)
|
||||
|
||||
原文 | [Depth testing](http://learnopengl.com/#!Advanced-OpenGL/Depth-testing)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
在[坐标系的教程](http://learnopengl-cn.readthedocs.org/zh/latest/01%20Getting%20started/08%20Coordinate%20Systems/)中我们呈现了一个3D容器,使用**深度缓冲**,以防止被其他面遮挡的面渲染到前面。在本教程中我们将细致地讨论被深度缓冲区(depth-buffer或z-buffer)所存储的**深度值**以及它是如何确定一个片段是否被其他片段遮挡。
|
||||
|
||||
**深度缓冲**就像**颜色缓冲**(存储所有的片段颜色:视觉输出)那样存储每个片段的信息,(通常) 和颜色缓冲区有相同的宽度和高度。深度缓冲由窗口系统自动创建并将其深度值存储为 16、 24 或 32 位浮点数。在大多数系统中深度缓冲区为24位。
|
||||
|
||||
当深度测试启用的时候, OpenGL 测试深度缓冲区内的深度值。OpenGL 执行深度测试的时候,如果此测试通过,深度缓冲内的值将被设为新的深度值。如果深度测试失败,则丢弃该片段。
|
||||
|
||||
深度测试在片段着色器运行之后(并且模板测试运行之后,我们将在[接下来](http://www.learnopengl.com/#!Advanced-OpenGL/Stencil-testing)的教程中讨论)在屏幕空间中执行的。屏幕空间坐标直接有关的视区,由OpenGL的`glViewport`函数给定,并且可以通过GLSL的片段着色器中内置的 `gl_FragCoord`变量访问。`gl_FragCoord` 的 X 和 y 表示该片段的屏幕空间坐标 ((0,0) 在左下角)。`gl_FragCoord` 还包含一个 z 坐标,它包含了片段的实际深度值。此 z 坐标值是与深度缓冲区的内容进行比较的值。
|
||||
|
||||
!!! Important
|
||||
|
||||
现在大多数 GPU 都支持一种称为提前深度测试(Early depth testing)的硬件功能。提前深度测试允许深度测试在片段着色器之前运行。明确一个片段永远不会可见的 (它是其它物体的后面) 我们可以更早地放弃该片段。
|
||||
|
||||
片段着色器通常是相当费时的所以我们应该尽量避免运行它们。对片段着色器提前深度测试一个限制是,你不应该写入片段的深度值。如果片段着色器将写入其深度值,提前深度测试是不可能的,OpenGL不能事先知道深度值。
|
||||
|
||||
深度测试默认是关闭的,要启用深度测试的话,我们需要用`GL_DEPTH_TEST`选项来打开它:
|
||||
|
||||
```c++
|
||||
glEnable(GL_DEPTH_TEST);
|
||||
```
|
||||
|
||||
一旦启用深度测试,如果片段通过深度测试,OpenGL自动在深度缓冲区存储片段的 z 值,如果深度测试失败,那么相应地丢弃该片段。如果启用深度测试,那么在每个渲染之前还应使用`GL_DEPTH_BUFFER_BIT`清除深度缓冲区,否则深度缓冲区将保留上一次进行深度测试时所写的深度值
|
||||
|
||||
```c++
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
|
||||
```
|
||||
|
||||
在某些情况下我们需要进行深度测试并相应地丢弃片段,但我们不希望更新深度缓冲区,基本上,可以使用一个只读的深度缓冲区;OpenGL允许我们通过将其深度掩码设置为`GL_FALSE`禁用深度缓冲区写入:
|
||||
|
||||
```c++
|
||||
glDepthMask(GL_FALSE);
|
||||
```
|
||||
|
||||
注意这只在深度测试被启用的时候有效。
|
||||
|
||||
## 深度测试函数
|
||||
|
||||
OpenGL 允许我们修改它深度测试使用的比较运算符(comparison operators)。这样我们能够控制OpenGL通过或丢弃碎片和如何更新深度缓冲区。我们可以通过调用`glDepthFunc`来设置比较运算符 (或叫做深度函数(depth function)):
|
||||
|
||||
```c++
|
||||
glDepthFunc(GL_LESS);
|
||||
```
|
||||
|
||||
该函数接受在下表中列出的几个比较运算符:
|
||||
|
||||
运算符|描述
|
||||
----------|------------------
|
||||
GL_ALWAYS |永远通过测试
|
||||
GL_NEVER |永远不通过测试
|
||||
GL_LESS |在片段深度值小于缓冲区的深度时通过测试
|
||||
GL_EQUAL |在片段深度值等于缓冲区的深度时通过测试
|
||||
GL_LEQUAL |在片段深度值小于等于缓冲区的深度时通过测试
|
||||
GL_GREATER |在片段深度值大于缓冲区的深度时通过测试
|
||||
GL_NOTEQUAL|在片段深度值不等于缓冲区的深度时通过测试
|
||||
GL_GEQUAL |在片段深度值大于等于缓冲区的深度时通过测试
|
||||
|
||||
默认情况下使用`GL_LESS`,这将丢弃深度值高于或等于当前深度缓冲区的值的片段。
|
||||
|
||||
让我们看看改变深度函数对输出的影响。我们将使用新鲜的代码安装程序显示一个没有灯光的有纹理地板上的两个有纹理的立方体。你可以在这里找到源代码和其着色器代码。
|
||||
|
||||
代码中我们将深度函数设为`GL_ALWAYS`:
|
||||
|
||||
```c++
|
||||
glDepthFunc(GL_ALWAYS);
|
||||
```
|
||||
|
||||
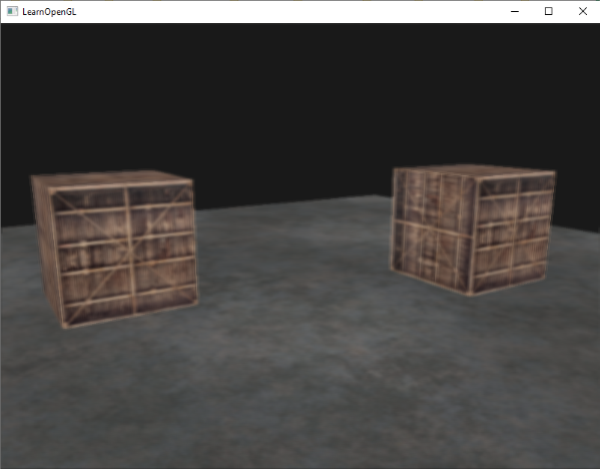
这和我们没有启用深度测试得到了相同的行为。深度测试只是简单地通过,所以这样最后绘制的片段就会呈现在之前绘制的片段前面,即使他们应该在前面。由于我们最后绘制地板平面,那么平面的片段会覆盖每个容器的片段:
|
||||
|
||||
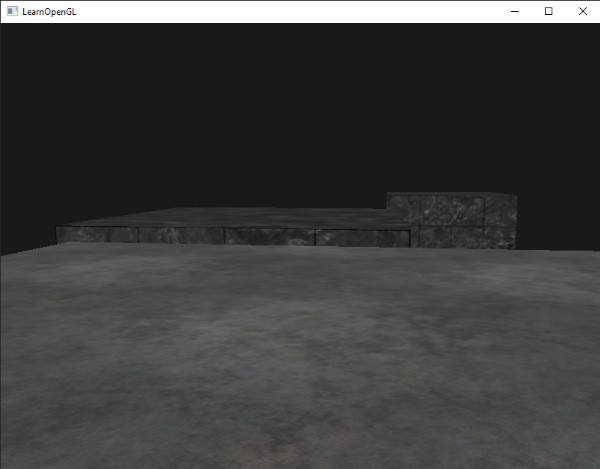
|
||||
|
||||
重新设置到`GL_LESS`给了我们曾经的场景:
|
||||
|
||||
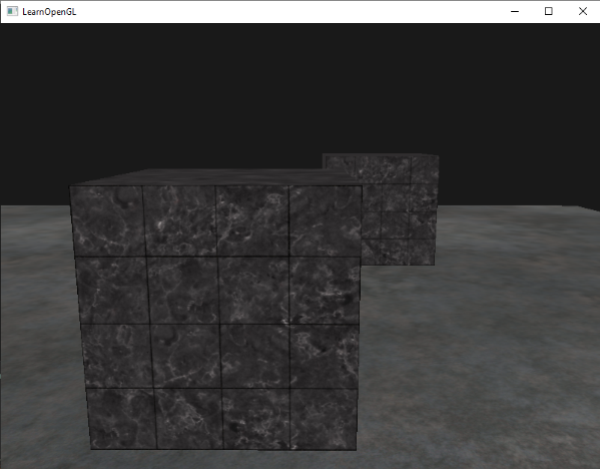
|
||||
|
||||
## 深度值精度
|
||||
|
||||
在深度缓冲区中包含深度值介于`0.0`和`1.0`之间,从观察者看到其内容与场景中的所有对象的 z 值进行了比较。这些视图空间中的 z 值可以在投影平头截体的近平面和远平面之间的任何值。我们因此需要一些方法来转换这些视图空间 z 值到 [0,1] 的范围内,方法之一就是线性将它们转换为 [0,1] 范围内。下面的 (线性) 方程把 z 值转换为 0.0 和 1.0 之间的值 :
|
||||
|
||||

|
||||
|
||||
这里far和near是我们用来提供到投影矩阵设置可见视图截锥的远近值 (见[坐标系](http://learnopengl-cn.readthedocs.org/zh/latest/01%20Getting%20started/08%20Coordinate%20Systems/))。方程带内锥截体的深度值 z,并将其转换到 [0,1] 范围。在下面的图给出 z 值和其相应的深度值的关系:
|
||||
|
||||
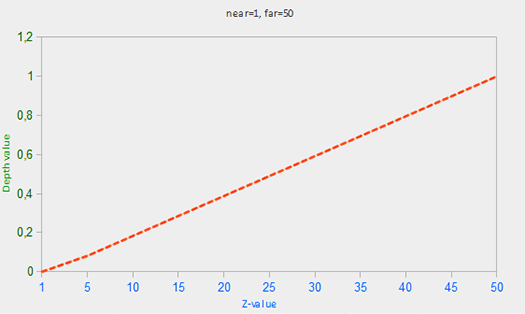
|
||||
|
||||
!!! Important
|
||||
|
||||
注意在物体接近近平面的时候,方程给出的深度值接近0.0,物体接近远平面时,方程给出的深度接近1.0。
|
||||
|
||||
然而,在实践中是几乎从来不使用这样的线性深度缓冲区。正确的投影特性的非线性深度方程是和1/z成正比的 。这样基本上做的是在z很近是的高精度和 z 很远的时候的低精度。用几秒钟想一想: 我们真的需要让1000单位远的物体和只有1单位远的物体的深度值有相同的精度吗?线性方程没有考虑这一点。
|
||||
|
||||
由于非线性函数是和 1/z 成正比,例如1.0 和 2.0 之间的 z 值,将变为 1.0 到 0.5之间, 这样在z非常小的时候给了我们很高的精度。50.0 和 100.0 之间的 Z 值将只占 2%的浮点数的精度,这正是我们想要的。这类方程,也需要近和远距离考虑,下面给出:
|
||||
|
||||

|
||||
|
||||
如果你不知道这个方程到底怎么回事也不必担心。要记住的重要一点是在深度缓冲区的值不是线性的屏幕空间 (它们在视图空间投影矩阵应用之前是线性)。值为 0.5 在深度缓冲区并不意味着该对象的 z 值是投影平头截体的中间;顶点的 z 值是实际上相当接近近平面!你可以看到 z 值和产生深度缓冲区的值在下列图中的非线性关系:
|
||||
|
||||
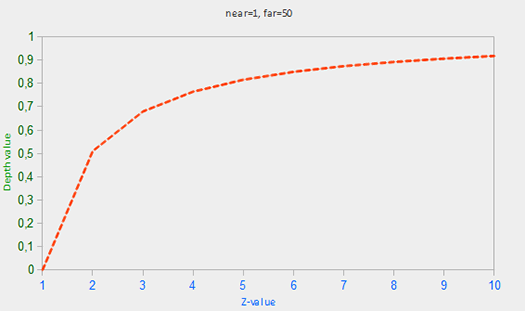
|
||||
|
||||
正如你所看到,一个附近的物体的小的 z 值因此给了我们很高的深度精度。变换 (从观察者的角度) 的 z 值的方程式被嵌入在投影矩阵,所以当我们变换顶点坐标从视图到裁剪,然后到非线性方程应用了的屏幕空间中。如果你好奇的投影矩阵究竟做了什么我建议阅读[这个文章](http://www.songho.ca/opengl/gl_projectionmatrix.html)。
|
||||
|
||||
接下来我们看看这个非线性的深度值。
|
||||
|
||||
### 深度缓冲区的可视化
|
||||
|
||||
我们知道在片段渲染器的内置`gl_FragCoord`向量的 z 值包含那个片段的深度值。如果我们要吧深度值作为颜色输出,那么我们可以在场景中显示的所有片段的深度值。我们可以返回基于片段的深度值的颜色向量:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
color = vec4(vec3(gl_FragCoord.z), 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
如果再次运行同一程序你可能会发现一切都是白的,它看起来像我们的深度值都是最大值 1.0。那么为什么没有深度值接近 0.0而发暗?
|
||||
|
||||
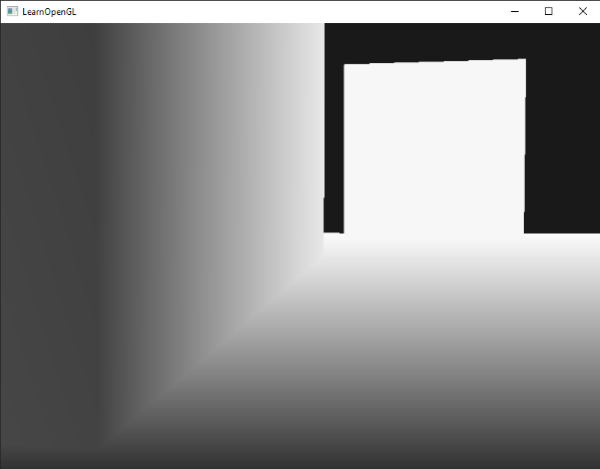
你可能还记得从上一节中的屏幕空间的深度值是非线性如他们在z很小的时候有很高的精度,,较大的 z 值有较低的精度。该片段的深度值会迅速增加,所以几乎所有顶点的深度值接近 1.0。如果我们小心的靠近物体,你最终可能会看到的色彩越来越暗,意味着它们的 z 值越来越小:
|
||||
|
||||
|
||||
|
||||
这清楚地表明深度值的非线性特性。近的物体相对远的物体对的深度值比对象较大的影响。只移动几英寸就能让暗色完全变亮。
|
||||
|
||||
但是我们可以让深度值变换回线性。要实现这一目标我们需要让点应用投影变换逆的逆变换,成为单独的深度值的过程。这意味着我们必须首先重新变换范围 [0,1] 中的深度值为单位化的设备坐标(normalized device coordinates)范围内 [-1,1] (裁剪空间(clip space))。然后,我们想要反转非线性方程 (等式2) 就像在投影矩阵做的那样并将此反转方程应用于所得到的深度值。然后,结果是一个线性的深度值。听起来能行对吗?
|
||||
|
||||
首先,我们需要并不太难的 NDC 深度值转换:
|
||||
|
||||
```c++
|
||||
float z = depth * 2.0 - 1.0;
|
||||
```
|
||||
|
||||
然后把我们所得到的 z 值应用逆转换来检索的线性深度值:
|
||||
|
||||
```c++
|
||||
float linearDepth = (2.0 * near) / (far + near - z * (far - near));
|
||||
```
|
||||
|
||||
注意此方程不是方程 2 的精确的逆方程。这个方程从投影矩阵中导出,可以从新使用等式2将他转换为非线性深度值。这个方程也会考虑使用[0,1] 而不是 [near,far]范围内的 z 值 。[math-heavy](http://www.songho.ca/opengl/gl_projectionmatrix.html)为感兴趣的读者阐述了大量详细的投影矩阵的知识;它还表明了方程是从哪里来的。
|
||||
|
||||
这不是从投影矩阵推导出的准确公式;这个方程是除以far的结果。深度值的范围一直到far,这作为一个介于 0.0 和 1.0 之间的颜色值并不合适。除以far的值把深度值映射到介于 0.0 和 1.0,更适合用于演示目的。
|
||||
|
||||
这个能够将屏幕空间的非线性深度值转变为线性深度值的完整的片段着色器如下所示:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
|
||||
out vec4 color;
|
||||
|
||||
float LinearizeDepth(float depth)
|
||||
{
|
||||
float near = 0.1;
|
||||
float far = 100.0;
|
||||
float z = depth * 2.0 - 1.0; // Back to NDC
|
||||
return (2.0 * near) / (far + near - z * (far - near));
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
float depth = LinearizeDepth(gl_FragCoord.z);
|
||||
color = vec4(vec3(depth), 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
如果现在运行该应用程序,我们得到在距离实际上线性的深度值。尝试移动现场周围看到深度值线性变化
|
||||
|
||||
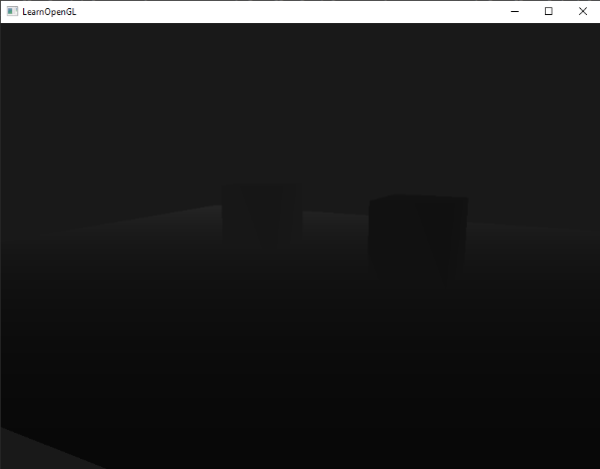。
|
||||
|
||||
颜色主要是黑色的因为深度值线性范围从 0.1 的近平面到 100 的远平面,那里离我们很远。其结果是,我们相对靠近近平面,从而得到较低 (较暗) 的深度值。
|
||||
|
||||
## 深度冲突
|
||||
|
||||
两个平面或三角形如此紧密相互平行深度缓冲区不具有足够的精度以至于无法得到哪一个靠前。结果是,这两个形状不断似乎切换顺序导致怪异出问题。这被称为深度冲突,因为它看上去像形状争夺顶靠前的位置。
|
||||
|
||||
我们到目前为止一直在使用的场景中有几个地方深度冲突很显眼。容器被置于确切高度地板被安置这意味着容器的底平面与地板平面共面。两个平面的深度值是相同的,因此深度测试也没有办法找出哪个是正确。
|
||||
|
||||
如果您移动摄像机到容器的里面,那么这个影响清晰可,容器的底部不断切换容器的平面和地板的平面:
|
||||
|
||||
|
||||
|
||||
深度冲突是深度缓冲区的普遍问题,当对象的距离越远一般越强(因为深度缓冲区在z值非常大的时候没有很高的精度)。深度冲突还无法完全避免,但有一般的几个技巧,将有助于减轻或完全防止深度冲突在你的场景中的出现:
|
||||
|
||||
### 防止深度冲突
|
||||
|
||||
第一个也是最重要的技巧是让物体之间不要离得太近,以至于他们的三角形重叠。通过在物体之间制造一点用户无法察觉到的偏移,可以完全解决深度冲突。在容器和平面的条件下,我们可以把容器像+y方向上略微移动。这微小的改变可能完全不被注意但是可以有效地减少或者完全解决深度冲突。然而这需要人工的干预每个物体,并进行彻底地测试,以确保这个场景的物体之间没有深度冲突。
|
||||
|
||||
另一个技巧是尽可能把近平面设置得远一些。前面我们讨论过越靠近近平面的位置精度越高。所以我们移动近平面远离观察者,我们可以在椎体内很有效的提高精度。然而把近平面移动的太远会导致近处的物体被裁剪掉。所以不断调整测试近平面的值,为你的场景找出最好的近平面的距离。
|
||||
|
||||
另外一个技巧是放弃一些性能来得到更高的深度值的精度。大多数的深度缓冲区都是24位。但现在显卡支持32位深度值,这让深度缓冲区的精度提高了一大节。所以牺牲一些性能你会得到更精确的深度测试,减少深度冲突。
|
||||
|
||||
我们已经讨论过的 3 个技术是最常见和容易实现消除深度冲突的技术。还有一些其他技术需要更多的工作,仍然不会完全消除深度冲突。深度冲突是一个常见的问题,但如果你将列举的技术适当结合你可能不会真的需要处理深度冲突。
|
||||
203
04 Advanced OpenGL/02 Stencil testing.md
Normal file
203
04 Advanced OpenGL/02 Stencil testing.md
Normal file
@@ -0,0 +1,203 @@
|
||||
# 模板测试(Stencil testing)
|
||||
|
||||
原文 | [Stencil testing](http://learnopengl.com/#!Advanced-OpenGL/Stencil-testing)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
当片段着色器处理完片段之后,**模板测试(stencil test)** 就开始执行了,和深度测试一样,它能丢弃一些片段。仍然保留下来的片段进入深度测试阶段,深度测试可能丢弃更多。模板测试基于另一个缓冲,这个缓冲叫做**模板缓冲(stencil buffer)**,我们被允许在渲染时更新它来获取有意思的效果。
|
||||
|
||||
模板缓冲中的模板值(stencil value)通常是8位的,因此每个片段(像素)共有256种不同的模板值(译注:8位就是1字节大小,因此和char的容量一样是256个不同值)。这样我们就能将这些模板值设置为我们链接的,然后在模板测试时根据这个模板值,我们就可以决定丢弃或保留它了。
|
||||
|
||||
!!! Important
|
||||
|
||||
每个窗口库都需要为你设置模板缓冲。GLFW自动做了这件事,所以你不必告诉GLFW去创建它,但是其他库可能没默认创建模板库,所以一定要查看你使用的库的文档。
|
||||
|
||||
下面是一个模板缓冲的简单例子:
|
||||
|
||||

|
||||
|
||||
模板缓冲先清空模板缓冲设置所有片段的模板值为0,然后开启矩形片段用1填充。场景中的模板值为1的那些片段才会被渲染(其他的都被丢弃)。
|
||||
|
||||
无论我们在渲染哪里的片段,模板缓冲操作都允许我们把模板缓冲设置为一个特定值。改变模板缓冲的内容实际上就是对模板缓冲进行写入。在同一次(或接下来的)渲染迭代我们可以读取这些值来决定丢弃还是保留这些片段。当使用模板缓冲的时候,你可以随心所欲,但是需要遵守下面的原则:
|
||||
|
||||
* 开启模板缓冲写入。
|
||||
* 渲染物体,更新模板缓冲。
|
||||
* 关闭模板缓冲写入。
|
||||
* 渲染(其他)物体,这次基于模板缓冲内容丢弃特定片段。
|
||||
|
||||
使用模板缓冲我们可以基于场景中已经绘制的片段,来决定是否丢弃特定的片段。
|
||||
|
||||
你可以开启`GL_STENCIL_TEST`来开启模板测试。接着所有渲染函数调用都会以这样或那样的方式影响到模板缓冲。
|
||||
|
||||
```c
|
||||
glEnable(GL_STENCIL_TEST);
|
||||
```
|
||||
要注意的是,像颜色和深度缓冲一样,在每次循环,你也得清空模板缓冲。
|
||||
|
||||
```c
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
|
||||
```
|
||||
|
||||
同时,和深度测试的`glDepthMask`函数一样,模板缓冲也有一个相似函数。`glStencilMask`允许我们给模板值设置一个**位遮罩(bitmask)**,它与模板值进行按位与(and)运算决定缓冲是否可写。默认设置的位遮罩都是1,这样就不会影响输出,但是如果我们设置为0x00,所有写入深度缓冲最后都是0。这和深度缓冲的`glDepthMask(GL_FALSE)`很类似:
|
||||
|
||||
```c++
|
||||
|
||||
// 0xFF == 0b11111111
|
||||
//此时,模板值与它进行按位与运算结果是模板值,模板缓冲可写
|
||||
glStencilMask(0xFF);
|
||||
|
||||
// 0x00 == 0b00000000 == 0
|
||||
//此时,模板值与它进行按位与运算结果是0,模板缓冲不可写
|
||||
glStencilMask(0x00);
|
||||
```
|
||||
|
||||
大多数情况你的模板遮罩(stencil mask)写为0x00或0xFF就行,但是最好知道有一个选项可以自定义位遮罩。
|
||||
|
||||
## 模板函数(stencil functions)
|
||||
|
||||
和深度测试一样,我们也有几个不同控制权,决定何时模板测试通过或失败以及它怎样影响模板缓冲。一共有两种函数可供我们使用去配置模板测试:`glStencilFunc`和`glStencilOp`。
|
||||
|
||||
`void glStencilFunc(GLenum func, GLint ref, GLuint mask)`函数有三个参数:
|
||||
|
||||
* **func**:设置模板测试操作。这个测试操作应用到已经储存的模板值和`glStencilFunc`的`ref`值上,可用的选项是:`GL_NEVER`、`GL_LEQUAL`、`GL_GREATER`、`GL_GEQUAL`、`GL_EQUAL`、`GL_NOTEQUAL`、`GL_ALWAYS`。它们的语义和深度缓冲的相似。
|
||||
* **ref**:指定模板测试的引用值。模板缓冲的内容会与这个值对比。
|
||||
* **mask**:指定一个遮罩,在模板测试对比引用值和储存的模板值前,对它们进行按位与(and)操作,初始设置为1。
|
||||
|
||||
在上面简单模板的例子里,方程应该设置为:
|
||||
|
||||
```c
|
||||
glStencilFunc(GL_EQUAL, 1, 0xFF)
|
||||
```
|
||||
|
||||
它会告诉OpenGL,无论何时,一个片段模板值等于(`GL_EQUAL`)引用值`1`,片段就能通过测试被绘制了,否则就会被丢弃。
|
||||
|
||||
但是`glStencilFunc`只描述了OpenGL对模板缓冲做什么,而不是描述我们如何更新缓冲。这就需要`glStencilOp`登场了。
|
||||
|
||||
`void glStencilOp(GLenum sfail, GLenum dpfail, GLenum dppass)`函数包含三个选项,我们可以指定每个选项的动作:
|
||||
|
||||
* **sfail**: 如果模板测试失败将采取的动作。
|
||||
* **dpfail**: 如果模板测试通过,但是深度测试失败时采取的动作。
|
||||
* **dppass**: 如果深度测试和模板测试都通过,将采取的动作。
|
||||
|
||||
每个选项都可以使用下列任何一个动作。
|
||||
|
||||
操作 | 描述
|
||||
---|---
|
||||
GL_KEEP | 保持现有的模板值
|
||||
GL_ZERO | 将模板值置为0
|
||||
GL_REPLACE | 将模板值设置为用`glStencilFunc`函数设置的**ref**值
|
||||
GL_INCR | 如果模板值不是最大值就将模板值+1
|
||||
GL_INCR_WRAP| 与`GL_INCR`一样将模板值+1,如果模板值已经是最大值则设为0
|
||||
GL_DECR | 如果模板值不是最小值就将模板值-1
|
||||
GL_DECR_WRAP| 与`GL_DECR`一样将模板值-1,如果模板值已经是最小值则设为最大值
|
||||
GL_INVERT | Bitwise inverts the current stencil buffer value.
|
||||
|
||||
`glStencilOp`函数默认设置为 (GL_KEEP, GL_KEEP, GL_KEEP) ,所以任何测试的任何结果,模板缓冲都会保留它的值。默认行为不会更新模板缓冲,所以如果你想写入模板缓冲的话,你必须像任意选项指定至少一个不同的动作。
|
||||
|
||||
使用`glStencilFunc`和`glStencilOp`,我们就可以指定在什么时候以及我们打算怎么样去更新模板缓冲了,我们也可以指定何时让测试通过或不通过。什么时候片段会被抛弃。
|
||||
|
||||
## 物体轮廓
|
||||
|
||||
看了前面的部分你未必能理解模板测试是如何工作的,所以我们会展示一个用模板测试实现的一个特别的和有用的功能,叫做物体轮廓(object outlining)。
|
||||
|
||||

|
||||
|
||||
物体轮廓就像它的名字所描述的那样,它能够给每个(或一个)物体创建一个有颜色的边。在策略游戏中当你打算选择一个单位的时候它特别有用。给物体加上轮廓的步骤如下:
|
||||
|
||||
1. 在绘制物体前,把模板方程设置为`GL_ALWAYS`,用1更新物体将被渲染的片段。
|
||||
2. 渲染物体,写入模板缓冲。
|
||||
3. 关闭模板写入和深度测试。
|
||||
4. 每个物体放大一点点。
|
||||
5. 使用一个不同的片段着色器用来输出一个纯颜色。
|
||||
6. 再次绘制物体,但只是当它们的片段的模板值不为1时才进行。
|
||||
7. 开启模板写入和深度测试。
|
||||
|
||||
这个过程将每个物体的片段模板缓冲设置为1,当我们绘制边框的时候,我们基本上绘制的是放大版本的物体的通过测试的地方,放大的版本绘制后物体就会有一个边。我们基本会使用模板缓冲丢弃所有的不是原来物体的片段的放大的版本内容。
|
||||
|
||||
我们先来创建一个非常基本的片段着色器,它输出一个边框颜色。我们简单地设置一个固定的颜色值,把这个着色器命名为shaderSingleColor:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
outColor = vec4(0.04, 0.28, 0.26, 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
我们只打算给两个箱子加上边框,所以我们不会对地面做什么。这样我们要先绘制地面,然后再绘制两个箱子(同时写入模板缓冲),接着我们绘制放大的箱子(同时丢弃前面已经绘制的箱子的那部分片段)。
|
||||
|
||||
我们先开启模板测试,设置模板、深度测试通过或失败时才采取动作:
|
||||
|
||||
```c++
|
||||
glEnable(GL_DEPTH_TEST);
|
||||
glStencilOp(GL_KEEP, GL_KEEP, GL_REPLACE);
|
||||
```
|
||||
|
||||
如果任何测试失败我们都什么也不做,我们简单地保持深度缓冲中当前所储存着的值。如果模板测试和深度测试都成功了,我们就将储存着的模板值替换为`1`,我们要用`glStencilFunc`来做这件事。
|
||||
|
||||
我们清空模板缓冲为0,为箱子的所有绘制的片段的模板缓冲更新为1:
|
||||
|
||||
```c++
|
||||
glStencilFunc(GL_ALWAYS, 1, 0xFF); //所有片段都要写入模板缓冲
|
||||
glStencilMask(0xFF); // 设置模板缓冲为可写状态
|
||||
normalShader.Use();
|
||||
DrawTwoContainers();
|
||||
```
|
||||
|
||||
使用`GL_ALWAYS`模板测试函数,我们确保箱子的每个片段用模板值1更新模板缓冲。因为片段总会通过模板测试,在我们绘制它们的地方,模板缓冲用引用值更新。
|
||||
|
||||
现在箱子绘制之处,模板缓冲更新为1了,我们将要绘制放大的箱子,但是这次关闭模板缓冲的写入:
|
||||
|
||||
```c++
|
||||
glStencilFunc(GL_NOTEQUAL, 1, 0xFF);
|
||||
glStencilMask(0x00); // 禁止修改模板缓冲
|
||||
glDisable(GL_DEPTH_TEST);
|
||||
shaderSingleColor.Use();
|
||||
DrawTwoScaledUpContainers();
|
||||
```
|
||||
|
||||
我们把模板方程设置为`GL_NOTEQUAL`,它保证我们只箱子上不等于1的部分,这样只绘制前面绘制的箱子外围的那部分。注意,我们也要关闭深度测试,这样放大的的箱子也就是边框才不会被地面覆盖。
|
||||
|
||||
做完之后还要保证再次开启深度缓冲。
|
||||
|
||||
场景中的物体边框的绘制方法最后看起来像这样:
|
||||
|
||||
```c++
|
||||
glEnable(GL_DEPTH_TEST);
|
||||
glStencilOp(GL_KEEP, GL_KEEP, GL_REPLACE);
|
||||
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
|
||||
|
||||
glStencilMask(0x00); // 绘制地板时确保关闭模板缓冲的写入
|
||||
normalShader.Use();
|
||||
DrawFloor()
|
||||
|
||||
glStencilFunc(GL_ALWAYS, 1, 0xFF);
|
||||
glStencilMask(0xFF);
|
||||
DrawTwoContainers();
|
||||
|
||||
glStencilFunc(GL_NOTEQUAL, 1, 0xFF);
|
||||
glStencilMask(0x00);
|
||||
glDisable(GL_DEPTH_TEST);
|
||||
shaderSingleColor.Use();
|
||||
DrawTwoScaledUpContainers();
|
||||
glStencilMask(0xFF);
|
||||
glEnable(GL_DEPTH_TEST);
|
||||
```
|
||||
|
||||
理解这段代码后面的模板测试的思路并不难以理解。如果还不明白尝试再仔细阅读上面的部分,尝试理解每个函数的作用,现在你已经看到了它的使用方法的例子。
|
||||
|
||||
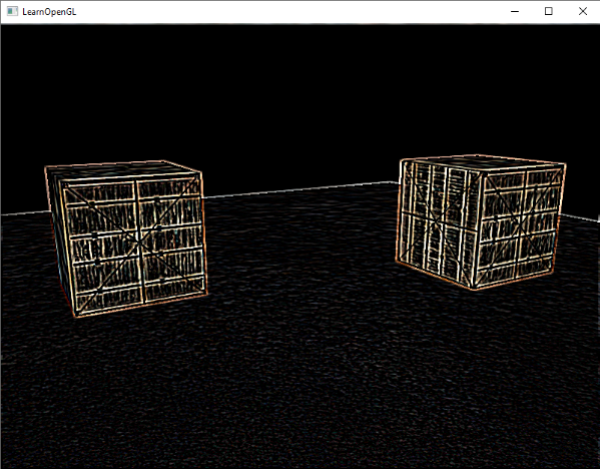
这个边框的算法的结果在深度测试教程的那个场景中,看起来像这样:
|
||||
|
||||
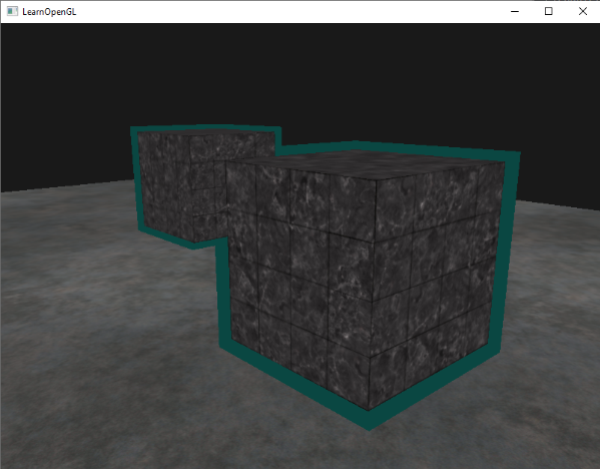
|
||||
|
||||
在这里[查看源码](http://learnopengl.com/code_viewer.php?code=advanced/stencil_testing)和[着色器](http://learnopengl.com/code_viewer.php?code=advanced/depth_testing_func_shaders),看看完整的物体边框算法是怎样的。
|
||||
|
||||
!!! Important
|
||||
|
||||
你可以看到两个箱子边框重合通常正是我们希望得到的(想想策略游戏中,我们打算选择10个单位;我们通常会希望把边界合并)。如果你想要让每个物体都有自己的边界那么你需要为每个物体清空模板缓冲,创造性地使用深度缓冲。
|
||||
|
||||
你目前看到的物体边框算法在一些游戏中显示备选物体(想象策略游戏)非常常用,这样的算法可以在一个模型类中轻易实现。你可以简单地在模型类设置一个布尔类型的标识来决定是否绘制边框。如果你想要更多的创造性,你可以使用后处理(post-processing)过滤比如高斯模糊来使边框看起来更自然。
|
||||
|
||||
除了物体边框以外,模板测试还有很多其他的应用目的,比如在后视镜中绘制纹理,这样它会很好的适合镜子的形状,比如使用一种叫做shadow volumes的模板缓冲技术渲染实时阴影。模板缓冲在我们的已扩展的OpenGL工具箱中给我们提供了另一种好用工具。
|
||||
283
04 Advanced OpenGL/03 Blending.md
Normal file
283
04 Advanced OpenGL/03 Blending.md
Normal file
@@ -0,0 +1,283 @@
|
||||
# 混合(Blending)
|
||||
|
||||
原文 | [Blending](http://learnopengl.com/#!Advanced-OpenGL/Blending)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
|
||||
在OpenGL中,物体透明技术通常被叫做混合(Blending)。透明是物体(或物体的一部分)非纯色而是混合色,这种颜色来自于不同浓度的自身颜色和它后面的物体颜色。一个有色玻璃窗就是一种透明物体,玻璃有自身的颜色,但是最终的颜色包含了所有玻璃后面的颜色。这也正是混合这名称的出处,因为我们将多种(来自于不同物体)颜色混合为一个颜色,透明使得我们可以看穿物体。
|
||||
|
||||

|
||||
|
||||
透明物体可以是完全透明(它使颜色完全穿透)或者半透明的(它使颜色穿透的同时也显示自身颜色)。一个物体的透明度,被定义为它的颜色的alpha值。alpha颜色值是一个颜色向量的第四个元素,你可能已经看到很多了。在这个教程前,我们一直把这个元素设置为1.0,这样物体的透明度就是0.0,同样的,当alpha值是0.0时就表示物体是完全透明的,alpha值为0.5时表示物体的颜色由50%的自身的颜色和50%的后面的颜色组成。
|
||||
|
||||
我们之前所使用的纹理都是由3个颜色元素组成的:红、绿、蓝,但是有些纹理同样有一个内嵌的aloha通道,它为每个纹理像素(Texel)包含着一个alpha值。这个alpha值告诉我们纹理的哪个部分有透明度,以及这个透明度有多少。例如,下面的窗子纹理的玻璃部分的alpha值为0.25(它的颜色是完全红色,但是由于它有75的透明度,它会很大程度上反映出网站的背景色,看起来就不那么红了),角落部分alpha是0.0。
|
||||
|
||||

|
||||
|
||||
我们很快就会把这个窗子纹理加到场景中,但是首先,我们将讨论一点简单的技术来实现纹理的半透明,也就是完全透明和完全不透明。
|
||||
|
||||
## 忽略片段
|
||||
|
||||
有些图像并不关心半透明度,但也想基于纹理的颜色值显示一部分。例如,创建像草这种物体你不需要花费很大力气,通常把一个草的纹理贴到2D四边形上,然后把这个四边形放置到你的场景中。可是,草并不是像2D四边形这样的形状,而只需要显示草纹理的一部分而忽略其他部分。
|
||||
|
||||
下面的纹理正是这样的纹理,它既有完全不透明的部分(alpha值为1.0)也有完全透明的部分(alpha值为0.0),而没有半透明的部分。你可以看到没有草的部分,图片显示了网站的背景色,而不是它自身的那部分颜色。
|
||||
|
||||

|
||||
|
||||
所以,当向场景中添加像这样的纹理时,我们不希望看到一个方块图像,而是只显示实际的纹理像素,剩下的部分可以被看穿。我们要忽略(丢弃)纹理透明部分的像素,不必将这些片段储存到颜色缓冲中。在此之前,我们还要学一下如何加载一个带有透明像素的纹理。
|
||||
|
||||
加载带有alpha值的纹理我们需要告诉SOIL,去加载RGBA元素图像,而不再是RGB元素的。SOIL能以RGBA的方式加载大多数没有alpha值的纹理,它会将这些像素的alpha值设为了1.0。
|
||||
|
||||
```c++
|
||||
unsigned char * image = SOIL_load_image(path, &width, &height, 0, SOIL_LOAD_RGBA);
|
||||
```
|
||||
|
||||
不要忘记还要改变OpenGL生成的纹理:
|
||||
|
||||
```c++
|
||||
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, image);
|
||||
```
|
||||
|
||||
保证你在片段着色器中获取了纹理的所有4个颜色元素,而不仅仅是RGB元素:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
// color = vec4(vec3(texture(texture1, TexCoords)), 1.0);
|
||||
color = texture(texture1, TexCoords);
|
||||
}
|
||||
```
|
||||
|
||||
现在我们知道了如何加载透明纹理,是时候试试在深度测试教程里那个场景中添加几根草了。
|
||||
|
||||
我们创建一个`std::vector`,并向里面添加几个`glm::vec3`变量,来表示草的位置:
|
||||
|
||||
```c++
|
||||
vector<glm::vec3> vegetation;
|
||||
vegetation.push_back(glm::vec3(-1.5f, 0.0f, -0.48f));
|
||||
vegetation.push_back(glm::vec3( 1.5f, 0.0f, 0.51f));
|
||||
vegetation.push_back(glm::vec3( 0.0f, 0.0f, 0.7f));
|
||||
vegetation.push_back(glm::vec3(-0.3f, 0.0f, -2.3f));
|
||||
vegetation.push_back(glm::vec3( 0.5f, 0.0f, -0.6f));
|
||||
```
|
||||
|
||||
一个单独的四边形被贴上草的纹理,这并不能完美的表现出真实的草,但是比起加载复杂的模型还是要高效很多,利用一些小技巧,比如在同一个地方添加多个不同朝向的草,还是能获得比较好的效果的。
|
||||
|
||||
由于草纹理被添加到四边形物体上,我们需要再次创建另一个VAO,向里面填充VBO,以及设置合理的顶点属性指针。在我们绘制完地面和两个立方体后,我们就来绘制草叶:
|
||||
|
||||
```c++
|
||||
glBindVertexArray(vegetationVAO);
|
||||
glBindTexture(GL_TEXTURE_2D, grassTexture);
|
||||
for(GLuint i = 0; i < vegetation.size(); i++)
|
||||
{
|
||||
model = glm::mat4();
|
||||
model = glm::translate(model, vegetation[i]);
|
||||
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));
|
||||
glDrawArrays(GL_TRIANGLES, 0, 6);
|
||||
}
|
||||
glBindVertexArray(0);
|
||||
```
|
||||
|
||||
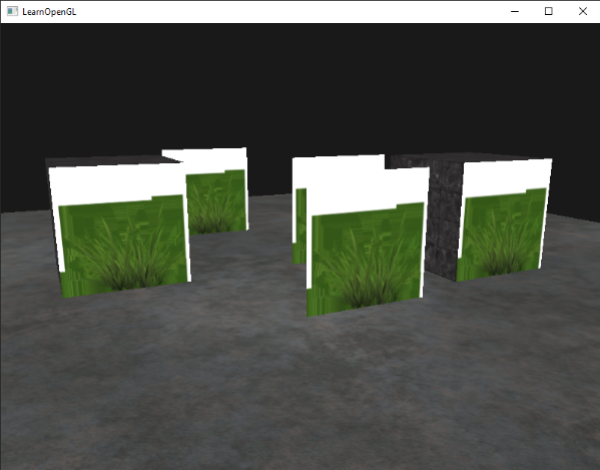
运行程序你将看到:
|
||||
|
||||
|
||||
出现这种情况是因为OpenGL默认是不知道如何处理alpha值的,不知道何时忽略(丢弃)它们。我们不得不手动做这件事。幸运的是这很简单,感谢着色器,GLSL为我们提供了discard命令,它保证了片段不会被进一步处理,这样就不会进入颜色缓冲。有了这个命令我们就可以在片段着色器中检查一个片段是否有在一定的阈限下的alpha值,如果有,那么丢弃这个片段,就好像它不存在一样:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
in vec2 TexCoords;
|
||||
|
||||
out vec4 color;
|
||||
|
||||
uniform sampler2D texture1;
|
||||
|
||||
void main()
|
||||
{
|
||||
vec4 texColor = texture(texture1, TexCoords);
|
||||
if(texColor.a < 0.1)
|
||||
discard;
|
||||
color = texColor;
|
||||
}
|
||||
```
|
||||
|
||||
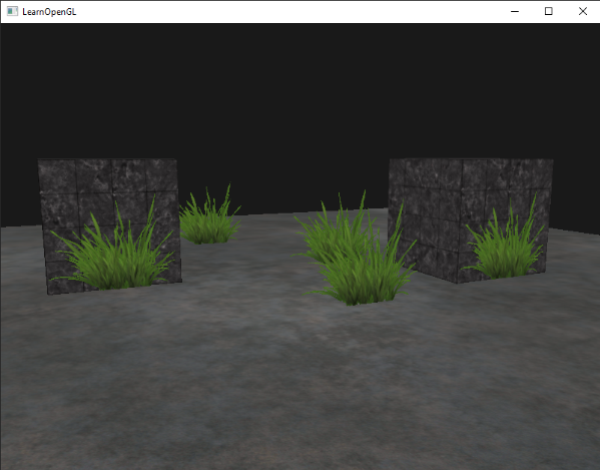
在这儿我们检查被采样纹理颜色包含着一个低于0.1这个阈限的alpha值,如果有,就丢弃这个片段。这个片段着色器能够保证我们只渲染哪些不是完全透明的片段。现在我们来看看效果:
|
||||
|
||||
|
||||
|
||||
!!! Important
|
||||
|
||||
需要注意的是,当采样纹理边缘的时候,OpenGL在边界值和下一个重复的纹理的值之间进行插值(因为我们把它的放置方式设置成了GL_REPEAT)。这样就行了,但是由于我们使用的是透明值,纹理图片的上部获得了它的透明值是与底边的纯色值进行插值的。结果就是一个有点半透明的边,你可以从我们的纹理四边形的四周看到。为了防止它的出现,当你使用alpha纹理的时候要把纹理环绕方式设置为`GL_CLAMP_TO_EDGE`:
|
||||
|
||||
`glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);`
|
||||
|
||||
`glTexParameteri( GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);`
|
||||
|
||||
你可以[在这里得到源码](http://learnopengl.com/code_viewer.php?code=advanced/blending_discard)。
|
||||
|
||||
|
||||
## 混合
|
||||
|
||||
上述丢弃片段的方式,不能使我们获得渲染半透明图像,我们要么渲染出像素,要么完全地丢弃它。为了渲染出不同的透明度级别,我们需要开启**混合**(Blending)。像大多数OpenGL的功能一样,我们可以开启`GL_BLEND`来启用混合功能:
|
||||
|
||||
```c++
|
||||
glEnable(GL_BLEND);
|
||||
```
|
||||
|
||||
开启混合后,我们还需要告诉OpenGL它该如何混合。
|
||||
|
||||
OpenGL以下面的方程进行混合:
|
||||
|
||||
C¯result = C¯source ∗ Fsource + C¯destination ∗ Fdestination
|
||||
|
||||
* C¯source:源颜色向量。这是来自纹理的本来的颜色向量。
|
||||
* C¯destination:目标颜色向量。这是储存在颜色缓冲中当前位置的颜色向量。
|
||||
* Fsource:源因子。设置了对源颜色的alpha值影响。
|
||||
* Fdestination:目标因子。设置了对目标颜色的alpha影响。
|
||||
|
||||
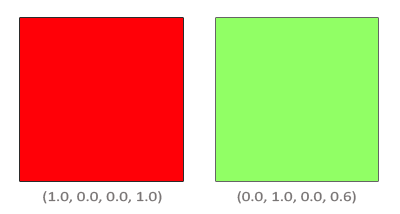
片段着色器运行完成并且所有的测试都通过以后,混合方程才能自由执行片段的颜色输出,当前它在颜色缓冲中(前面片段的颜色在当前片段之前储存)。源和目标颜色会自动被OpenGL设置,而源和目标因子可以让我们自由设置。我们来看一个简单的例子:
|
||||
|
||||
|
||||
|
||||
我们有两个方块,我们希望在红色方块上绘制绿色方块。红色方块会成为源颜色(它会先进入颜色缓冲),我们将在红色方块上绘制绿色方块。
|
||||
|
||||
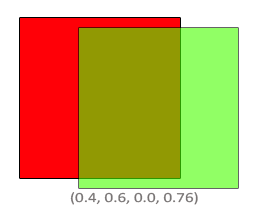
那么问题来了:我们怎样来设置因子呢?我们起码要把绿色方块乘以它的alpha值,所以我们打算把Fsource设置为源颜色向量的alpha值:0.6。接着,让目标方块的浓度等于剩下的alpha值。如果最终的颜色中绿色方块的浓度为60%,我们就把红色的浓度设为40%(1.0 – 0.6)。所以我们把Fdestination设置为1减去源颜色向量的alpha值。方程将变成:
|
||||
|
||||

|
||||
|
||||
最终方块结合部分包含了60%的绿色和40%的红色,得到一种脏兮兮的颜色:
|
||||
|
||||
|
||||
|
||||
最后的颜色被储存到颜色缓冲中,取代先前的颜色。
|
||||
|
||||
这个方案不错,但我们怎样告诉OpenGL来使用这样的因子呢?恰好有一个叫做`glBlendFunc`的函数。
|
||||
|
||||
`void glBlendFunc(GLenum sfactor, GLenum dfactor)`接收两个参数,来设置源(source)和目标(destination)因子。OpenGL为我们定义了很多选项,我们把最常用的列在下面。注意,颜色常数向量C¯constant可以用`glBlendColor`函数分开来设置。
|
||||
|
||||
|
||||
Option | Value
|
||||
---|---
|
||||
GL_ZERO | 0
|
||||
GL_ONE | 1
|
||||
GL_SRC_COLOR | 颜色C¯source.
|
||||
GL_ONE_MINUS_SRC_COLOR | 1 − C¯source.
|
||||
GL_DST_COLOR | C¯destination
|
||||
GL_ONE_MINUS_DST_COLOR | 1 − C¯destination.
|
||||
GL_SRC_ALPHA | C¯source的alpha值
|
||||
GL_ONE_MINUS_SRC_ALPHA | 1 - C¯source的alpha值
|
||||
GL_DST_ALPHA | C¯destination的alpha值
|
||||
GL_ONE_MINUS_DST_ALPHA | 1 - C¯destination的alpha值
|
||||
GL_CONSTANT_COLOR | C¯constant.
|
||||
GL_ONE_MINUS_CONSTANT_COLOR | 1 - C¯constant
|
||||
GL_CONSTANT_ALPHA | C¯constant的alpha值
|
||||
GL_ONE_MINUS_CONSTANT_ALPHA | 1 − C¯constant的alpha值
|
||||
|
||||
为从两个方块获得混合结果,我们打算把源颜色的alpha给源因子,1-alpha给目标因子。调整到`glBlendFunc`之后就像这样:
|
||||
|
||||
```c++
|
||||
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
|
||||
```
|
||||
|
||||
也可以为RGB和alpha通道各自设置不同的选项,使用`glBlendFuncSeperate`:
|
||||
|
||||
```c++
|
||||
glBlendFuncSeperate(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA,GL_ONE, GL_ZERO);
|
||||
```
|
||||
|
||||
这个方程就像我们之前设置的那样,设置了RGB元素,但是只让最终的alpha元素被源alpha值影响到。
|
||||
|
||||
OpenGL给了我们更多的自由,我们可以改变方程源和目标部分的操作符。现在,源和目标元素已经相加了。如果我们愿意的话,我们还可以把它们相减。
|
||||
|
||||
`void glBlendEquation(GLenum mode)`允许我们设置这个操作,有3种可行的选项:
|
||||
|
||||
* GL_FUNC_ADD:默认的,彼此元素相加:C¯result = Src + Dst.
|
||||
* GL_FUNC_SUBTRACT:彼此元素相减: C¯result = Src – Dst.
|
||||
* GL_FUNC_REVERSE_SUBTRACT:彼此元素相减,但顺序相反:C¯result = Dst – Src.
|
||||
|
||||
通常我们可以简单地省略`glBlendEquation`因为GL_FUNC_ADD在大多数时候就是我们想要的,但是如果你如果你真想尝试努力打破主流常规,其他的方程或许符合你的要求。
|
||||
|
||||
### 渲染半透明纹理
|
||||
|
||||
现在我们知道OpenGL如何处理混合,是时候把我们的知识运用起来了,我们来添加几个半透明窗子。我们会使用本教程开始时用的那个场景,但是不再渲染草纹理,取而代之的是来自教程开始处半透明窗子纹理。
|
||||
|
||||
首先,初始化时我们需要开启混合,设置合适和混合方程:
|
||||
|
||||
```c++
|
||||
glEnable(GL_BLEND);
|
||||
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
|
||||
```
|
||||
|
||||
由于我们开启了混合,就不需要丢弃片段了,所以我们把片段着色器设置为原来的那个版本:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
in vec2 TexCoords;
|
||||
|
||||
out vec4 color;
|
||||
|
||||
uniform sampler2D texture1;
|
||||
|
||||
void main()
|
||||
{
|
||||
color = texture(texture1, TexCoords);
|
||||
}
|
||||
```
|
||||
|
||||
这一次(无论OpenGL什么时候去渲染一个片段),它都根据alpha值,把当前片段的颜色和颜色缓冲中的颜色进行混合。因为窗子的玻璃部分的纹理是半透明的,我们应该可以透过玻璃看到整个场景。
|
||||
|
||||
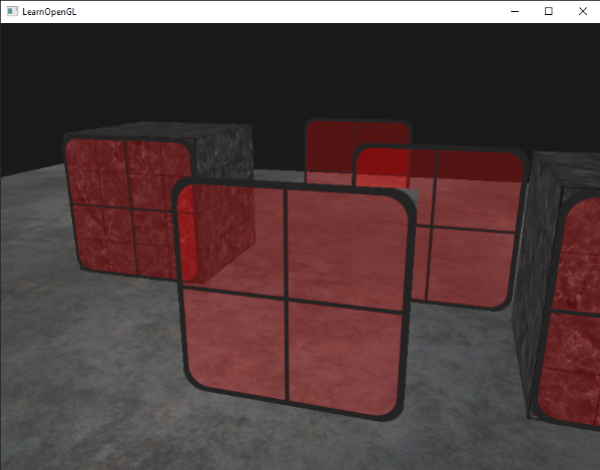
|
||||
|
||||
如果你仔细看看,就会注意到有些不对劲。前面的窗子透明部分阻塞了后面的。为什么会这样?
|
||||
|
||||
原因是深度测试在与混合的一同工作时出现了点状况。当写入深度缓冲的时候,深度测试不关心片段是否有透明度,所以透明部分被写入深度缓冲,就和其他值没什么区别。结果是整个四边形的窗子被检查时都忽视了透明度。即便透明部分应该显示出后面的窗子,深度缓冲还是丢弃了它们。
|
||||
|
||||
所以我们不能简简单单地去渲染窗子,我们期待着深度缓冲为我们解决这所有问题;这也正是混合之处代码不怎么好看的原因。为保证前面窗子显示了它后面的窗子,我们必须首先绘制后面的窗子。这意味着我们必须手工调整窗子的顺序,从远到近地逐个渲染。
|
||||
|
||||
!!! Important
|
||||
|
||||
对于全透明物体,比如草叶,我们选择简单的丢弃透明像素而不是混合,这样就减少了令我们头疼的问题(没有深度测试问题)。
|
||||
|
||||
### 别打乱顺序
|
||||
|
||||
要让混合在多物体上有效,我们必须先绘制最远的物体,最后绘制最近的物体。普通的无混合物体仍然可以使用深度缓冲正常绘制,所以不必给它们排序。我们一定要保证它们在透明物体前绘制好。当无透明度物体和透明物体一起绘制的时候,通常要遵循以下原则:
|
||||
|
||||
先绘制所有不透明物体。
|
||||
为所有透明物体排序。
|
||||
按顺序绘制透明物体。
|
||||
一种排序透明物体的方式是,获取一个物体到观察者透视图的距离。这可以通过获取摄像机的位置向量和物体的位置向量来得到。接着我们就可以把它和相应的位置向量一起储存到一个map数据结构(STL库)中。map会自动基于它的键排序它的值,所以当我们把它们的距离作为键添加到所有位置中后,它们就自动按照距离值排序了:
|
||||
|
||||
```c++
|
||||
std::map<float, glm::vec3> sorted;
|
||||
for (GLuint i = 0; i < windows.size(); i++) // windows contains all window positions
|
||||
{
|
||||
GLfloat distance = glm::length(camera.Position - windows[i]);
|
||||
sorted[distance] = windows[i];
|
||||
}
|
||||
```
|
||||
|
||||
最后产生了一个容器对象,基于它们距离从低到高储存了每个窗子的位置。
|
||||
|
||||
随后当渲染的时候,我们逆序获取到每个map的值(从远到近),然后以正确的绘制相应的窗子:
|
||||
|
||||
```c++
|
||||
for(std::map<float,glm::vec3>::reverse_iterator it = sorted.rbegin(); it != sorted.rend(); ++it)
|
||||
{
|
||||
model = glm::mat4();
|
||||
model = glm::translate(model, it->second);
|
||||
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));
|
||||
glDrawArrays(GL_TRIANGLES, 0, 6);
|
||||
}
|
||||
```
|
||||
|
||||
我们从map得来一个逆序的迭代器,迭代出每个逆序的条目,然后把每个窗子的四边形平移到相应的位置。这个相对简单的方法对透明物体进行了排序,修正了前面的问题,现在场景看起来像这样:
|
||||
|
||||
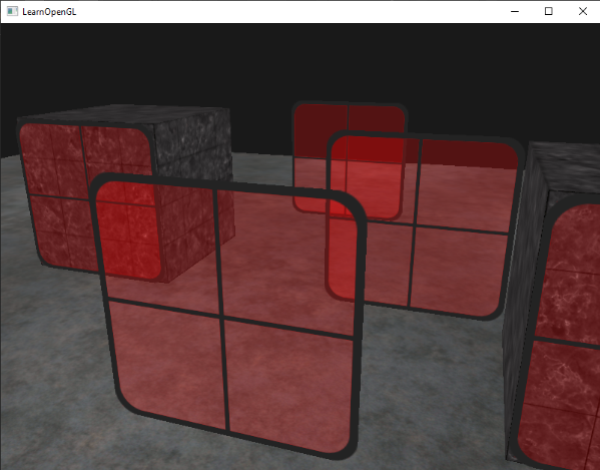
|
||||
|
||||
你可以[从这里得到完整的带有排序的源码](http://learnopengl.com/code_viewer.php?code=advanced/blending_sorted)。
|
||||
|
||||
虽然这个按照它们的距离对物体进行排序的方法在这个特定的场景中能够良好工作,但它不能进行旋转、缩放或者进行其他的变换,奇怪形状的物体需要一种不同的方式,而不能简单的使用位置向量。
|
||||
|
||||
在场景中排序物体是个有难度的技术,它很大程度上取决于你场景的类型,更不必说会耗费额外的处理能力了。完美地渲染带有透明和不透明的物体的场景并不那么容易。有更高级的技术例如次序无关透明度(order independent transparency),但是这超出了本教程的范围。现在你不得不采用普通的混合你的物体,但是如果你小心谨慎,并知道这个局限,你仍可以得到颇为合适的混合实现。
|
||||
111
04 Advanced OpenGL/04 Face culling.md
Normal file
111
04 Advanced OpenGL/04 Face culling.md
Normal file
@@ -0,0 +1,111 @@
|
||||
# 面剔除(Face culling)
|
||||
|
||||
原文 | [Face culling](http://learnopengl.com/#!Advanced-OpenGL/Face-culling)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
尝试在头脑中想象一下有一个3D立方体,你从任何一个方向去看它,最多可以同时看到多少个面。如果你的想象力不是过于丰富,你最终最多能数出来的面是3个。你可以从一个立方体的任意位置和方向上去看它,但是你永远不能看到多于3个面。所以我们为何还要去绘制那三个不会显示出来的3个面呢。如果我们可以以某种方式丢弃它们,我们会提高片段着色器超过50%的性能!
|
||||
|
||||
!!! Important
|
||||
|
||||
我们所说的是超过50%而不是50%,因为从一个角度只有2个或1个面能够被看到。这种情况下我们就能够提高50%以上性能了。
|
||||
|
||||
|
||||
这的确是个好主意,但是有个问题需要解决:我们如何知道某个面在观察者的视野中不会出现呢?如果我们去想象任何封闭的几何平面,它们都有两面,一面面向用户,另一面背对用户。假如我们只渲染面向观察者的面会怎样?
|
||||
|
||||
这正是**面剔除**(Face culling)所要做的。OpenGL允许检查所有正面朝向(Front facing)观察者的面,并渲染它们,而丢弃所有背面朝向(Back facing)的面,这样就节约了我们很多片段着色器的命令(它们很昂贵!)。我们必须告诉OpenGL我们使用的哪个面是正面,哪个面是反面。OpenGL使用一种聪明的手段解决这个问题——分析顶点数据的连接顺序(Winding order)。
|
||||
|
||||
|
||||
## 顶点连接顺序(Winding order)
|
||||
|
||||
当我们定义一系列的三角顶点时,我们会把它们定义为一个特定的连接顺序,它们可能是顺时针的或逆时针的。每个三角形由3个顶点组成,我们从三角形的中间去看,从而把这三个顶点指定一个连接顺序。
|
||||
|
||||
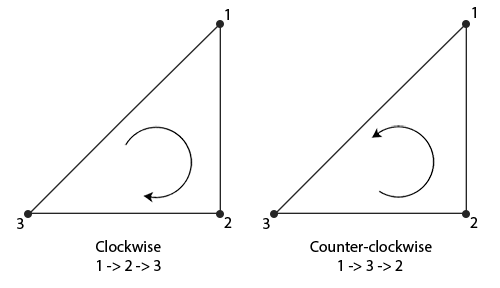
|
||||
|
||||
正如你所看到的那样,我们先定义了顶点1,接着我们定义顶点2或3,这个不同的选择决定了这个三角形的连接顺序。下面的代码展示出这点:
|
||||
|
||||
```c++
|
||||
GLfloat vertices[] = {
|
||||
//顺时针
|
||||
vertices[0], // vertex 1
|
||||
vertices[1], // vertex 2
|
||||
vertices[2], // vertex 3
|
||||
// 逆时针
|
||||
vertices[0], // vertex 1
|
||||
vertices[2], // vertex 3
|
||||
vertices[1] // vertex 2
|
||||
};
|
||||
```
|
||||
|
||||
每三个顶点都形成了一个包含着连接顺序的基本三角形。OpenGL使用这个信息在渲染你的基本图形的时候决定这个三角形是三角形的正面还是三角形的背面。默认情况下,**逆时针**的顶点连接顺序被定义为三角形的**正面**。
|
||||
|
||||
当定义你的顶点顺序时,你如果定义能够看到的一个三角形,那它一定是正面朝向的,所以你定义的三角形应该是逆时针的,就像你直接面向这个三角形。把所有的顶点指定成这样是件炫酷的事,实际的顶点连接顺序是在**光栅化**阶段(Rasterization stage)计算的,所以当顶点着色器已经运行后。顶点就能够在观察者的观察点被看到。
|
||||
|
||||
我们指定了它们以后,观察者面对的所有的三角形的顶点的连接顺序都是正确的,但是现在渲染的立方体另一面的三角形的顶点的连接顺序被反转。最终,我们所面对的三角形被视为正面朝向的三角形,后部的三角形被视为背面朝向的三角形。下图展示了这个效果:
|
||||
|
||||
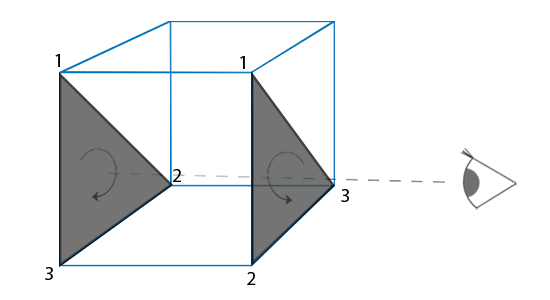
|
||||
|
||||
在顶点数据中,我们定义的是两个逆时针顺序的三角形。然而,从观察者的方面看,后面的三角形是顺时针的,如果我们仍以1、2、3的顺序以观察者当面的视野看的话。即使我们以逆时针顺序定义后面的三角形,它现在还是变为顺时针。它正是我们打算剔除(丢弃)的不可见的面!
|
||||
|
||||
|
||||
|
||||
## 面剔除
|
||||
|
||||
在教程的开头,我们说过OpenGL可以丢弃背面朝向的三角形。现在我们知道了如何设置顶点的连接顺序,我们可以开始使用OpenGL默认关闭的面剔除选项了。
|
||||
|
||||
记住我们上一节所使用的立方体的定点数据不是以逆时针顺序定义的。所以我更新了顶点数据,好去反应为一个逆时针链接顺序,你可以[从这里复制它](http://learnopengl.com/code_viewer.php?code=advanced/faceculling_vertexdata)。把所有三角的顶点都定义为逆时针是一个很好的习惯。
|
||||
|
||||
开启OpenGL的`GL_CULL_FACE`选项就能开启面剔除功能:
|
||||
|
||||
```c++
|
||||
glEnable(GL_CULL_FACE);
|
||||
```
|
||||
|
||||
从这儿以后,所有的不是正面朝向的面都会被丢弃(尝试飞入立方体看看,里面什么面都看不见了)。目前,在渲染片段上我们节约了超过50%的性能,但记住这只对像立方体这样的封闭形状有效。当我们绘制上个教程中那个草的时候,我们必须关闭面剔除,这是因为它的前、后面都必须是可见的。
|
||||
|
||||
OpenGL允许我们改变剔除面的类型。要是我们剔除正面而不是背面会怎样?我们可以调用`glCullFace`来做这件事:
|
||||
|
||||
```c++
|
||||
glCullFace(GL_BACK);
|
||||
```
|
||||
|
||||
`glCullFace`函数有三个可用的选项:
|
||||
|
||||
* GL_BACK:只剔除背面。
|
||||
* GL_FRONT:只剔除正面。
|
||||
* GL_FRONT_AND_BACK:剔除背面和正面。
|
||||
|
||||
`glCullFace`的初始值是`GL_BACK`。另外,我们还可以告诉OpenGL使用顺时针而不是逆时针来表示正面,这通过glFrontFace来设置:
|
||||
|
||||
```c++
|
||||
glFrontFace(GL_CCW);
|
||||
```
|
||||
|
||||
默认值是`GL_CCW`,它代表逆时针,`GL_CW`代表顺时针顺序。
|
||||
|
||||
我们可以做个小实验,告诉OpenGL现在顺时针代表正面:
|
||||
|
||||
```c++
|
||||
glEnable(GL_CULL_FACE);
|
||||
glCullFace(GL_BACK);
|
||||
glFrontFace(GL_CW);
|
||||
```
|
||||
|
||||
最后的结果只有背面被渲染了:
|
||||
|
||||
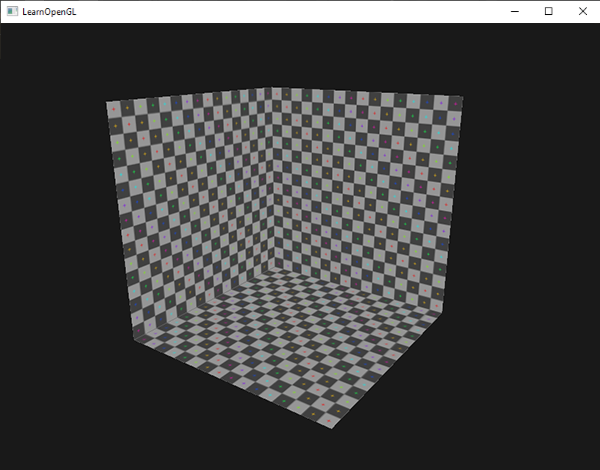
|
||||
|
||||
要注意,你可以使用默认逆时针顺序剔除正面,来创建相同的效果:
|
||||
|
||||
```c
|
||||
glEnable(GL_CULL_FACE);
|
||||
glCullFace(GL_FRONT);
|
||||
```
|
||||
|
||||
正如你所看到的那样,面剔除是OpenGL提高效率的一个强大工具,它使应用节省运算。你必须跟踪下来哪个物体可以使用面剔除,哪些不能。
|
||||
|
||||
## 练习
|
||||
|
||||
你可以自己重新定义一个顺时针的顶点顺序,然后用顺时针作为正面把它渲染出来吗:[解决方案](http://learnopengl.com/code_viewer.php?code=advanced/faceculling-exercise1)。
|
||||
428
04 Advanced OpenGL/05 Framebuffers.md
Normal file
428
04 Advanced OpenGL/05 Framebuffers.md
Normal file
@@ -0,0 +1,428 @@
|
||||
# 帧缓冲(Framebuffer)
|
||||
|
||||
原文 | [Framebuffers](http://learnopengl.com/#!Advanced-OpenGL/Framebuffers)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
到目前为止,我们使用了几种不同类型的屏幕缓冲:用于写入颜色值的颜色缓冲,用于写入深度信息的深度缓冲,以及允许我们基于一些条件丢弃指定片段的模板缓冲。把这几种缓冲结合起来叫做帧缓冲(Framebuffer),它被储存于内存中。OpenGL给了我们自己定义帧缓冲的自由,我们可以选择性的定义自己的颜色缓冲、深度和模板缓冲。
|
||||
|
||||
[译注1]: http://learnopengl-cn.readthedocs.org "framebuffer,在维基百科有framebuffer的详细介绍能够帮助你更好的理解"
|
||||
|
||||
我们目前所做的渲染操作都是是在默认的帧缓冲之上进行的。当你创建了你的窗口的时候默认帧缓冲就被创建和配置好了(GLFW为我们做了这件事)。通过创建我们自己的帧缓冲我们能够获得一种额外的渲染方式。
|
||||
|
||||
你也许不能立刻理解应用程序的帧缓冲的含义,通过帧缓冲可以将你的场景渲染到一个不同的帧缓冲中,可以使我们能够在场景中创建镜子这样的效果,或者做出一些炫酷的特效。首先我们会讨论它们是如何工作的,然后我们将利用帧缓冲来实现一些炫酷的效果。
|
||||
|
||||
## 创建一个帧缓冲
|
||||
|
||||
就像OpenGL中其他对象一样,我们可以使用一个叫做`glGenFramebuffers`的函数来创建一个帧缓冲对象(简称FBO):
|
||||
|
||||
```c++
|
||||
GLuint fbo;
|
||||
glGenFramebuffers(1, &fbo);
|
||||
```
|
||||
|
||||
这种对象的创建和使用的方式我们已经见过不少了,因此它们的使用方式也和之前我们见过的其他对象的使用方式相似。首先我们要创建一个帧缓冲对象,把它绑定到当前帧缓冲,做一些操作,然后解绑帧缓冲。我们使用`glBindFramebuffer`来绑定帧缓冲:
|
||||
|
||||
```c++
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, fbo);
|
||||
```
|
||||
|
||||
绑定到`GL_FRAMEBUFFER`目标后,接下来所有的读、写帧缓冲的操作都会影响到当前绑定的帧缓冲。也可以把帧缓冲分开绑定到读或写目标上,分别使用`GL_READ_FRAMEBUFFER`或`GL_DRAW_FRAMEBUFFER`来做这件事。如果绑定到了`GL_READ_FRAMEBUFFER`,就能执行所有读取操作,像`glReadPixels`这样的函数使用了;绑定到`GL_DRAW_FRAMEBUFFER`上,就允许进行渲染、清空和其他的写入操作。大多数时候你不必分开用,通常把两个都绑定到`GL_FRAMEBUFFER`上就行。
|
||||
|
||||
很遗憾,现在我们还不能使用自己的帧缓冲,因为还没做完呢。建构一个完整的帧缓冲必须满足以下条件:
|
||||
|
||||
* 我们必须往里面加入至少一个附件(颜色、深度、模板缓冲)。
|
||||
* 其中至少有一个是颜色附件。
|
||||
* 所有的附件都应该是已经完全做好的(已经存储在内存之中)。
|
||||
* 每个缓冲都应该有同样数目的样本。
|
||||
|
||||
如果你不知道什么是样本也不用担心,我们会在后面的教程中讲到。
|
||||
|
||||
从上面的需求中你可以看到,我们需要为帧缓冲创建一些附件,还需要把这些附件附加到帧缓冲上。当我们做完所有上面提到的条件的时候我们就可以用 `glCheckFramebufferStatus` 带上 `GL_FRAMEBUFFER` 这个参数来检查是否真的成功做到了。然后检查当前绑定的帧缓冲,返回了这些规范中的哪个值。如果返回的是 `GL_FRAMEBUFFER_COMPLETE`就对了:
|
||||
|
||||
```c++
|
||||
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) == GL_FRAMEBUFFER_COMPLETE)
|
||||
// Execute victory dance
|
||||
```
|
||||
|
||||
后续所有渲染操作将渲染到当前绑定的帧缓冲的附加缓冲中,由于我们的帧缓冲不是默认的帧缓冲,渲染命令对窗口的视频输出不会产生任何影响。出于这个原因,它被称为离屏渲染(off-screen rendering),就是渲染到一个另外的缓冲中。为了让所有的渲染操作对主窗口产生影响我们必须通过绑定为0来使默认帧缓冲被激活:
|
||||
|
||||
```c++
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
```
|
||||
|
||||
当我们做完所有帧缓冲操作,不要忘记删除帧缓冲对象:
|
||||
|
||||
```c++
|
||||
glDeleteFramebuffers(1, &fbo);
|
||||
```
|
||||
|
||||
现在在执行完成检测前,我们需要把一个或更多的附件附加到帧缓冲上。一个附件就是一个内存地址,这个内存地址里面包含一个为帧缓冲准备的缓冲,它可以是个图像。当创建一个附件的时候我们有两种方式可以采用:纹理或渲染缓冲(renderbuffer)对象。
|
||||
|
||||
## 纹理附件
|
||||
|
||||
当把一个纹理附加到帧缓冲上的时候,所有渲染命令会写入到纹理上,就像它是一个普通的颜色/深度或者模板缓冲一样。使用纹理的好处是,所有渲染操作的结果都会被储存为一个纹理图像,这样我们就可以简单的在着色器中使用了。
|
||||
|
||||
创建一个帧缓冲的纹理和创建普通纹理差不多:
|
||||
|
||||
```c++
|
||||
GLuint texture;
|
||||
glGenTextures(1, &texture);
|
||||
glBindTexture(GL_TEXTURE_2D, texture);
|
||||
|
||||
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
|
||||
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
|
||||
```
|
||||
|
||||
这里主要的区别是我们把纹理的维度设置为屏幕大小(尽管不是必须的),我们还传递NULL作为纹理的data参数。对于这个纹理,我们只分配内存,而不去填充它。纹理填充会在渲染到帧缓冲的时候去做。同样,要注意,我们不用关心环绕方式或者Mipmap,因为在大多数时候都不会需要它们的。
|
||||
|
||||
如果你打算把整个屏幕渲染到一个或大或小的纹理上,你需要用新的纹理的尺寸作为参数再次调用`glViewport`(要在渲染到你的帧缓冲之前做好),否则只有一小部分纹理或屏幕能够绘制到纹理上。
|
||||
|
||||
现在我们已经创建了一个纹理,最后一件要做的事情是把它附加到帧缓冲上:
|
||||
|
||||
```c++
|
||||
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0,GL_TEXTURE_2D, texture, 0);
|
||||
```
|
||||
|
||||
`glFramebufferTexture2D`函数需要传入下列参数:
|
||||
|
||||
* target:我们所创建的帧缓冲类型的目标(绘制、读取或两者都有)。
|
||||
* attachment:我们所附加的附件的类型。现在我们附加的是一个颜色附件。需要注意,最后的那个0是暗示我们可以附加1个以上颜色的附件。我们会在后面的教程中谈到。
|
||||
* textarget:你希望附加的纹理类型。
|
||||
* texture:附加的实际纹理。
|
||||
* level:Mipmap level。我们设置为0。
|
||||
|
||||
除颜色附件以外,我们还可以附加一个深度和一个模板纹理到帧缓冲对象上。为了附加一个深度缓冲,我们可以知道那个`GL_DEPTH_ATTACHMENT`作为附件类型。记住,这时纹理格式和内部格式类型(internalformat)就成了 `GL_DEPTH_COMPONENT`去反应深度缓冲的存储格式。附加一个模板缓冲,你要使用 `GL_STENCIL_ATTACHMENT`作为第二个参数,把纹理格式指定为 `GL_STENCIL_INDEX`。
|
||||
|
||||
也可以同时附加一个深度缓冲和一个模板缓冲为一个单独的纹理。这样纹理的每32位数值就包含了24位的深度信息和8位的模板信息。为了把一个深度和模板缓冲附加到一个单独纹理上,我们使用`GL_DEPTH_STENCIL_ATTACHMENT`类型配置纹理格式以包含深度值和模板值的结合物。下面是一个附加了深度和模板缓冲为单一纹理的例子:
|
||||
|
||||
```c++
|
||||
glTexImage2D( GL_TEXTURE_2D, 0, GL_DEPTH24_STENCIL8, 800, 600, 0, GL_DEPTH_STENCIL, GL_UNSIGNED_INT_24_8, NULL );
|
||||
|
||||
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_TEXTURE_2D, texture, 0);
|
||||
```
|
||||
|
||||
### 渲染缓冲对象附件(Renderbuffer object attachments)
|
||||
|
||||
在介绍了帧缓冲的可行附件类型——纹理后,OpenGL引进了渲染缓冲对象(Renderbuffer objects),所以在过去那些美好时光里纹理是附件的唯一可用的类型。和纹理图像一样,渲染缓冲对象也是一个缓冲,它可以是一堆字节、整数、像素或者其他东西。渲染缓冲对象的一大优点是,它以OpenGL原生渲染格式储存它的数据,因此在离屏渲染到帧缓冲的时候,这些数据就相当于被优化过的了。
|
||||
|
||||
渲染缓冲对象将所有渲染数据直接储存到它们的缓冲里,而不会进行针对特定纹理格式的任何转换,这样它们就成了一种快速可写的存储介质了。然而,渲染缓冲对象通常是只写的,不能修改它们(就像获取纹理,不能写入纹理一样)。可以用`glReadPixels`函数去读取,函数返回一个当前绑定的帧缓冲的特定像素区域,而不是直接返回附件本身。
|
||||
|
||||
因为它们的数据已经是原生格式了,在写入或把它们的数据简单地到其他缓冲的时候非常快。当使用渲染缓冲对象时,像切换缓冲这种操作变得异常高速。我们在每个渲染迭代末尾使用的那个`glfwSwapBuffers`函数,同样以渲染缓冲对象实现:我们简单地写入到一个渲染缓冲图像,最后交换到另一个里。渲染缓冲对象对于这种操作来说很完美。
|
||||
|
||||
创建一个渲染缓冲对象和创建帧缓冲代码差不多:
|
||||
|
||||
```c++
|
||||
GLuint rbo;
|
||||
glGenRenderbuffers(1, &rbo);
|
||||
```
|
||||
|
||||
相似地,我们打算把渲染缓冲对象绑定,这样所有后续渲染缓冲操作都会影响到当前的渲染缓冲对象:
|
||||
|
||||
```c++
|
||||
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
|
||||
```
|
||||
|
||||
由于渲染缓冲对象通常是只写的,它们经常作为深度和模板附件来使用,由于大多数时候,我们不需要从深度和模板缓冲中读取数据,但仍关心深度和模板测试。我们就需要有深度和模板值提供给测试,但不需要对这些值进行采样(sample),所以深度缓冲对象是完全符合的。当我们不去从这些缓冲中采样的时候,渲染缓冲对象通常很合适,因为它们等于是被优化过的。
|
||||
|
||||
调用`glRenderbufferStorage`函数可以创建一个深度和模板渲染缓冲对象:
|
||||
|
||||
```c
|
||||
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, 800, 600);
|
||||
```
|
||||
|
||||
创建一个渲染缓冲对象与创建纹理对象相似,不同之处在于这个对象是专门被设计用于图像的,而不是通用目的的数据缓冲,比如纹理。这里我们选择`GL_DEPTH24_STENCIL8`作为内部格式,它同时代表24位的深度和8位的模板缓冲。
|
||||
|
||||
最后一件还要做的事情是把帧缓冲对象附加上:
|
||||
|
||||
```c
|
||||
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);
|
||||
```
|
||||
|
||||
在帧缓冲项目中,渲染缓冲对象可以提供一些优化,但更重要的是知道何时使用渲染缓冲对象,何时使用纹理。通常的规则是,如果你永远都不需要从特定的缓冲中进行采样,渲染缓冲对象对特定缓冲是更明智的选择。如果哪天需要从比如颜色或深度值这样的特定缓冲采样数据的话,你最好还是使用纹理附件。从执行效率角度考虑,它不会对效率有太大影响。
|
||||
|
||||
### 渲染到纹理
|
||||
|
||||
现在我们知道了(一些)帧缓冲如何工作的,是时候把它们用起来了。我们会把场景渲染到一个颜色纹理上,这个纹理附加到一个我们创建的帧缓冲上,然后把纹理绘制到一个简单的四边形上,这个四边形铺满整个屏幕。输出的图像看似和没用帧缓冲一样,但是这次,它其实是直接打印到了一个单独的四边形上面。为什么这很有用呢?下一部分我们会看到原因。
|
||||
|
||||
第一件要做的事情是创建一个帧缓冲对象,并绑定它,这比较明了:
|
||||
|
||||
```c++
|
||||
GLuint framebuffer;
|
||||
glGenFramebuffers(1, &framebuffer);
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, framebuffer);
|
||||
```
|
||||
|
||||
下一步我们创建一个纹理图像,这是我们将要附加到帧缓冲的颜色附件。我们把纹理的尺寸设置为窗口的宽度和高度,并保持数据未初始化:
|
||||
|
||||
```c++
|
||||
// Generate texture
|
||||
GLuint texColorBuffer;
|
||||
glGenTextures(1, &texColorBuffer);
|
||||
glBindTexture(GL_TEXTURE_2D, texColorBuffer);
|
||||
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR );
|
||||
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
|
||||
glBindTexture(GL_TEXTURE_2D, 0);
|
||||
|
||||
// Attach it to currently bound framebuffer object
|
||||
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texColorBuffer, 0);
|
||||
```
|
||||
|
||||
我们同样打算要让OpenGL确定可以进行深度测试(模板测试,如果你用的话)所以我们必须还要确保向帧缓冲中添加一个深度(和模板)附件。由于我们只采样颜色缓冲,并不采样其他缓冲,我们可以创建一个渲染缓冲对象来达到这个目的。记住,当你不打算从指定缓冲采样的的时候,它们是一个不错的选择。
|
||||
|
||||
创建一个渲染缓冲对象不太难。唯一一件要记住的事情是,我们正在创建的是一个渲染缓冲对象的深度和模板附件。我们把它的内部给事设置为`GL_DEPTH24_STENCIL8`,对于我们的目的来说这个精确度已经足够了。
|
||||
|
||||
```c++
|
||||
GLuint rbo;
|
||||
glGenRenderbuffers(1, &rbo);
|
||||
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
|
||||
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, 800, 600);
|
||||
glBindRenderbuffer(GL_RENDERBUFFER, 0);
|
||||
```
|
||||
|
||||
我们为渲染缓冲对象分配了足够的内存空间以后,我们可以解绑渲染缓冲。
|
||||
|
||||
接着,在做好帧缓冲之前,还有最后一步,我们把渲染缓冲对象附加到帧缓冲的深度和模板附件上:
|
||||
|
||||
```c++
|
||||
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);
|
||||
```
|
||||
|
||||
然后我们要检查帧缓冲是否真的做好了,如果没有,我们就打印一个错误消息。
|
||||
|
||||
```c++
|
||||
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE)
|
||||
cout << "ERROR::FRAMEBUFFER:: Framebuffer is not complete!" << endl;
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
```
|
||||
|
||||
还要保证解绑帧缓冲,这样我们才不会意外渲染到错误的帧缓冲上。
|
||||
|
||||
现在帧缓冲做好了,我们要做的全部就是渲染到帧缓冲上,而不是绑定到帧缓冲对象的默认缓冲。余下所有命令会影响到当前绑定的帧缓冲上。所有深度和模板操作同样会从当前绑定的帧缓冲的深度和模板附件中读取,当然,得是在它们可用的情况下。如果你遗漏了比如深度缓冲,所有深度测试就不会工作,因为当前绑定的帧缓冲里没有深度缓冲。
|
||||
|
||||
所以,为把场景绘制到一个单独的纹理,我们必须以下面步骤来做:
|
||||
|
||||
1. 使用新的绑定为激活帧缓冲的帧缓冲,像往常那样渲染场景。
|
||||
2. 绑定到默认帧缓冲。
|
||||
3. 绘制一个四边形,让它平铺到整个屏幕上,用新的帧缓冲的颜色缓冲作为他的纹理。
|
||||
|
||||
我们使用在深度测试教程中同一个场景进行绘制,但是这次使用老气横秋的[箱子纹理](http://learnopengl.com/img/textures/container.jpg)。
|
||||
|
||||
为了绘制四边形我们将会创建新的着色器。我们不打算引入任何花哨的变换矩阵,因为我们只提供已经是标准化设备坐标的[顶点坐标](http://learnopengl.com/code_viewer.php?code=advanced/framebuffers_quad_vertices),所以我们可以直接把它们作为顶点着色器的输出。顶点着色器看起来像这样:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec2 position;
|
||||
layout (location = 1) in vec2 texCoords;
|
||||
|
||||
out vec2 TexCoords;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = vec4(position.x, position.y, 0.0f, 1.0f);
|
||||
TexCoords = texCoords;
|
||||
}
|
||||
```
|
||||
|
||||
没有花哨的地方。片段着色器更简洁,因为我们做的唯一一件事是从纹理采样:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
in vec2 TexCoords;
|
||||
out vec4 color;
|
||||
|
||||
uniform sampler2D screenTexture;
|
||||
|
||||
void main()
|
||||
{
|
||||
color = texture(screenTexture, TexCoords);
|
||||
}
|
||||
```
|
||||
|
||||
接着需要你为屏幕上的四边形创建和配置一个VAO。渲染迭代中帧缓冲处理会有下面的结构:
|
||||
|
||||
```c++
|
||||
// First pass
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, framebuffer);
|
||||
glClearColor(0.1f, 0.1f, 0.1f, 1.0f);
|
||||
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); // We're not using stencil buffer now
|
||||
glEnable(GL_DEPTH_TEST);
|
||||
DrawScene();
|
||||
|
||||
// Second pass
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0); // back to default
|
||||
glClearColor(1.0f, 1.0f, 1.0f, 1.0f);
|
||||
glClear(GL_COLOR_BUFFER_BIT);
|
||||
|
||||
screenShader.Use();
|
||||
glBindVertexArray(quadVAO);
|
||||
glDisable(GL_DEPTH_TEST);
|
||||
glBindTexture(GL_TEXTURE_2D, textureColorbuffer);
|
||||
glDrawArrays(GL_TRIANGLES, 0, 6);
|
||||
glBindVertexArray(0);
|
||||
```
|
||||
|
||||
只有很少的事情要说明。第一,由于我们用的每个帧缓冲都有自己的一系列缓冲,我们打算使用`glClear`设置的合适的位(bits)来清空这些缓冲。第二,当渲染四边形的时候,我们关闭深度测试,因为我们不关系深度测试,我们绘制的是一个简单的四边形;当我们绘制普通场景时我们必须再次开启深度测试。
|
||||
|
||||
这里的确有很多地方会做错,所以如果你没有获得任何输出,尝试排查任何可能出现错误的地方,再次阅读教程中相关章节。如果每件事都做对了就一定能成功,你将会得到这样的输出:
|
||||
|
||||
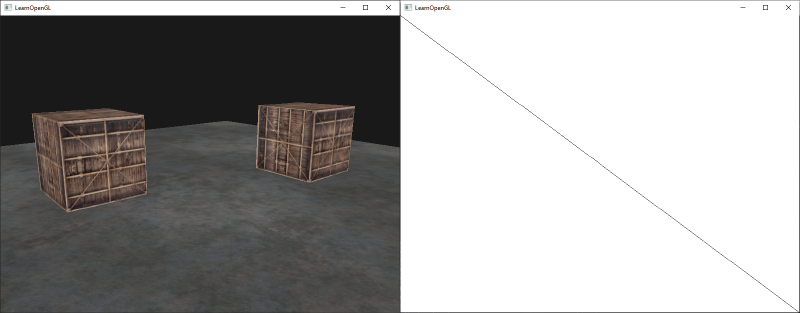
|
||||
|
||||
左侧展示了和深度测试教程中一样的输出结果,但是这次却是渲染到一个简单的四边形上的。如果我们以线框方式显示的话,那么显然,我们只是绘制了一个默认帧缓冲中单调的四边形。
|
||||
|
||||
你可以[从这里得到应用的源码](http://learnopengl.com/code_viewer.php?code=advanced/framebuffers_screen_texture)。
|
||||
|
||||
然而这有什么好处呢?好处就是我们现在可以自由的获取已经渲染场景中的任何像素,然后把它当作一个纹理图像了,我们可以在片段着色器中创建一些有意思的效果。所有这些有意思的效果统称为后处理特效。
|
||||
|
||||
|
||||
### 后处理
|
||||
|
||||
现在,整个场景渲染到了一个单独的纹理上,我们可以创建一些有趣的效果,只要简单操纵纹理数据就能做到。这部分,我们会向你展示一些流行的后处理特效,以及怎样添加一些创造性去创建出你自己的特效。
|
||||
|
||||
### 反相
|
||||
|
||||
我们已经取得了渲染输出的每个颜色,所以在片段着色器里返回这些颜色的反色并不难。我们得到屏幕纹理的颜色,然后用1.0减去它:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
color = vec4(vec3(1.0 - texture(screenTexture, TexCoords)), 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
虽然反相是一种相对简单的后处理特效,但是已经很有趣了:
|
||||
|
||||
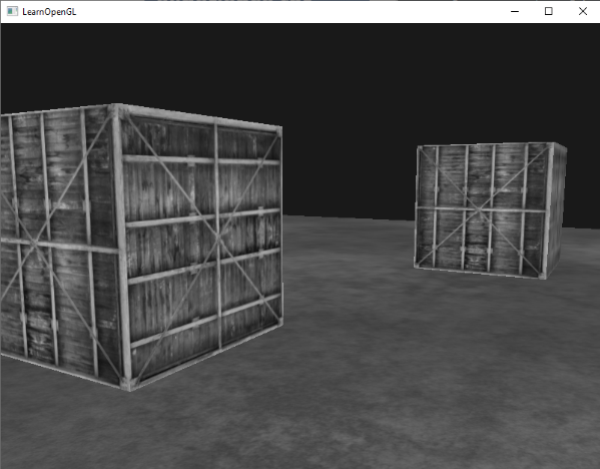
|
||||
|
||||
整个场景现在的颜色都反转了,只需在着色器中写一行代码就能做到,酷吧?
|
||||
|
||||
### 灰度
|
||||
|
||||
另一个有意思的效果是移除所有除了黑白灰以外的颜色作用,是整个图像成为黑白的。实现它的简单的方式是获得所有颜色元素,然后将它们平均化:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
color = texture(screenTexture, TexCoords);
|
||||
float average = (color.r + color.g + color.b) / 3.0;
|
||||
color = vec4(average, average, average, 1.0);
|
||||
}
|
||||
```
|
||||
这已经创造出很赞的效果了,但是人眼趋向于对绿色更敏感,对蓝色感知比较弱,所以为了获得更精确的符合人体物理的结果,我们需要使用加权通道:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
color = texture(screenTexture, TexCoords);
|
||||
float average = 0.2126 * color.r + 0.7152 * color.g + 0.0722 * color.b;
|
||||
color = vec4(average, average, average, 1.0);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Kernel effects
|
||||
|
||||
在单独纹理图像上进行后处理的另一个好处是我们可以从纹理的其他部分进行采样。比如我们可以从当前纹理值的周围采样多个纹理值。创造性地把它们结合起来就能创造出有趣的效果了。
|
||||
|
||||
kernel是一个长得有点像一个小矩阵的数值数组,它中间的值中心可以映射到一个像素上,这个像素和这个像素周围的值再乘以kernel,最后再把结果相加就能得到一个值。所以,我们基本上就是给当前纹理坐标加上一个它四周的偏移量,然后基于kernel把它们结合起来。下面是一个kernel的例子:
|
||||
|
||||

|
||||
|
||||
这个kernel表示一个像素周围八个像素乘以2,它自己乘以-15。这个例子基本上就是把周围像素乘上2,中间像素去乘以一个比较大的负数来进行平衡。
|
||||
|
||||
!!! Important
|
||||
|
||||
你在网上能找到的kernel的例子大多数都是所有值加起来等于1,如果加起来不等于1就意味着这个纹理值比原来更大或者更小了。
|
||||
|
||||
kernel对于后处理来说非常管用,因为用起来简单。网上能找到有很多实例,为了能用上kernel我们还得改改片段着色器。这里假设每个kernel都是3×3(实际上大多数都是3×3):
|
||||
|
||||
```c++
|
||||
const float offset = 1.0 / 300;
|
||||
|
||||
void main()
|
||||
{
|
||||
vec2 offsets[9] = vec2[](
|
||||
vec2(-offset, offset), // top-left
|
||||
vec2(0.0f, offset), // top-center
|
||||
vec2(offset, offset), // top-right
|
||||
vec2(-offset, 0.0f), // center-left
|
||||
vec2(0.0f, 0.0f), // center-center
|
||||
vec2(offset, 0.0f), // center-right
|
||||
vec2(-offset, -offset), // bottom-left
|
||||
vec2(0.0f, -offset), // bottom-center
|
||||
vec2(offset, -offset) // bottom-right
|
||||
);
|
||||
|
||||
float kernel[9] = float[](
|
||||
-1, -1, -1,
|
||||
-1, 9, -1,
|
||||
-1, -1, -1
|
||||
);
|
||||
|
||||
vec3 sampleTex[9];
|
||||
for(int i = 0; i < 9; i++)
|
||||
{
|
||||
sampleTex[i] = vec3(texture(screenTexture, TexCoords.st + offsets[i]));
|
||||
}
|
||||
vec3 col;
|
||||
for(int i = 0; i < 9; i++)
|
||||
col += sampleTex[i] * kernel[i];
|
||||
|
||||
color = vec4(col, 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
在片段着色器中我们先为每个四周的纹理坐标创建一个9个vec2偏移量的数组。偏移量是一个简单的常数,你可以设置为自己喜欢的。接着我们定义kernel,这里应该是一个锐化kernel,它通过一种有趣的方式从所有周边的像素采样,对每个颜色值进行锐化。最后,在采样的时候我们把每个偏移量加到当前纹理坐标上,然后用加在一起的kernel的值乘以这些纹理值。
|
||||
|
||||
这个锐化的kernel看起来像这样:
|
||||
|
||||
|
||||
|
||||
这里创建的有趣的效果就好像你的玩家吞了某种麻醉剂产生的幻觉一样。
|
||||
|
||||
### Blur
|
||||
|
||||
创建模糊效果的kernel定义如下:
|
||||
|
||||

|
||||
|
||||
由于所有数值加起来的总和为16,简单返回结合起来的采样颜色是非常亮的,所以我们必须将kernel的每个值除以16.最终的kernel数组会是这样的:
|
||||
|
||||
```c++
|
||||
float kernel[9] = float[](
|
||||
1.0 / 16, 2.0 / 16, 1.0 / 16,
|
||||
2.0 / 16, 4.0 / 16, 2.0 / 16,
|
||||
1.0 / 16, 2.0 / 16, 1.0 / 16
|
||||
);
|
||||
```
|
||||
|
||||
通过在像素着色器中改变kernel的float数组,我们就完全改变了之后的后处理效果.现在看起来会像是这样:
|
||||
|
||||
|
||||
|
||||
这样的模糊效果具有创建许多有趣效果的潜力.例如,我们可以随着时间的变化改变模糊量,创建出类似于某人喝醉酒的效果,或者,当我们的主角摘掉眼镜的时候增加模糊.模糊也能为我们在后面的教程中提供都颜色值进行平滑处理的能力.
|
||||
|
||||
你可以看到我们一旦拥有了这个kernel的实现以后,创建一个后处理特效就不再是一件难事.最后,我们再来讨论一个流行的特效,以结束本节内容.
|
||||
|
||||
### 边检测
|
||||
|
||||
下面的边检测kernel与锐化kernel类似:
|
||||
|
||||

|
||||
|
||||
这个kernel将所有的边提高亮度,而对其他部分进行暗化处理,当我们值关心一副图像的边缘的时候,它非常有用.
|
||||
|
||||
|
||||
|
||||
在一些像Photoshop这样的软件中使用这些kernel作为图像操作工具/过滤器一点都不奇怪.因为掀开可以具有很强的平行处理能力,我们以实时进行针对每个像素的图像操作便相对容易,图像编辑工具因而更经常使用显卡来进行图像处理。
|
||||
|
||||
## 练习
|
||||
|
||||
* 你可以使用帧缓冲来创建一个后视镜吗?做到它,你必须绘制场景两次:一次正常绘制,另一次摄像机旋转180度后绘制.尝试在你的显示器顶端创建一个小四边形,在上面应用后视镜的镜面纹理:[解决方案](http://learnopengl.com/code_viewer.php?code=advanced/framebuffers-exercise1),[视觉效果](http://learnopengl.com/img/advanced/framebuffers_mirror.png)
|
||||
* 自己随意调整一下kernel值,创建出你自己后处理特效.尝试在网上搜索其他有趣的kernel.
|
||||
398
04 Advanced OpenGL/06 Cubemaps.md
Normal file
398
04 Advanced OpenGL/06 Cubemaps.md
Normal file
@@ -0,0 +1,398 @@
|
||||
# 立方体贴图(Cubemap)
|
||||
|
||||
原文 | [Cubemaps](http://learnopengl.com/#!Advanced-OpenGL/Cubemaps)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
我们之前一直使用的是2D纹理,还有更多的纹理类型我们没有探索过,本教程中我们讨论的纹理类型是将多个纹理组合起来映射到一个单一纹理,它就是cubemap。
|
||||
|
||||
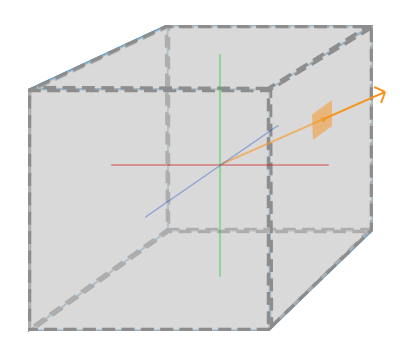
基本上说cubemap它包含6个2D纹理,这每个2D纹理是一个立方体(cube)的一个面,也就是说它是一个有贴图的立方体。你可能会奇怪这样的立方体有什么用?为什么费事地把6个独立纹理结合为一个单独的纹理,只使用6个各自独立的不行吗?这是因为cubemap有自己特有的属性,可以使用方向向量对它们索引和采样。想象一下,我们有一个1×1×1的单位立方体,有个以原点为起点的方向向量在它的中心。
|
||||
|
||||
从cubemap上使用橘黄色向量采样一个纹理值看起来和下图有点像:
|
||||
|
||||
|
||||
|
||||
!!! Important
|
||||
|
||||
方向向量的大小无关紧要。一旦提供了方向,OpenGL就会获取方向向量触碰到立方体表面上的相应的纹理像素(texel),这样就返回了正确的纹理采样值。
|
||||
|
||||
|
||||
方向向量触碰到立方体表面的一点也就是cubemap的纹理位置,这意味着只要立方体的中心位于原点上,我们就可以使用立方体的位置向量来对cubemap进行采样。然后我们就可以获取所有顶点的纹理坐标,就和立方体上的顶点位置一样。所获得的结果是一个纹理坐标,通过这个纹理坐标就能获取到cubemap上正确的纹理。
|
||||
|
||||
### 创建一个Cubemap
|
||||
|
||||
Cubemap和其他纹理一样,所以要创建一个cubemap,在进行任何纹理操作之前,需要生成一个纹理,激活相应纹理单元然后绑定到合适的纹理目标上。这次要绑定到 `GL_TEXTURE_CUBE_MAP`纹理类型:
|
||||
|
||||
```c++
|
||||
GLuint textureID;
|
||||
glGenTextures(1, &textureID);
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, textureID);
|
||||
```
|
||||
|
||||
由于cubemap包含6个纹理,立方体的每个面一个纹理,我们必须调用`glTexImage2D`函数6次,函数的参数和前面教程讲的相似。然而这次我们必须把纹理目标(target)参数设置为cubemap特定的面,这是告诉OpenGL我们创建的纹理是对应立方体哪个面的。因此我们便需要为cubemap的每个面调用一次 `glTexImage2D`。
|
||||
|
||||
由于cubemap有6个面,OpenGL就提供了6个不同的纹理目标,来应对cubemap的各个面。
|
||||
|
||||
纹理目标(Texture target) | 方位
|
||||
---|---
|
||||
GL_TEXTURE_CUBE_MAP_POSITIVE_X | 右
|
||||
GL_TEXTURE_CUBE_MAP_NEGATIVE_X | 左
|
||||
GL_TEXTURE_CUBE_MAP_POSITIVE_Y | 上
|
||||
GL_TEXTURE_CUBE_MAP_NEGATIVE_Y | 下
|
||||
GL_TEXTURE_CUBE_MAP_POSITIVE_Z | 后
|
||||
GL_TEXTURE_CUBE_MAP_NEGATIVE_Z | 前
|
||||
|
||||
和很多OpenGL其他枚举一样,对应的int值都是连续增加的,所以我们有一个纹理位置的数组或vector,就能以 `GL_TEXTURE_CUBE_MAP_POSITIVE_X`为起始来对它们进行遍历,每次迭代枚举值加 `1`,这样循环所有的纹理目标效率较高:
|
||||
|
||||
```c++
|
||||
int width,height;
|
||||
unsigned char* image;
|
||||
for(GLuint i = 0; i < textures_faces.size(); i++)
|
||||
{
|
||||
image = SOIL_load_image(textures_faces[i], &width, &height, 0, SOIL_LOAD_RGB);
|
||||
glTexImage2D(
|
||||
GL_TEXTURE_CUBE_MAP_POSITIVE_X + i,
|
||||
0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, image
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
这儿我们有个vector叫`textures_faces`,它包含cubemap所各个纹理的文件路径,并且以上表所列的顺序排列。它将为每个当前绑定的cubemp的每个面生成一个纹理。
|
||||
|
||||
由于cubemap和其他纹理没什么不同,我们也要定义它的环绕方式和过滤方式:
|
||||
|
||||
```c++
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
|
||||
```
|
||||
|
||||
别被 `GL_TEXTURE_WRAP_R`吓到,它只是简单的设置了纹理的R坐标,R坐标对应于纹理的第三个维度(就像位置的z一样)。我们把放置方式设置为 `GL_CLAMP_TO_EDGE` ,由于纹理坐标在两个面之间,所以可能并不能触及哪个面(由于硬件限制),因此使用 `GL_CLAMP_TO_EDGE` 后OpenGL会返回它们的边界的值,尽管我们可能在两个两个面中间进行的采样。
|
||||
|
||||
在绘制物体之前,将使用cubemap,而在渲染前我们要激活相应的纹理单元并绑定到cubemap上,这和普通的2D纹理没什么区别。
|
||||
|
||||
在片段着色器中,我们也必须使用一个不同的采样器——**samplerCube**,用它来从`texture`函数中采样,但是这次使用的是一个`vec3`方向向量,取代`vec2`。下面是一个片段着色器使用了cubemap的例子:
|
||||
|
||||
```c++
|
||||
in vec3 textureDir; // 用一个三维方向向量来表示Cubemap纹理的坐标
|
||||
|
||||
uniform samplerCube cubemap; // Cubemap纹理采样器
|
||||
|
||||
void main()
|
||||
{
|
||||
color = texture(cubemap, textureDir);
|
||||
}
|
||||
```
|
||||
|
||||
看起来不错,但是何必这么做呢?因为恰巧使用cubemap可以简单的实现很多有意思的技术。其中之一便是著名的**天空盒(Skybox)**。
|
||||
|
||||
|
||||
|
||||
## 天空盒(Skybox)
|
||||
|
||||
天空盒是一个包裹整个场景的立方体,它由6个图像构成一个环绕的环境,给玩家一种他所在的场景比实际的要大得多的幻觉。比如有些在视频游戏中使用的天空盒的图像是群山、白云或者满天繁星。比如下面的夜空繁星的图像就来自《上古卷轴》:
|
||||
|
||||

|
||||
|
||||
你现在可能已经猜到cubemap完全满足天空盒的要求:我们有一个立方体,它有6个面,每个面需要一个贴图。上图中使用了几个夜空的图片给予玩家一种置身广袤宇宙的感觉,可实际上,他还是在一个小盒子之中。
|
||||
|
||||
网上有很多这样的天空盒的资源。[这个网站](http://www.custommapmakers.org/skyboxes.php)就提供了很多。这些天空盒图像通常有下面的样式:
|
||||
|
||||

|
||||
|
||||
如果你把这6个面折叠到一个立方体中,你机会获得模拟了一个巨大的风景的立方体。有些资源所提供的天空盒比如这个例子6个图是连在一起的,你必须手工它们切割出来,不过大多数情况它们都是6个单独的纹理图像。
|
||||
|
||||
这个细致(高精度)的天空盒就是我们将在场景中使用的那个,你可以[在这里下载](http://learnopengl.com/img/textures/skybox.rar)。
|
||||
|
||||
### 加载一个天空盒
|
||||
|
||||
由于天空盒实际上就是一个cubemap,加载天空盒和之前我们加载cubemap的没什么大的不同。为了加载天空盒我们将使用下面的函数,它接收一个包含6个纹理文件路径的vector:
|
||||
|
||||
```c++
|
||||
GLuint loadCubemap(vector<const GLchar*> faces)
|
||||
{
|
||||
GLuint textureID;
|
||||
glGenTextures(1, &textureID);
|
||||
glActiveTexture(GL_TEXTURE0);
|
||||
|
||||
int width,height;
|
||||
unsigned char* image;
|
||||
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, textureID);
|
||||
for(GLuint i = 0; i < faces.size(); i++)
|
||||
{
|
||||
image = SOIL_load_image(faces[i], &width, &height, 0, SOIL_LOAD_RGB);
|
||||
glTexImage2D(
|
||||
GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0,
|
||||
GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, image
|
||||
);
|
||||
}
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
|
||||
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, 0);
|
||||
|
||||
return textureID;
|
||||
}
|
||||
```
|
||||
|
||||
这个函数没什么特别之处。这就是我们前面已经见过的cubemap代码,只不过放进了一个可管理的函数中。
|
||||
|
||||
然后,在我们调用这个函数之前,我们将把合适的纹理路径加载到一个vector之中,顺序还是按照cubemap枚举的特定顺序:
|
||||
|
||||
```c++
|
||||
vector<const GLchar*> faces;
|
||||
faces.push_back("right.jpg");
|
||||
faces.push_back("left.jpg");
|
||||
faces.push_back("top.jpg");
|
||||
faces.push_back("bottom.jpg");
|
||||
faces.push_back("back.jpg");
|
||||
faces.push_back("front.jpg");
|
||||
GLuint cubemapTexture = loadCubemap(faces);
|
||||
```
|
||||
|
||||
现在我们已经用`cubemapTexture`作为id把天空盒加载为cubemap。我们现在可以把它绑定到一个立方体来替换不完美的`clear color`,在前面的所有教程中这个东西做背景已经很久了。
|
||||
|
||||
|
||||
|
||||
### 天空盒的显示
|
||||
|
||||
因为天空盒绘制在了一个立方体上,我们还需要另一个VAO、VBO以及一组全新的顶点,和任何其他物体一样。你可以[从这里获得顶点数据](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps_skybox_data)。
|
||||
|
||||
cubemap用于给3D立方体帖上纹理,可以用立方体的位置作为纹理坐标进行采样。当一个立方体的中心位于原点(0,0,0)的时候,它的每一个位置向量也就是以原点为起点的方向向量。这个方向向量就是我们要得到的立方体某个位置的相应纹理值。出于这个理由,我们只需要提供位置向量,而无需纹理坐标。为了渲染天空盒,我们需要一组新着色器,它们不会太复杂。因为我们只有一个顶点属性,顶点着色器非常简单:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
out vec3 TexCoords;
|
||||
|
||||
uniform mat4 projection;
|
||||
uniform mat4 view;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * vec4(position, 1.0);
|
||||
TexCoords = position;
|
||||
}
|
||||
```
|
||||
|
||||
注意,顶点着色器有意思的地方在于我们把输入的位置向量作为输出给片段着色器的纹理坐标。片段着色器就会把它们作为输入去采样samplerCube:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
in vec3 TexCoords;
|
||||
out vec4 color;
|
||||
|
||||
uniform samplerCube skybox;
|
||||
|
||||
void main()
|
||||
{
|
||||
color = texture(skybox, TexCoords);
|
||||
}
|
||||
```
|
||||
|
||||
片段着色器比较明了,我们把顶点属性中的位置向量作为纹理的方向向量,使用它们从cubemap采样纹理值。渲染天空盒现在很简单,我们有了一个cubemap纹理,我们简单绑定cubemap纹理,天空盒就自动地用天空盒的cubemap填充了。为了绘制天空盒,我们将把它作为场景中第一个绘制的物体并且关闭深度写入。这样天空盒才能成为所有其他物体的背景来绘制出来。
|
||||
|
||||
```c++
|
||||
|
||||
glDepthMask(GL_FALSE);
|
||||
skyboxShader.Use();
|
||||
// ... Set view and projection matrix
|
||||
glBindVertexArray(skyboxVAO);
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, cubemapTexture);
|
||||
glDrawArrays(GL_TRIANGLES, 0, 36);
|
||||
glBindVertexArray(0);
|
||||
glDepthMask(GL_TRUE);
|
||||
// ... Draw rest of the scene
|
||||
```
|
||||
|
||||
如果你运行程序就会陷入困境,我们希望天空盒以玩家为中心,这样无论玩家移动了多远,天空盒都不会变近,这样就产生一种四周的环境真的非常大的印象。当前的视图矩阵对所有天空盒的位置进行了转转缩放和平移变换,所以玩家移动,cubemap也会跟着移动!我们打算移除视图矩阵的平移部分,这样移动就影响不到天空盒的位置向量了。在基础光照教程里我们提到过我们可以只用4X4矩阵的3×3部分去除平移。我们可以简单地将矩阵转为33矩阵再转回来,就能达到目标
|
||||
|
||||
```c++
|
||||
glm::mat4 view = glm::mat4(glm::mat3(camera.GetViewMatrix()));
|
||||
```
|
||||
|
||||
这会移除所有平移,但保留所有旋转,因此用户仍然能够向四面八方看。由于有了天空盒,场景即可变得巨大了。如果你添加些物体然后自由在其中游荡一会儿你会发现场景的真实度有了极大提升。最后的效果看起来像这样:
|
||||
|
||||
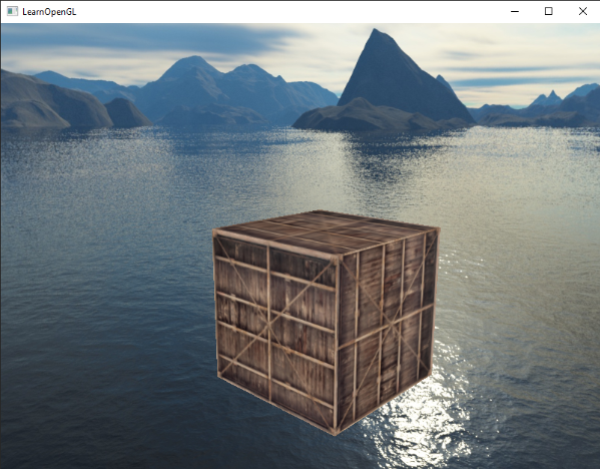
|
||||
|
||||
[这里有全部源码](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps_skybox),你可以对比一下你写的。
|
||||
|
||||
尝试用不同的天空盒实验,看看它们对场景有多大影响。
|
||||
|
||||
### 优化
|
||||
|
||||
现在我们在渲染场景中的其他物体之前渲染了天空盒。这么做没错,但是不怎么高效。如果我们先渲染了天空盒,那么我们就是在为每一个屏幕上的像素运行片段着色器,即使天空盒只有部分在显示着;fragment可以使用前置深度测试(early depth testing)简单地被丢弃,这样就节省了我们宝贵的带宽。
|
||||
|
||||
所以最后渲染天空盒就能够给我们带来轻微的性能提升。采用这种方式,深度缓冲被全部物体的深度值完全填充,所以我们只需要渲染通过前置深度测试的那部分天空的片段就行了,而且能显著减少片段着色器的调用。问题是天空盒是个1×1×1的立方体,极有可能会渲染失败,因为极有可能通不过深度测试。简单地不用深度测试渲染它也不是解决方案,这是因为天空盒会在之后覆盖所有的场景中其他物体。我们需要耍个花招让深度缓冲相信天空盒的深度缓冲有着最大深度值1.0,如此只要有个物体存在深度测试就会失败,看似物体就在它前面了。
|
||||
|
||||
在坐标系教程中我们说过,透视除法(perspective division)是在顶点着色器运行之后执行的,把`gl_Position`的xyz坐标除以w元素。我们从深度测试教程了解到除法结果的z元素等于顶点的深度值。利用这个信息,我们可以把输出位置的z元素设置为它的w元素,这样就会导致z元素等于1.0了,因为,当透视除法应用后,它的z元素转换为w/w = 1.0:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
vec4 pos = projection * view * vec4(position, 1.0);
|
||||
gl_Position = pos.xyww;
|
||||
TexCoords = position;
|
||||
}
|
||||
```
|
||||
|
||||
最终,标准化设备坐标就总会有个与1.0相等的z值了,1.0就是深度值的最大值。只有在没有任何物体可见的情况下天空盒才会被渲染(只有通过深度测试才渲染,否则假如有任何物体存在,就不会被渲染,只去渲染物体)。
|
||||
|
||||
我们必须改变一下深度方程,把它设置为`GL_LEQUAL`,原来默认的是`GL_LESS`。深度缓冲会为天空盒用1.0这个值填充深度缓冲,所以我们需要保证天空盒是使用小于等于深度缓冲来通过深度测试的,而不是小于。
|
||||
|
||||
你可以在这里找到优化过的版本的[源码](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps_skybox_optimized)。
|
||||
|
||||
### 环境映射
|
||||
|
||||
我们现在有了一个把整个环境映射到为一个单独纹理的对象,我们利用这个信息能做的不仅是天空盒。使用带有场景环境的cubemap,我们还可以让物体有一个反射或折射属性。像这样使用了环境cubemap的技术叫做**环境贴图技术**,其中最重要的两个是**反射(reflection)**和**折射(refraction)**。
|
||||
|
||||
#### 反射(reflection)
|
||||
|
||||
凡是是一个物体(或物体的某部分)反射他周围的环境的属性,比如物体的颜色多少有些等于它周围的环境,这要基于观察者的角度。例如一个镜子是一个反射物体:它会基于观察者的角度泛着它周围的环境。
|
||||
|
||||
反射的基本思路不难。下图展示了我们如何计算反射向量,然后使用这个向量去从一个cubemap中采样:
|
||||
|
||||

|
||||
|
||||
我们基于观察方向向量I和物体的法线向量N计算出反射向量R。我们可以使用GLSL的内建函数reflect来计算这个反射向量。最后向量R作为一个方向向量对cubemap进行索引/采样,返回一个环境的颜色值。最后的效果看起来就像物体反射了天空盒。
|
||||
|
||||
因为我们在场景中已经设置了一个天空盒,创建反射就不难了。我们改变一下箱子使用的那个片段着色器,给箱子一个反射属性:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
in vec3 Normal;
|
||||
in vec3 Position;
|
||||
out vec4 color;
|
||||
|
||||
uniform vec3 cameraPos;
|
||||
uniform samplerCube skybox;
|
||||
|
||||
void main()
|
||||
{
|
||||
vec3 I = normalize(Position - cameraPos);
|
||||
vec3 R = reflect(I, normalize(Normal));
|
||||
color = texture(skybox, R);
|
||||
}
|
||||
```
|
||||
|
||||
我们先来计算观察/摄像机方向向量I,然后使用它来计算反射向量R,接着我们用R从天空盒cubemap采样。要注意的是,我们有了片段的插值Normal和Position变量,所以我们需要修正顶点着色器适应它。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
layout (location = 1) in vec3 normal;
|
||||
|
||||
out vec3 Normal;
|
||||
out vec3 Position;
|
||||
|
||||
uniform mat4 model;
|
||||
uniform mat4 view;
|
||||
uniform mat4 projection;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0f);
|
||||
Normal = mat3(transpose(inverse(model))) * normal;
|
||||
Position = vec3(model * vec4(position, 1.0f));
|
||||
}
|
||||
```
|
||||
|
||||
我们用了法线向量,所以我们打算使用一个**法线矩阵(normal matrix)**变换它们。`Position`输出的向量是一个世界空间位置向量。顶点着色器输出的`Position`用来在片段着色器计算观察方向向量。
|
||||
|
||||
因为我们使用法线,你还得更新顶点数据,更新属性指针。还要确保设置`cameraPos`的uniform。
|
||||
|
||||
然后在渲染箱子前我们还得绑定cubemap纹理:
|
||||
|
||||
```c++
|
||||
glBindVertexArray(cubeVAO);
|
||||
glBindTexture(GL_TEXTURE_CUBE_MAP, skyboxTexture);
|
||||
glDrawArrays(GL_TRIANGLES, 0, 36);
|
||||
glBindVertexArray(0);
|
||||
```
|
||||
|
||||
编译运行你的代码,你等得到一个镜子一样的箱子。箱子完美地反射了周围的天空盒:
|
||||
|
||||
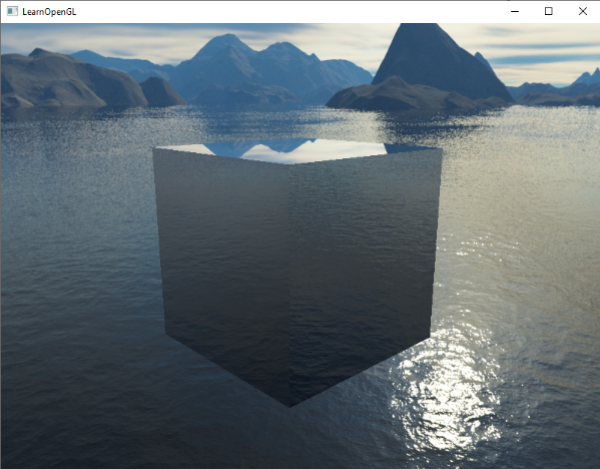
|
||||
|
||||
你可以[从这里找到全部源代码](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps_reflection)。
|
||||
|
||||
当反射应用于整个物体之上的时候,物体看上去就像有一个像钢和铬这种高反射材质。如果我们加载[模型教程](http://learnopengl-cn.readthedocs.org/zh/latest/03%20Model%20Loading/03%20Model/)中的纳米铠甲模型,我们就会获得一个铬金属制铠甲:
|
||||
|
||||

|
||||
|
||||
看起来挺惊艳,但是现实中大多数模型都不是完全反射的。我们可以引进反射贴图(reflection map)来使模型有另一层细节。和diffuse、specular贴图一样,我们可以从反射贴图上采样来决定fragment的反射率。使用反射贴图我们还可以决定模型的哪个部分有反射能力,以及强度是多少。本节的练习中,要由你来在我们早期创建的模型加载器引入反射贴图,这回极大的提升纳米服模型的细节。
|
||||
|
||||
#### 折射(refraction)
|
||||
|
||||
环境映射的另一个形式叫做折射,它和反射差不多。折射是光线通过特定材质对光线方向的改变。我们通常看到像水一样的表面,光线并不是直接通过的,而是让光线弯曲了一点。它看起来像你把半只手伸进水里的效果。
|
||||
|
||||
折射遵守[斯涅尔定律](http://en.wikipedia.org/wiki/Snell%27s_law),使用环境贴图看起来就像这样:
|
||||
|
||||
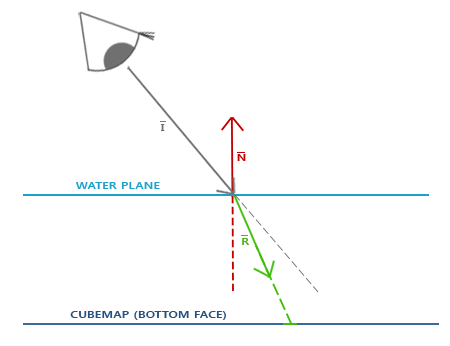
|
||||
|
||||
我们有个观察向量I,一个法线向量N,这次折射向量是R。就像你所看到的那样,观察向量的方向有轻微弯曲。弯曲的向量R随后用来从cubemap上采样。
|
||||
|
||||
折射可以通过GLSL的内建函数refract来实现,除此之外还需要一个法线向量,一个观察方向和一个两种材质之间的折射指数。
|
||||
|
||||
折射指数决定了一个材质上光线扭曲的数量,每个材质都有自己的折射指数。下表是常见的折射指数:
|
||||
|
||||
材质 | 折射指数
|
||||
---|---
|
||||
空气 | 1.00
|
||||
水 | 1.33
|
||||
冰 | 1.309
|
||||
玻璃 | 1.52
|
||||
宝石 | 2.42
|
||||
|
||||
我们使用这些折射指数来计算光线通过两个材质的比率。在我们的例子中,光线/视线从空气进入玻璃(如果我们假设箱子是玻璃做的)所以比率是1.001.52 = 0.658。
|
||||
|
||||
我们已经绑定了cubemap,提供了定点数据,设置了摄像机位置的uniform。现在只需要改变片段着色器:
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
float ratio = 1.00 / 1.52;
|
||||
vec3 I = normalize(Position - cameraPos);
|
||||
vec3 R = refract(I, normalize(Normal), ratio);
|
||||
color = texture(skybox, R);
|
||||
}
|
||||
```
|
||||
|
||||
通过改变折射指数你可以创建出完全不同的视觉效果。编译运行应用,结果也不是太有趣,因为我们只是用了一个普通箱子,这不能显示出折射的效果,看起来像个放大镜。使用同一个着色器,纳米服模型却可以展示出我们期待的效果:玻璃制物体。
|
||||
|
||||

|
||||
|
||||
你可以向想象一下,如果将光线、反射、折射和顶点的移动合理的结合起来就能创造出漂亮的水的图像。一定要注意,出于物理精确的考虑当光线离开物体的时候还要再次进行折射;现在我们简单的使用了单边(一次)折射,大多数目的都可以得到满足。
|
||||
|
||||
#### 动态环境贴图(Dynamic environment maps)
|
||||
|
||||
现在,我们已经使用了静态图像组合的天空盒,看起来不错,但是没有考虑到物体可能移动的实际场景。我们到现在还没注意到这点,是因为我们目前还只使用了一个物体。如果我们有个镜子一样的物体,它周围有多个物体,只有天空盒在镜子中可见,和场景中只有这一个物体一样。
|
||||
|
||||
使用帧缓冲可以为提到的物体的所有6个不同角度创建一个场景的纹理,把它们每次渲染迭代储存为一个cubemap。之后我们可以使用这个(动态生成的)cubemap来创建真实的反射和折射表面,这样就能包含所有其他物体了。这种方法叫做动态环境映射(dynamic environment mapping),因为我们动态地创建了一个物体的以其四周为参考的cubemap,并把它用作环境贴图。
|
||||
|
||||
它看起效果很好,但是有一个劣势:使用环境贴图我们必须为每个物体渲染场景6次,这需要非常大的开销。现代应用尝试尽量使用天空盒子,凡可能预编译cubemap就创建少量动态环境贴图。动态环境映射是个非常棒的技术,要想在不降低执行效率的情况下实现它就需要很多巧妙的技巧。
|
||||
|
||||
|
||||
|
||||
## 练习
|
||||
|
||||
尝试在模型加载中引进反射贴图,你将再次得到很大视觉效果的提升。这其中有几点需要注意:
|
||||
|
||||
- Assimp并不支持反射贴图,我们可以使用环境贴图的方式将反射贴图从`aiTextureType_AMBIENT`类型中来加载反射贴图的材质。
|
||||
- 我匆忙地使用反射贴图来作为镜面反射的贴图,而反射贴图并没有很好的映射在模型上:)。
|
||||
- 由于加载模型已经占用了3个纹理单元,因此你要绑定天空盒到第4个纹理单元上,这样才能在同一个着色器内从天空盒纹理中取样。
|
||||
|
||||
You can find the solution source code here together with the updated model and mesh class. The shaders used for rendering the reflection maps can be found here: vertex shader and fragment shader.
|
||||
|
||||
你可以在此获取解决方案的[源代码](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps-exercise1),这其中还包括升级过的[Model](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps-exercise1-model)和[Mesh](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps-exercise1-mesh)类,还有用来绘制反射贴图的[顶点着色器](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps-exercise1-vertex)和[片段着色器](http://learnopengl.com/code_viewer.php?code=advanced/cubemaps-exercise1-fragment)。
|
||||
|
||||
如果你一切都做对了,那你应该看到和下图类似的效果:
|
||||
|
||||

|
||||
107
04 Advanced OpenGL/07 Advanced Data.md
Normal file
107
04 Advanced OpenGL/07 Advanced Data.md
Normal file
@@ -0,0 +1,107 @@
|
||||
# 高级数据
|
||||
|
||||
原文 | [Advanced Data](http://learnopengl.com/#!Advanced-OpenGL/Advanced-Data)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
## 缓冲数据写入
|
||||
|
||||
我们在OpenGL中大量使用缓冲来储存数据已经有一会儿了。有一些有趣的方式来操纵缓冲,也有一些有趣的方式通过纹理来向着色器传递大量数据。本教程中,我们会讨论一些更加有意思的缓冲函数,以及如何使用纹理对象来储存大量数据(教程中纹理部分还没写)。
|
||||
|
||||
OpenGL中缓冲只是一块儿内存区域的对象,除此没有更多点的了。当把缓冲绑定到一个特定缓冲对象的时候,我们就给缓冲赋予了一个特殊的意义。当我们绑定到`GL_ARRAY_BUFFER`的时候,这个缓冲就是一个顶点数组缓冲,我们也可以简单地绑定到`GL_ELEMENT_ARRAY_BUFFER`。OpenGL内部为每个目标(target)储存一个缓冲,并基于目标来处理不同的缓冲。
|
||||
|
||||
到目前为止,我们使用`glBufferData`函数填充缓冲对象管理的内存,这个函数分配了一块内存空间,然后把数据存入其中。如果我们向它的`data`这个参数传递的是NULL,那么OpenGL只会帮我们分配内存,而不会填充它。如果我们先打算开辟一些内存,稍后回到这个缓冲一点一点的填充数据,有些时候会很有用。
|
||||
|
||||
我们还可以调用`glBufferSubData`函数填充特定区域的缓冲,而不是一次填充整个缓冲。这个函数需要一个缓冲目标(target),一个偏移量(offset),数据的大小以及数据本身作为参数。这个函数新的功能是我们可以给它一个偏移量(offset)来指定我们打算填充缓冲的位置与起始位置之间的偏移量。这样我们就可以插入/更新指定区域的缓冲内存空间了。一定要确保修改的缓冲要有足够的内存分配,所以在调用`glBufferSubData`之前,调用`glBufferData`是必须的。
|
||||
|
||||
```c++
|
||||
glBufferSubData(GL_ARRAY_BUFFER, 24, sizeof(data), &data); // 范围: [24, 24 + sizeof(data)]
|
||||
```
|
||||
|
||||
把数据传进缓冲另一个方式是向缓冲内存请求一个指针,你自己直接把数据复制到缓冲中。调用`glMapBuffer`函数OpenGL会返回一个当前绑定缓冲的内存的地址,供我们操作:
|
||||
|
||||
```c++
|
||||
float data[] = {
|
||||
0.5f, 1.0f, -0.35f
|
||||
...
|
||||
};
|
||||
|
||||
glBindBuffer(GL_ARRAY_BUFFER, buffer);
|
||||
// 获取当前绑定缓存buffer的内存地址
|
||||
void* ptr = glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY);
|
||||
// 向缓冲中写入数据
|
||||
memcpy(ptr, data, sizeof(data));
|
||||
// 完成够别忘了告诉OpenGL我们不再需要它了
|
||||
glUnmapBuffer(GL_ARRAY_BUFFER);
|
||||
```
|
||||
|
||||
调用`glUnmapBuffer`函数可以告诉OpenGL我们已经用完指针了,OpenGL会知道你已经做完了。通过解映射(unmapping),指针会不再可用,如果OpenGL可以把你的数据映射到缓冲上,就会返回`GL_TRUE`。
|
||||
|
||||
把数据直接映射到缓冲上使用`glMapBuffer`很有用,因为不用把它储存在临时内存里。你可以从文件读取数据然后直接复制到缓冲的内存里。
|
||||
|
||||
## 分批处理顶点属性
|
||||
|
||||
使用`glVertexAttribPointer`函数可以指定缓冲内容的顶点数组的属性的布局(layout)。我们已经知道,通过使用顶点属性指针我们可以交叉属性,也就是说我们可以把每个顶点的位置、法线、纹理坐标放在彼此挨着的地方。现在我们了解了更多的缓冲的内容,可以采取另一种方式了。
|
||||
|
||||
我们可以做的是把每种类型的属性的所有向量数据批量保存在一个布局,而不是交叉布局。与交叉布局123123123123不同,我们采取批量方式111122223333。
|
||||
|
||||
当从文件加载顶点数据时你通常获取一个位置数组,一个法线数组和一个纹理坐标数组。需要花点力气才能把它们结合为交叉数据。使用`glBufferSubData`可以简单的实现分批处理方式:
|
||||
|
||||
```c++
|
||||
GLfloat positions[] = { ... };
|
||||
GLfloat normals[] = { ... };
|
||||
GLfloat tex[] = { ... };
|
||||
// 填充缓冲
|
||||
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(positions), &positions);
|
||||
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions), sizeof(normals), &normals);
|
||||
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions) + sizeof(normals), sizeof(tex), &tex);
|
||||
```
|
||||
|
||||
这样我们可以把属性数组当作一个整体直接传输给缓冲,不需要再处理它们了。我们还可以把它们结合为一个更大的数组然后使用`glBufferData`立即直接填充它,不过对于这项任务使用`glBufferSubData`是更好的选择。
|
||||
|
||||
我们还要更新顶点属性指针来反应这些改变:
|
||||
|
||||
```c++
|
||||
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat), 0);
|
||||
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat), (GLvoid*)(sizeof(positions)));
|
||||
glVertexAttribPointer(
|
||||
2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(GLfloat), (GLvoid*)(sizeof(positions) + sizeof(normals)));
|
||||
```
|
||||
|
||||
注意,`stride`参数等于顶点属性的大小,由于同类型的属性是连续储存的,所以下一个顶点属性向量可以在它的后面3(或2)的元素那儿找到。
|
||||
|
||||
这是我们有了另一种设置和指定顶点属性的方式。使用哪个方式对OpenGL来说也不会有立竿见影的效果,这只是一种采用更加组织化的方式去设置顶点属性。选用哪种方式取决于你的偏好和应用类型。
|
||||
|
||||
## 复制缓冲
|
||||
|
||||
当你的缓冲被数据填充以后,你可能打算让其他缓冲能分享这些数据或者打算把缓冲的内容复制到另一个缓冲里。`glCopyBufferSubData`函数让我们能够相对容易地把一个缓冲的数据复制到另一个缓冲里。函数的原型是:
|
||||
|
||||
```c++
|
||||
void glCopyBufferSubData(GLenum readtarget, GLenum writetarget, GLintptr readoffset, GLintptr writeoffset, GLsizeiptr size);
|
||||
```
|
||||
|
||||
`readtarget`和`writetarget`参数是复制的来源和目的的缓冲目标。例如我们可以从一个`VERTEX_ARRAY_BUFFER`复制到一个`VERTEX_ELEMENT_ARRAY_BUFFER`,各自指定源和目的的缓冲目标。当前绑定到这些缓冲目标上的缓冲会被影响到。
|
||||
|
||||
但如果我们打算读写的两个缓冲都是顶点数组缓冲(`GL_VERTEX_ARRAY_BUFFER`)怎么办?我们不能用通一个缓冲作为操作的读取和写入目标次。出于这个理由,OpenGL给了我们另外两个缓冲目标叫做:`GL_COPY_READ_BUFFER`和`GL_COPY_WRITE_BUFFER`。这样我们就可以把我们选择的缓冲,用上面二者作为`readtarget`和`writetarget`的参数绑定到新的缓冲目标上了。
|
||||
|
||||
接着`glCopyBufferSubData`函数会从readoffset处读取的size大小的数据,写入到writetarget缓冲的writeoffset位置。下面是一个复制两个顶点数组缓冲的例子:
|
||||
|
||||
```c++
|
||||
GLfloat vertexData[] = { ... };
|
||||
glBindBuffer(GL_COPY_READ_BUFFER, vbo1);
|
||||
glBindBuffer(GL_COPY_WRITE_BUFFER, vbo2);
|
||||
glCopyBufferSubData(GL_COPY_READ_BUFFER, GL_COPY_WRITE_BUFFER, 0, 0, sizeof(vertexData));
|
||||
```
|
||||
|
||||
我们也可以把`writetarget`缓冲绑定为新缓冲目标类型其中之一:
|
||||
|
||||
```c++
|
||||
GLfloat vertexData[] = { ... };
|
||||
glBindBuffer(GL_ARRAY_BUFFER, vbo1);
|
||||
glBindBuffer(GL_COPY_WRITE_BUFFER, vbo2);
|
||||
glCopyBufferSubData(GL_ARRAY_BUFFER, GL_COPY_WRITE_BUFFER, 0, 0, sizeof(vertexData));
|
||||
```
|
||||
|
||||
有了这些额外的关于如何操纵缓冲的知识,我们已经可以以更有趣的方式来使用它们了。当你对OpenGL更熟悉,这些新缓冲方法就变得更有用。下个教程中我们会讨论unform缓冲对象,彼时我们会充分利用`glBufferSubData`。
|
||||
470
04 Advanced OpenGL/08 Advanced GLSL.md
Normal file
470
04 Advanced OpenGL/08 Advanced GLSL.md
Normal file
@@ -0,0 +1,470 @@
|
||||
# 高级GLSL
|
||||
|
||||
原文 | [Advanced GLSL](http://learnopengl.com/#!Advanced-OpenGL/Advanced-GLSL)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
|
||||
这章不会向你展示什么新的功能,也不会对你的场景的视觉效果有较大提升。本文多多少少地深入探讨了一些GLSL有趣的知识,它们可能在将来能帮助你。基本来说有些不可不知的内容和功能在你去使用GLSL创建OpenGL应用的时候能让你的生活更轻松。
|
||||
|
||||
我们会讨论一些内建变量、组织着色器输入和输出的新方式以及一个叫做uniform缓冲对象的非常有用的工具。
|
||||
|
||||
## GLSL的内建变量
|
||||
|
||||
着色器是很小的,如果我们需要从当前着色器以外的别的资源里的数据,那么我们就不得不传给它。我们学过了使用顶点属性、uniform和采样器可以实现这个目标。GLSL有几个以**gl\_**为前缀的变量,使我们有一个额外的手段来获取和写入数据。其中两个我们已经打过交道了:`gl_Position`和`gl_FragCoord`,前一个是顶点着色器的输出向量,后一个是片段着色器的变量。
|
||||
|
||||
我们会讨论几个有趣的GLSL内建变量,并向你解释为什么它们对我们来说很有好处。注意,我们不会讨论到GLSL中所有的内建变量,因此如果你想看到所有的内建变量还是最好去查看[OpenGL的wiki](http://www.opengl.org/wiki/Built-in_Variable_(GLSL)。
|
||||
|
||||
### 顶点着色器变量
|
||||
|
||||
#### gl_Position
|
||||
|
||||
我们已经了解`gl_Position`是顶点着色器裁切空间输出的位置向量。如果你想让屏幕上渲染出东西`gl_Position`必须使用。否则我们什么都看不到。
|
||||
|
||||
#### gl_PointSize
|
||||
|
||||
我们可以使用的另一个可用于渲染的基本图形(primitive)是**GL\_POINTS**,使用它每个顶点作为一个基本图形,被渲染为一个点(point)。可以使用`glPointSize`函数来设置这个点的大小,但我们还可以在顶点着色器里修改点的大小。
|
||||
|
||||
GLSL有另一个输出变量叫做`gl_PointSize`,他是一个`float`变量,你可以以像素的方式设置点的高度和宽度。它在着色器中描述每个顶点做为点被绘制出来的大小。
|
||||
|
||||
在着色器中影响点的大小默认是关闭的,但是如果你打算开启它,你需要开启OpenGL的`GL_PROGRAM_POINT_SIZE`:
|
||||
|
||||
```c++
|
||||
glEnable(GL_PROGRAM_POINT_SIZE);
|
||||
```
|
||||
|
||||
把点的大小设置为裁切空间的z值,这样点的大小就等于顶点距离观察者的距离,这是一种影响点的大小的方式。当顶点距离观察者更远的时候,它就会变得更大。
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0f);
|
||||
gl_PointSize = gl_Position.z;
|
||||
}
|
||||
```
|
||||
|
||||
结果是我们绘制的点距离我们越远就越大:
|
||||
|
||||
|
||||
|
||||
想象一下,每个顶点表示出来的点的大小的不同,如果用在像粒子生成之类的技术里会挺有意思的。
|
||||
|
||||
#### gl_VertexID
|
||||
|
||||
`gl_Position`和`gl_PointSize`都是输出变量,因为它们的值是作为顶点着色器的输出被读取的;我们可以向它们写入数据来影响结果。顶点着色器为我们提供了一个有趣的输入变量,我们只能从它那里读取,这个变量叫做`gl_VertexID`。
|
||||
|
||||
`gl_VertexID`是个整型变量,它储存着我们绘制的当前顶点的ID。当进行索引渲染(indexed rendering,使用`glDrawElements`渲染)时,这个变量保存着当前绘制的顶点的索引。当用的不是索引绘制(`glDrawArrays`)时,这个变量保存的是从渲染开始起直到当前处理的这个顶点的(当前顶点)编号。
|
||||
|
||||
尽管目前看似没用,但是我们最好知道我们能获取这样的信息。
|
||||
|
||||
### 片段着色器的变量
|
||||
|
||||
在片段着色器中也有一些有趣的变量。GLSL给我们提供了两个有意思的输入变量,它们是`gl_FragCoord`和`gl_FrontFacing`。
|
||||
|
||||
#### gl_FragCoord
|
||||
|
||||
在讨论深度测试的时候,我们已经看过`gl_FragCoord`好几次了,因为`gl_FragCoord`向量的z元素和特定的fragment的深度值相等。然而,我们也可以使用这个向量的x和y元素来实现一些有趣的效果。
|
||||
|
||||
`gl_FragCoord`的x和y元素是当前片段的窗口空间坐标(window-space coordinate)。它们的起始处是窗口的左下角。如果我们的窗口是800×600的,那么一个片段的窗口空间坐标x的范围就在0到800之间,y在0到600之间。
|
||||
|
||||
我们可以使用片段着色器基于片段的窗口坐标计算出一个不同的颜色。`gl_FragCoord`变量的一个常用的方式是与一个不同的片段计算出来的视频输出进行对比,通常在技术演示中常见。比如我们可以把屏幕分为两个部分,窗口的左侧渲染一个输出,窗口的右边渲染另一个输出。下面是一个基于片段的窗口坐标的位置的不同输出不同的颜色的片段着色器:
|
||||
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
if(gl_FragCoord.x < 400)
|
||||
color = vec4(1.0f, 0.0f, 0.0f, 1.0f);
|
||||
else
|
||||
color = vec4(0.0f, 1.0f, 0.0f, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
因为窗口的宽是800,当一个像素的x坐标小于400,那么它一定在窗口的左边,这样我们就让物体有个不同的颜色。
|
||||
|
||||
|
||||
|
||||
我们现在可以计算出两个完全不同的片段着色器结果,每个显示在窗口的一端。这对于测试不同的光照技术很有好处。
|
||||
|
||||
|
||||
|
||||
#### gl_FrontFacing
|
||||
|
||||
片段着色器另一个有意思的输入变量是`gl_FrontFacing`变量。在面剔除教程中,我们提到过OpenGL可以根据顶点绘制顺序弄清楚一个面是正面还是背面。如果我们不适用面剔除,那么`gl_FrontFacing`变量能告诉我们当前片段是某个正面的一部分还是背面的一部分。然后我们可以决定做一些事情,比如为正面计算出不同的颜色。
|
||||
|
||||
`gl_FrontFacing`变量是一个布尔值,如果当前片段是正面的一部分那么就是true,否则就是false。这样我们可以创建一个立方体,里面和外面使用不同的纹理:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 color;
|
||||
in vec2 TexCoords;
|
||||
|
||||
uniform sampler2D frontTexture;
|
||||
uniform sampler2D backTexture;
|
||||
|
||||
void main()
|
||||
{
|
||||
if(gl_FrontFacing)
|
||||
color = texture(frontTexture, TexCoords);
|
||||
else
|
||||
color = texture(backTexture, TexCoords);
|
||||
}
|
||||
```
|
||||
|
||||
如果我们从箱子的一角往里看,就能看到里面用的是另一个纹理。
|
||||
|
||||

|
||||
|
||||
注意,如果你开启了面剔除,你就看不到箱子里面有任何东西了,所以此时使用`gl_FrontFacing`毫无意义。
|
||||
|
||||
#### gl_FragDepth
|
||||
|
||||
输入变量`gl_FragCoord`让我们可以读得当前片段的窗口空间坐标和深度值,但是它是只读的。我们不能影响到这个片段的窗口屏幕坐标,但是可以设置这个像素的深度值。GLSL给我们提供了一个叫做`gl_FragDepth`的变量,我们可以用它在着色器中遂舍之像素的深度值。
|
||||
|
||||
为了在着色器中设置深度值,我们简单的写一个0.0到1.0之间的float数,赋值给这个输出变量:
|
||||
|
||||
```c++
|
||||
gl_FragDepth = 0.0f; //现在片段的深度值被设为0
|
||||
```
|
||||
|
||||
如果着色器中没有像`gl_FragDepth`变量写入,它就会自动采用`gl_FragCoord.z`的值。
|
||||
|
||||
我们自己设置深度值有一个显著缺点,因为只要我们在片段着色器中对`gl_FragDepth`写入什么,OpenGL就会关闭所有的前置深度测试。它被关闭的原因是,在我们运行片段着色器之前OpenGL搞不清像素的深度值,因为片段着色器可能会完全改变这个深度值。
|
||||
|
||||
因此,你需要考虑到`gl_FragDepth`写入所带来的性能的下降。然而从OpenGL4.2起,我们仍然可以对二者进行一定的调和,这需要在片段着色器的顶部使用深度条件(depth condition)来重新声明`gl_FragDepth`:
|
||||
|
||||
```c++
|
||||
layout (depth_<condition>) out float gl_FragDepth;
|
||||
```
|
||||
|
||||
condition可以使用下面的值:
|
||||
|
||||
Condition | 描述
|
||||
---|---
|
||||
any | 默认值. 前置深度测试是关闭的,你失去了很多性能表现
|
||||
greater |深度值只能比gl_FragCoord.z大
|
||||
less |深度值只能设置得比gl_FragCoord.z小
|
||||
unchanged |如果写入gl_FragDepth, 你就会写gl_FragCoord.z
|
||||
|
||||
如果把深度条件定义为greater或less,OpenGL会假定你只写入比当前的像素深度值的深度值大或小的。
|
||||
|
||||
下面是一个在片段着色器里增加深度值的例子,不过仍可开启前置深度测试:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (depth_greater) out float gl_FragDepth;
|
||||
out vec4 color;
|
||||
|
||||
void main()
|
||||
{
|
||||
color = vec4(1.0f);
|
||||
gl_FragDepth = gl_FragCoord.z + 0.1f;
|
||||
}
|
||||
```
|
||||
|
||||
一定要记住这个功能只在OpenGL4.2以上版本才有。
|
||||
|
||||
|
||||
|
||||
## 接口块(Interface blocks)
|
||||
|
||||
到目前位置,每次我们打算从顶点向片段着色器发送数据,我们都会声明一个相互匹配的输出/输入变量。从一个着色器向另一个着色器发送数据,一次将它们声明好是最简单的方式,但是随着应用变得越来越大,你也许会打算发送的不仅仅是变量,最好还可以包括数组和结构体。
|
||||
|
||||
为了帮助我们组织这些变量,GLSL为我们提供了一些叫做接口块(Interface blocks)的东西,好让我们能够组织这些变量。声明接口块和声明struct有点像,不同之处是它现在基于块(block),使用in和out关键字来声明,最后它将成为一个输入或输出块(block)。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
layout (location = 1) in vec2 texCoords;
|
||||
|
||||
uniform mat4 model;
|
||||
uniform mat4 view;
|
||||
uniform mat4 projection;
|
||||
|
||||
out VS_OUT
|
||||
{
|
||||
vec2 TexCoords;
|
||||
} vs_out;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0f);
|
||||
vs_out.TexCoords = texCoords;
|
||||
}
|
||||
```
|
||||
|
||||
这次我们声明一个叫做vs_out的接口块,它把我们需要发送给下个阶段着色器的所有输出变量组合起来。虽然这是一个微不足道的例子,但是你可以想象一下,它的确能够帮助我们组织着色器的输入和输出。当我们希望把着色器的输入和输出组织成数组的时候它就变得很有用,我们会在下节几何着色器(geometry)中见到。
|
||||
|
||||
然后,我们还需要在下一个着色器——片段着色器中声明一个输入interface block。块名(block name)应该是一样的,但是实例名可以是任意的。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 color;
|
||||
|
||||
in VS_OUT
|
||||
{
|
||||
vec2 TexCoords;
|
||||
} fs_in;
|
||||
|
||||
uniform sampler2D texture;
|
||||
|
||||
void main()
|
||||
{
|
||||
color = texture(texture, fs_in.TexCoords);
|
||||
}
|
||||
```
|
||||
|
||||
如果两个interface block名一致,它们对应的输入和输出就会匹配起来。这是另一个可以帮助我们组织代码的有用功能,特别是在跨着色阶段的情况,比如几何着色器。
|
||||
|
||||
## uniform缓冲对象 (Uniform buffer objects)
|
||||
|
||||
我们使用OpenGL很长时间了,也学到了一些很酷的技巧,但是产生了一些烦恼。比如说,当时用一个以上的着色器的时候,我们必须一次次设置uniform变量,尽管对于每个着色器来说它们都是一样的,所以为什么还麻烦地多次设置它们呢?
|
||||
|
||||
OpenGL为我们提供了一个叫做uniform缓冲对象的工具,使我们能够声明一系列的全局uniform变量, 它们会在几个着色器程序中保持一致。当时用uniform缓冲的对象时相关的uniform只能设置一次。我们仍需为每个着色器手工设置唯一的uniform。创建和配置一个uniform缓冲对象需要费点功夫。
|
||||
|
||||
因为uniform缓冲对象是一个缓冲,因此我们可以使用`glGenBuffers`创建一个,然后绑定到`GL_UNIFORM_BUFFER`缓冲目标上,然后把所有相关uniform数据存入缓冲。有一些原则,像uniform缓冲对象如何储存数据,我们会在稍后讨论。首先我们我们在一个简单的顶点着色器中,用uniform块(uniform block)储存投影和视图矩阵:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
|
||||
layout (std140) uniform Matrices
|
||||
{
|
||||
mat4 projection;
|
||||
mat4 view;
|
||||
};
|
||||
|
||||
uniform mat4 model;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
前面,大多数例子里我们在每次渲染迭代,都为projection和view矩阵设置uniform。这个例子里使用了uniform缓冲对象,这非常有用,因为这些矩阵我们设置一次就行了。
|
||||
|
||||
在这里我们声明了一个叫做Matrices的uniform块,它储存两个4×4矩阵。在uniform块中的变量可以直接获取,而不用使用block名作为前缀。接着我们在缓冲中储存这些矩阵的值,每个声明了这个uniform块的着色器都能够获取矩阵。
|
||||
|
||||
现在你可能会奇怪layout(std140)是什么意思。它的意思是说当前定义的uniform块为它的内容使用特定的内存布局,这个声明实际上是设置uniform块布局(uniform block layout)。
|
||||
|
||||
|
||||
|
||||
### uniform块布局(uniform block layout)
|
||||
|
||||
一个uniform块的内容被储存到一个缓冲对象中,实际上就是在一块内存中。因为这块内存也不清楚它保存着什么类型的数据,我们就必须告诉OpenGL哪一块内存对应着色器中哪一个uniform变量。
|
||||
|
||||
假想下面的uniform块在一个着色器中:
|
||||
|
||||
```c++
|
||||
layout (std140) uniform ExampleBlock
|
||||
{
|
||||
float value;
|
||||
vec3 vector;
|
||||
mat4 matrix;
|
||||
float values[3];
|
||||
bool boolean;
|
||||
int integer;
|
||||
};
|
||||
```
|
||||
|
||||
我们所希望知道的是每个变量的大小(以字节为单位)和偏移量(从block的起始处),所以我们可以以各自的顺序把它们放进一个缓冲里。每个元素的大小在OpenGL中都很清楚,直接与C++数据类型呼应,向量和矩阵是一个float序列(数组)。OpenGL没有澄清的是变量之间的间距。这让硬件能以它认为合适的位置方式变量。比如有些硬件可以在float旁边放置一个vec3。不是所有硬件都能这样做,在vec3旁边附加一个float之前,给vec3加一个边距使之成为4个(空间连续的)float数组。功能很好,但对于我们来说用起来不方便。
|
||||
|
||||
GLSL 默认使用的uniform内存布局叫做共享布局(shared layout),叫共享是因为一旦偏移量被硬件定义,它们就会持续地被多个程序所共享。使用共享布局,GLSL可以为了优化而重新放置uniform变量,只要变量的顺序保持完整。因为我们不知道每个uniform变量的偏移量是多少,所以我们也就不知道如何精确地填充uniform缓冲。我们可以使用像`glGetUniformIndices`这样的函数来查询这个信息,但是这超出了本节教程的范围。
|
||||
|
||||
由于共享布局给我们做了一些空间优化。通常在实践中并不适用分享布局,而是使用std140布局。std140通过一系列的规则的规范声明了它们各自的偏移量,std140布局为每个变量类型显式地声明了内存的布局。由于被显式的提及,我们就可以手工算出每个变量的偏移量。
|
||||
|
||||
每个变量都有一个基线对齐(base alignment),它等于在一个uniform块中这个变量所占的空间(包含边距),这个基线对齐是使用std140布局原则计算出来的。然后,我们为每个变量计算出它的对齐偏移(aligned offset),这是一个变量从块(block)开始处的字节偏移量。变量对齐的字节偏移一定等于它的基线对齐的倍数。
|
||||
|
||||
准确的布局规则可以[在OpenGL的uniform缓冲规范](http://www.opengl.org/registry/specs/ARB/uniform_buffer_object.txt)中得到,但我们会列出最常见的规范。GLSL中每个变量类型比如int、float和bool被定义为4字节,每4字节被表示为N。
|
||||
|
||||
类型 | 布局规范
|
||||
---|---
|
||||
像int和bool这样的标量 | 每个标量的基线为N
|
||||
向量 | 每个向量的基线是2N或4N大小。这意味着vec3的基线为4N
|
||||
标量与向量数组 | 每个元素的基线与vec4的相同
|
||||
矩阵 | 被看做是存储着大量向量的数组,每个元素的基数与vec4相同
|
||||
结构体 | 根据以上规则计算其各个元素,并且间距必须是vec4基线的倍数
|
||||
|
||||
像OpenGL大多数规范一样,举个例子就很容易理解。再次利用之前介绍的uniform块`ExampleBlock`,我们用std140布局,计算它的每个成员的aligned offset(对齐偏移):
|
||||
|
||||
```c++
|
||||
layout (std140) uniform ExampleBlock
|
||||
{
|
||||
// base alignment ---------- // aligned offset
|
||||
float value; // 4 // 0
|
||||
vec3 vector; // 16 // 16 (必须是16的倍数,因此 4->16)
|
||||
mat4 matrix; // 16 // 32 (第 0 行)
|
||||
// 16 // 48 (第 1 行)
|
||||
// 16 // 64 (第 2 行)
|
||||
// 16 // 80 (第 3 行)
|
||||
float values[3]; // 16 (数组中的标量与vec4相同)//96 (values[0])
|
||||
// 16 // 112 (values[1])
|
||||
// 16 // 128 (values[2])
|
||||
bool boolean; // 4 // 144
|
||||
int integer; // 4 // 148
|
||||
};
|
||||
```
|
||||
|
||||
尝试自己计算出偏移量,把它们和表格对比,你可以把这件事当作一个练习。使用计算出来的偏移量,根据std140布局规则,我们可以用`glBufferSubData`这样的函数,使用变量数据填充缓冲。虽然不是很高效,但std140布局可以保证在每个程序中声明的这个uniform块的布局保持一致。
|
||||
|
||||
在定义uniform块前面添加layout (std140)声明,我们就能告诉OpenGL这个uniform块使用了std140布局。另外还有两种其他的布局可以选择,它们需要我们在填充缓冲之前查询每个偏移量。我们已经了解了分享布局(shared layout)和其他的布局都将被封装(packed)。当使用封装(packed)布局的时候,不能保证布局在别的程序中能够保持一致,因为它允许编译器从uniform块中优化出去uniform变量,这在每个着色器中都可能不同。
|
||||
|
||||
### 使用uniform缓冲
|
||||
|
||||
我们讨论了uniform块在着色器中的定义和如何定义它们的内存布局,但是我们还没有讨论如何使用它们。
|
||||
|
||||
首先我们需要创建一个uniform缓冲对象,这要使用`glGenBuffers`来完成。当我们拥有了一个缓冲对象,我们就把它绑定到`GL_UNIFORM_BUFFER`目标上,调用`glBufferData`来给它分配足够的空间。
|
||||
|
||||
```c++
|
||||
GLuint uboExampleBlock;
|
||||
glGenBuffers(1, &uboExampleBlock);
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
|
||||
glBufferData(GL_UNIFORM_BUFFER, 150, NULL, GL_STATIC_DRAW); // 分配150个字节的内存空间
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, 0);
|
||||
```
|
||||
|
||||
现在任何时候当我们打算往缓冲中更新或插入数据,我们就绑定到`uboExampleBlock`上,并使用`glBufferSubData`来更新它的内存。我们只需要更新这个uniform缓冲一次,所有的使用这个缓冲着色器就都会使用它更新的数据了。但是,OpenGL是如何知道哪个uniform缓冲对应哪个uniform块呢?
|
||||
|
||||
在OpenGL环境(context)中,定义了若干绑定点(binding points),在哪儿我们可以把一个uniform缓冲链接上去。当我们创建了一个uniform缓冲,我们把它链接到一个这个绑定点上,我们也把着色器中uniform块链接到同一个绑定点上,这样就把它们链接到一起了。下面的图标表示了这点:
|
||||
|
||||
|
||||
|
||||
你可以看到,我们可以将多个uniform缓冲绑定到不同绑定点上。因为着色器A和着色器B都有一个链接到同一个绑定点0的uniform块,它们的uniform块分享同样的uniform数据—`uboMatrices`有一个前提条件是两个着色器必须都定义了Matrices这个uniform块。
|
||||
|
||||
我们调用`glUniformBlockBinding`函数来把uniform块设置到一个特定的绑定点上。函数的第一个参数是一个程序对象,接着是一个uniform块索引(uniform block index)和打算链接的绑定点。uniform块索引是一个着色器中定义的uniform块的索引位置,可以调用`glGetUniformBlockIndex`来获取这个值,这个函数接收一个程序对象和uniform块的名字。我们可以从图表设置Lights这个uniform块链接到绑定点2:
|
||||
|
||||
```c++
|
||||
GLuint lights_index = glGetUniformBlockIndex(shaderA.Program, "Lights");
|
||||
glUniformBlockBinding(shaderA.Program, lights_index, 2);
|
||||
```
|
||||
|
||||
注意,我们必须在每个着色器中重复做这件事。
|
||||
|
||||
从OpenGL4.2起,也可以在着色器中通过添加另一个布局标识符来储存一个uniform块的绑定点,就不用我们调用`glGetUniformBlockIndex`和`glUniformBlockBinding`了。下面的代表显式设置了Lights这个uniform块的绑定点:
|
||||
|
||||
|
||||
```c++
|
||||
layout(std140, binding = 2) uniform Lights { ... };
|
||||
```
|
||||
|
||||
然后我们还需要把uniform缓冲对象绑定到同样的绑定点上,这个可以使用`glBindBufferBase`或`glBindBufferRange`来完成。
|
||||
|
||||
```c++
|
||||
glBindBufferBase(GL_UNIFORM_BUFFER, 2, uboExampleBlock);
|
||||
// 或者
|
||||
glBindBufferRange(GL_UNIFORM_BUFFER, 2, uboExampleBlock, 0, 150);
|
||||
```
|
||||
|
||||
函数`glBindBufferBase`接收一个目标、一个绑定点索引和一个uniform缓冲对象作为它的参数。这个函数把`uboExampleBlock`链接到绑定点2上面,自此绑定点所链接的两端都链接在一起了。你还可以使用`glBindBufferRange`函数,这个函数还需要一个偏移量和大小作为参数,这样你就可以只把一定范围的uniform缓冲绑定到一个绑定点上了。使用`glBindBufferRage`函数,你能够将多个不同的uniform块链接到同一个uniform缓冲对象上。
|
||||
|
||||
现在所有事情都做好了,我们可以开始向uniform缓冲添加数据了。我们可以使用`glBufferSubData`将所有数据添加为一个单独的字节数组或者更新缓冲的部分内容,只要我们愿意。为了更新uniform变量boolean,我们可以这样更新uniform缓冲对象:
|
||||
|
||||
```c++
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
|
||||
GLint b = true; // GLSL中的布尔值是4个字节,因此我们将它创建为一个4字节的整数
|
||||
glBufferSubData(GL_UNIFORM_BUFFER, 142, 4, &b);
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, 0);
|
||||
```
|
||||
|
||||
同样的处理也能够应用到uniform块中其他uniform变量上。
|
||||
|
||||
### 一个简单的例子
|
||||
|
||||
我们来师范一个真实的使用uniform缓冲对象的例子。如果我们回头看看前面所有演示的代码,我们一直使用了3个矩阵:投影、视图和模型矩阵。所有这些矩阵中,只有模型矩阵是频繁变化的。如果我们有多个着色器使用了这些矩阵,我们可能最好还是使用uniform缓冲对象。
|
||||
|
||||
我们将把投影和视图矩阵储存到一个uniform块中,它被取名为Matrices。我们不打算储存模型矩阵,因为模型矩阵会频繁在着色器间更改,所以使用uniform缓冲对象真的不会带来什么好处。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
|
||||
layout (std140) uniform Matrices
|
||||
{
|
||||
mat4 projection;
|
||||
mat4 view;
|
||||
};
|
||||
uniform mat4 model;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0);
|
||||
}
|
||||
```
|
||||
|
||||
这儿没什么特别的,除了我们现在使用了一个带有std140布局的uniform块。我们在例程中将显示4个立方体,每个立方体都使用一个不同的着色器程序。4个着色器程序使用同样的顶点着色器,但是它们将使用各自的片段着色器,每个片段着色器输出一个单色。
|
||||
|
||||
首先,我们把顶点着色器的uniform块设置为绑定点0。注意,我们必须为每个着色器做这件事。
|
||||
|
||||
```c++
|
||||
GLuint uniformBlockIndexRed = glGetUniformBlockIndex(shaderRed.Program, "Matrices");
|
||||
GLuint uniformBlockIndexGreen = glGetUniformBlockIndex(shaderGreen.Program, "Matrices");
|
||||
GLuint uniformBlockIndexBlue = glGetUniformBlockIndex(shaderBlue.Program, "Matrices");
|
||||
GLuint uniformBlockIndexYellow = glGetUniformBlockIndex(shaderYellow.Program, "Matrices");
|
||||
|
||||
glUniformBlockBinding(shaderRed.Program, uniformBlockIndexRed, 0);
|
||||
glUniformBlockBinding(shaderGreen.Program, uniformBlockIndexGreen, 0);
|
||||
glUniformBlockBinding(shaderBlue.Program, uniformBlockIndexBlue, 0);
|
||||
glUniformBlockBinding(shaderYellow.Program, uniformBlockIndexYellow, 0);
|
||||
```
|
||||
|
||||
然后,我们创建真正的uniform缓冲对象,并把缓冲绑定到绑定点0:
|
||||
|
||||
```c++
|
||||
GLuint uboMatrices
|
||||
glGenBuffers(1, &uboMatrices);
|
||||
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, uboMatrices);
|
||||
glBufferData(GL_UNIFORM_BUFFER, 2 * sizeof(glm::mat4), NULL, GL_STATIC_DRAW);
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, 0);
|
||||
|
||||
glBindBufferRange(GL_UNIFORM_BUFFER, 0, uboMatrices, 0, 2 * sizeof(glm::mat4));
|
||||
```
|
||||
|
||||
我们先为缓冲分配足够的内存,它等于glm::mat4的2倍。GLM的矩阵类型的大小直接对应于GLSL的mat4。然后我们把一个特定范围的缓冲链接到绑定点0,这个例子中应该是整个缓冲。
|
||||
|
||||
现在所有要做的事只剩下填充缓冲了。如果我们把视野( field of view)值保持为恒定的投影矩阵(这样就不会有摄像机缩放),我们只要在程序中定义它一次就行了,这也意味着我们只需向缓冲中把它插入一次。因为我们已经在缓冲对象中分配了足够的内存,我们可以在我们进入游戏循环之前使用`glBufferSubData`来储存投影矩阵:
|
||||
|
||||
```c++
|
||||
glm::mat4 projection = glm::perspective(45.0f, (float)width/(float)height, 0.1f, 100.0f);
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, uboMatrices);
|
||||
glBufferSubData(GL_UNIFORM_BUFFER, 0, sizeof(glm::mat4), glm::value_ptr(projection));
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, 0);
|
||||
```
|
||||
|
||||
这里我们用投影矩阵储存了uniform缓冲的前半部分。在我们在每次渲染迭代绘制物体前,我们用视图矩阵更新缓冲的第二个部分:
|
||||
|
||||
```c++
|
||||
glm::mat4 view = camera.GetViewMatrix();
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, uboMatrices);
|
||||
glBufferSubData(
|
||||
GL_UNIFORM_BUFFER, sizeof(glm::mat4), sizeof(glm::mat4), glm::value_ptr(view));
|
||||
glBindBuffer(GL_UNIFORM_BUFFER, 0);
|
||||
```
|
||||
|
||||
这就是uniform缓冲对象。每个包含着`Matrices`这个uniform块的顶点着色器都将对应`uboMatrices`所储存的数据。所以如果我们现在使用4个不同的着色器绘制4个立方体,它们的投影和视图矩阵都是一样的:
|
||||
|
||||
```c++
|
||||
glBindVertexArray(cubeVAO);
|
||||
shaderRed.Use();
|
||||
glm::mat4 model;
|
||||
model = glm::translate(model, glm::vec3(-0.75f, 0.75f, 0.0f)); // 移动到左上方
|
||||
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));
|
||||
glDrawArrays(GL_TRIANGLES, 0, 36);
|
||||
// ... 绘制绿色立方体
|
||||
// ... 绘制蓝色立方体
|
||||
// ... 绘制黄色立方体
|
||||
glBindVertexArray(0);
|
||||
```
|
||||
|
||||
我们只需要在去设置一个`model`的uniform即可。在一个像这样的场景中使用uniform缓冲对象在每个着色器中可以减少uniform的调用。最后效果看起来像这样:
|
||||
|
||||

|
||||
|
||||
通过改变模型矩阵,每个立方体都移动到窗口的一边,由于片段着色器不同,物体的颜色也不同。这是一个相对简单的场景,我们可以使用uniform缓冲对象,但是任何大型渲染程序有成百上千的活动着色程序,彼时uniform缓冲对象就会闪闪发光了。
|
||||
|
||||
你可以[在这里获得例程的完整源码](http://www.learnopengl.com/code_viewer.php?code=advanced/advanced_glsl_uniform_buffer_objects)。
|
||||
|
||||
uniform缓冲对象比单独的uniform有很多好处。第一,一次设置多个uniform比一次设置一个速度快。第二,如果你打算改变一个横跨多个着色器的uniform,在uniform缓冲中只需更改一次。最后一个好处可能不是很明显,使用uniform缓冲对象你可以在着色器中使用更多的uniform。OpenGL有一个对可使用uniform数据的数量的限制,可以用`GL_MAX_VERTEX_UNIFORM_COMPONENTS`来获取。当使用uniform缓冲对象中,这个限制的阈限会更高。所以无论何时,你达到了uniform的最大使用数量(比如做骨骼动画的时候),你可以使用uniform缓冲对象。
|
||||
507
04 Advanced OpenGL/09 Geometry Shader.md
Normal file
507
04 Advanced OpenGL/09 Geometry Shader.md
Normal file
@@ -0,0 +1,507 @@
|
||||
# 几何着色器
|
||||
|
||||
原文 | [Geometry Shader](http://learnopengl.com/#!Advanced-OpenGL/Geometry-Shader)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
## 几何着色器(Geometry Shader)
|
||||
|
||||
在顶点和片段着色器之间有一个可选的着色器,叫做几何着色器(geometry shader)。几何着色器以一个或多个表示为一个单独基本图形(primitive)的顶点作为输入,比如可以是一个点或者三角形。几何着色器在将这些顶点发送到下一个着色阶段之前,可以将这些顶点转变为它认为合适的内容。几何着色器有意思的地方在于它可以把(一个或多个)顶点转变为完全不同的基本图形(primitive),从而生成比原来多得多的顶点。
|
||||
|
||||
我们直接用一个例子深入了解一下:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (points) in;
|
||||
layout (line_strip, max_vertices = 2) out;
|
||||
|
||||
void main() {
|
||||
gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0);
|
||||
EmitVertex();
|
||||
|
||||
gl_Position = gl_in[0].gl_Position + vec4(0.1, 0.0, 0.0, 0.0);
|
||||
EmitVertex();
|
||||
|
||||
EndPrimitive();
|
||||
}
|
||||
```
|
||||
|
||||
每个几何着色器开始位置我们需要声明输入的基本图形(primitive)类型,这个输入是我们从顶点着色器中接收到的。我们在in关键字前面声明一个layout标识符。这个输入layout修饰符可以从一个顶点着色器接收以下基本图形值:
|
||||
|
||||
|
||||
基本图形|描述
|
||||
---|---
|
||||
points |绘制GL_POINTS基本图形的时候(1)
|
||||
lines |当绘制GL_LINES或GL_LINE_STRIP(2)时
|
||||
lines_adjacency | GL_LINES_ADJACENCY或GL_LINE_STRIP_ADJACENCY(4)
|
||||
triangles |GL_TRIANGLES, GL_TRIANGLE_STRIP或GL_TRIANGLE_FAN(3)
|
||||
triangles_adjacency |GL_TRIANGLES_ADJACENCY或GL_TRIANGLE_STRIP_ADJACENCY(6)
|
||||
|
||||
这是我们能够给渲染函数的几乎所有的基本图形。如果我们选择以GL_TRIANGLES绘制顶点,我们要把输入修饰符设置为triangles。括号里的数字代表一个基本图形所能包含的最少的顶点数。
|
||||
|
||||
当我们需要指定一个几何着色器所输出的基本图形类型时,我们就在out关键字前面加一个layout修饰符。和输入layout标识符一样,输出的layout标识符也可以接受以下基本图形值:
|
||||
|
||||
* points
|
||||
* line_strip
|
||||
* triangle_strip
|
||||
|
||||
使用这3个输出修饰符我们可以从输入的基本图形创建任何我们想要的形状。为了生成一个三角形,我们定义一个triangle_strip作为输出,然后输出3个顶点。
|
||||
|
||||
几何着色器同时希望我们设置一个它能输出的顶点数量的最大值(如果你超出了这个数值,OpenGL就会忽略剩下的顶点),我们可以在out关键字的layout标识符上做这件事。在这个特殊的情况中,我们将使用最大值为2个顶点,来输出一个line_strip。
|
||||
|
||||
这种情况,你会奇怪什么是线条:一个线条是把多个点链接起来表示出一个连续的线,它最少有两个点来组成。每个后一个点在前一个新渲染的点后面渲染,你可以看看下面的图,其中包含5个顶点:
|
||||
|
||||
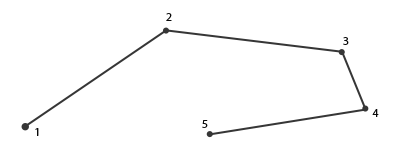
|
||||
|
||||
上面的着色器,我们只能输出一个线段,因为顶点的最大值设置为2。
|
||||
|
||||
为生成更有意义的结果,我们需要某种方式从前一个着色阶段获得输出。GLSL为我们提供了一个内建变量,它叫做**gl_in**,它的内部看起来可能像这样:
|
||||
|
||||
```c++
|
||||
in gl_Vertex
|
||||
{
|
||||
vec4 gl_Position;
|
||||
float gl_PointSize;
|
||||
float gl_ClipDistance[];
|
||||
} gl_in[];
|
||||
|
||||
```
|
||||
|
||||
这里它被声明为一个接口块(interface block,前面的教程已经讨论过),它包含几个有意思的变量,其中最有意思的是`gl_Position`,它包含着和我们设置的顶点着色器的输出相似的向量。
|
||||
|
||||
要注意的是,它被声明为一个数组,因为大多数渲染基本图形由一个以上顶点组成,几何着色器接收一个基本图形的所有顶点作为它的输入。
|
||||
|
||||
使用从前一个顶点着色阶段的顶点数据,我们就可以开始生成新的数据了,这是通过2个几何着色器函数`EmitVertex`和`EndPrimitive`来完成的。几何着色器需要你去生成/输出至少一个你定义为输出的基本图形。在我们的例子里我们打算至少生成一个线条(line strip)基本图形。
|
||||
|
||||
```c++
|
||||
void main() {
|
||||
gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0);
|
||||
EmitVertex();
|
||||
|
||||
gl_Position = gl_in[0].gl_Position + vec4(0.1, 0.0, 0.0, 0.0);
|
||||
EmitVertex();
|
||||
|
||||
EndPrimitive();
|
||||
}
|
||||
```
|
||||
|
||||
每次我们调用`EmitVertex`,当前设置到`gl_Position`的向量就会被添加到基本图形上。无论何时调用`EndPrimitive`,所有为这个基本图形发射出去的顶点都将结合为一个特定的输出渲染基本图形。一个或多个`EmitVertex`函数调用后,重复调用`EndPrimitive`就能生成多个基本图形。这个特殊的例子里,发射了两个顶点,它们被从顶点原来的位置平移了一段距离,然后调用`EndPrimitive`将这两个顶点结合为一个单独的有两个顶点的线条。
|
||||
|
||||
现在你了解了几何着色器的工作方式,你就可能猜出这个几何着色器做了什么。这个几何着色器接收一个基本图形——点,作为它的输入,使用输入点作为它的中心,创建了一个水平线基本图形。如果我们渲染它,结果就会像这样:
|
||||
|
||||
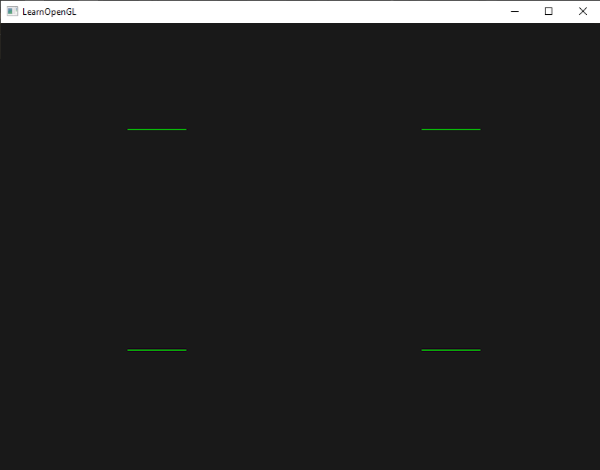
|
||||
|
||||
并不是非常引人注目,但是考虑到它的输出是使用下面的渲染命令生成的就很有意思了:
|
||||
|
||||
```c++
|
||||
glDrawArrays(GL_POINTS, 0, 4);
|
||||
```
|
||||
|
||||
这是个相对简单的例子,它向你展示了我们如何使用几何着色器来动态地在运行时生成新的形状。本章的后面,我们会讨论一些可以使用几何着色器获得有趣的效果,但是现在我们将以创建一个简单的几何着色器开始。
|
||||
|
||||
## 使用几何着色器
|
||||
|
||||
为了展示几何着色器的使用,我们将渲染一个简单的场景,在场景中我们只绘制4个点,这4个点在标准化设备坐标的z平面上。这些点的坐标是:
|
||||
|
||||
```c++
|
||||
GLfloat points[] = {
|
||||
-0.5f, 0.5f, // 左上方
|
||||
0.5f, 0.5f, // 右上方
|
||||
0.5f, -0.5f, // 右下方
|
||||
-0.5f, -0.5f // 左下方
|
||||
};
|
||||
```
|
||||
|
||||
顶点着色器只在z平面绘制点,所以我们只需要一个基本顶点着色器:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec2 position;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = vec4(position.x, position.y, 0.0f, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
我们会简单地为所有点输出绿色,我们直接在片段着色器里进行硬编码:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 color;
|
||||
|
||||
void main()
|
||||
{
|
||||
color = vec4(0.0f, 1.0f, 0.0f, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
为点的顶点生成一个VAO和VBO,然后使用`glDrawArrays`进行绘制:
|
||||
|
||||
```c++
|
||||
shader.Use();
|
||||
glBindVertexArray(VAO);
|
||||
glDrawArrays(GL_POINTS, 0, 4);
|
||||
glBindVertexArray(0);
|
||||
```
|
||||
|
||||
效果是黑色场景中有四个绿点(虽然很难看到):
|
||||
|
||||
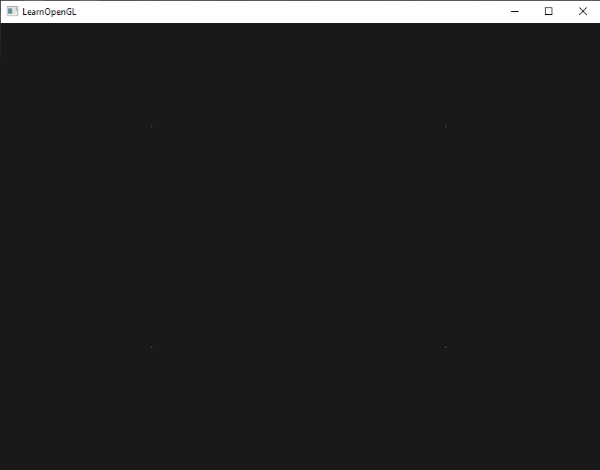
|
||||
|
||||
但我们不是已经学到了所有内容了吗?对,现在我们将通过为场景添加一个几何着色器来为这个小场景增加点活力。
|
||||
|
||||
出于学习的目的我们将创建一个叫pass-through的几何着色器,它用一个point基本图形作为它的输入,并把它无修改地传(pass)到下一个着色器。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (points) in;
|
||||
layout (points, max_vertices = 1) out;
|
||||
|
||||
void main() {
|
||||
gl_Position = gl_in[0].gl_Position;
|
||||
EmitVertex();
|
||||
EndPrimitive();
|
||||
}
|
||||
```
|
||||
|
||||
现在这个几何着色器应该很容易理解了。它简单地将它接收到的输入的无修改的顶点位置发射出去,然后生成一个point基本图形。
|
||||
|
||||
一个几何着色器需要像顶点和片段着色器一样被编译和链接,但是这次我们将使用`GL_GEOMETRY_SHADER`作为着色器的类型来创建这个着色器:
|
||||
|
||||
```c++
|
||||
geometryShader = glCreateShader(GL_GEOMETRY_SHADER);
|
||||
glShaderSource(geometryShader, 1, &gShaderCode, NULL);
|
||||
glCompileShader(geometryShader);
|
||||
...
|
||||
glAttachShader(program, geometryShader);
|
||||
glLinkProgram(program);
|
||||
```
|
||||
|
||||
编译着色器的代码和顶点、片段着色器的基本一样。要记得检查编译和链接错误!
|
||||
|
||||
如果你现在编译和运行,就会看到和下面相似的结果:
|
||||
|
||||

|
||||
|
||||
它和没用几何着色器一样!我承认有点无聊,但是事实上,我们仍能绘制证明几何着色器工作了的点,所以现在是时候来做点更有意思的事了!
|
||||
|
||||
|
||||
### 创建几个房子
|
||||
|
||||
绘制点和线没什么意思,所以我们将在每个点上使用几何着色器绘制一个房子。我们可以通过把几何着色器的输出设置为`triangle_strip`来达到这个目的,总共要绘制3个三角形:两个用来组成方形和另表示一个屋顶。
|
||||
|
||||
在OpenGL中三角形带(triangle strip)绘制起来更高效,因为它所使用的顶点更少。第一个三角形绘制完以后,每个后续的顶点会生成一个毗连前一个三角形的新三角形:每3个毗连的顶点都能构成一个三角形。如果我们有6个顶点,它们以三角形带的方式组合起来,那么我们会得到这些三角形:(1, 2, 3)、(2, 3, 4)、(3, 4, 5)、(4,5,6)因此总共可以表示出4个三角形。一个三角形带至少要用3个顶点才行,它能生曾N-2个三角形;6个顶点我们就能创建6-2=4个三角形。下面的图片表达了这点:
|
||||
|
||||
|
||||
|
||||
使用一个三角形带作为一个几何着色器的输出,我们可以轻松创建房子的形状,只要以正确的顺序来生成3个毗连的三角形。下面的图像显示,我们需要以何种顺序来绘制点,才能获得我们需要的三角形,图上的蓝点代表输入点:
|
||||
|
||||
|
||||
|
||||
上图的内容转变为几何着色器:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (points) in;
|
||||
layout (triangle_strip, max_vertices = 5) out;
|
||||
|
||||
void build_house(vec4 position)
|
||||
{
|
||||
gl_Position = position + vec4(-0.2f, -0.2f, 0.0f, 0.0f);// 1:左下角
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.2f, -0.2f, 0.0f, 0.0f);// 2:右下角
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4(-0.2f, 0.2f, 0.0f, 0.0f);// 3:左上
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.2f, 0.2f, 0.0f, 0.0f);// 4:右上
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.0f, 0.4f, 0.0f, 0.0f);// 5:屋顶
|
||||
EmitVertex();
|
||||
EndPrimitive();
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
build_house(gl_in[0].gl_Position);
|
||||
}
|
||||
```
|
||||
|
||||
这个几何着色器生成5个顶点,每个顶点是点(point)的位置加上一个偏移量,来组成一个大三角形带。接着最后的基本图形被像素化,片段着色器处理整三角形带,结果是为我们绘制的每个点生成一个绿房子:
|
||||
|
||||
|
||||
|
||||
可以看到,每个房子实则是由3个三角形组成,都是仅仅使用空间中一点来绘制的。绿房子看起来还是不够漂亮,所以我们再给每个房子加一个不同的颜色。我们将在顶点着色器中为每个顶点增加一个额外的代表颜色信息的顶点属性。
|
||||
|
||||
下面是更新了的顶点数据:
|
||||
|
||||
```c++
|
||||
GLfloat points[] = {
|
||||
-0.5f, 0.5f, 1.0f, 0.0f, 0.0f, // 左上
|
||||
0.5f, 0.5f, 0.0f, 1.0f, 0.0f, // 右上
|
||||
0.5f, -0.5f, 0.0f, 0.0f, 1.0f, // 右下
|
||||
-0.5f, -0.5f, 1.0f, 1.0f, 0.0f // 左下
|
||||
};
|
||||
```
|
||||
|
||||
然后我们更新顶点着色器,使用一个接口块来项几何着色器发送颜色属性:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec2 position;
|
||||
layout (location = 1) in vec3 color;
|
||||
|
||||
out VS_OUT {
|
||||
vec3 color;
|
||||
} vs_out;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = vec4(position.x, position.y, 0.0f, 1.0f);
|
||||
vs_out.color = color;
|
||||
}
|
||||
```
|
||||
|
||||
接着我们还需要在几何着色器中声明同样的接口块(使用一个不同的接口名):
|
||||
|
||||
```c++
|
||||
in VS_OUT {
|
||||
vec3 color;
|
||||
} gs_in[];
|
||||
```
|
||||
|
||||
因为几何着色器把多个顶点作为它的输入,从顶点着色器来的输入数据总是被以数组的形式表示出来,即使现在我们只有一个顶点。
|
||||
|
||||
!!! Important
|
||||
|
||||
我们不是必须使用接口块来把数据发送到几何着色器中。我们还可以这么写:
|
||||
|
||||
in vec3 vColor[];
|
||||
|
||||
如果顶点着色器发送的颜色向量是out vec3 vColor那么接口块就会在比如几何着色器这样的着色器中更轻松地完成工作。事实上,几何着色器的输入可以非常大,把它们组成一个大的接口块数组会更有意义。
|
||||
|
||||
|
||||
然后我们还要为下一个像素着色阶段声明一个输出颜色向量:
|
||||
|
||||
```c++
|
||||
out vec3 fColor;
|
||||
```
|
||||
|
||||
因为片段着色器只需要一个(已进行了插值的)颜色,传送多个颜色没有意义。fColor向量这样就不是一个数组,而是一个单一的向量。当发射一个顶点时,为了它的片段着色器运行,每个顶点都会储存最后在fColor中储存的值。对于这些房子来说,我们可以在第一个顶点被发射,对整个房子上色前,只使用来自顶点着色器的颜色填充fColor一次:
|
||||
|
||||
```c++
|
||||
fColor = gs_in[0].color; //只有一个输出颜色,所以直接设置为gs_in[0]
|
||||
gl_Position = position + vec4(-0.2f, -0.2f, 0.0f, 0.0f); // 1:左下
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.2f, -0.2f, 0.0f, 0.0f); // 2:右下
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4(-0.2f, 0.2f, 0.0f, 0.0f); // 3:左上
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.2f, 0.2f, 0.0f, 0.0f); // 4:右上
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.0f, 0.4f, 0.0f, 0.0f); // 5:屋顶
|
||||
EmitVertex();
|
||||
EndPrimitive();
|
||||
```
|
||||
|
||||
所有发射出去的顶点都把最后储存在fColor中的值嵌入到他们的数据中,和我们在他们的属性中定义的顶点颜色相同。所有的分房子便都有了自己的颜色:
|
||||
|
||||
|
||||
|
||||
为了好玩儿,我们还可以假装这是在冬天,给最后一个顶点一个自己的白色,就像在屋顶上落了一些雪。
|
||||
|
||||
```c++
|
||||
fColor = gs_in[0].color;
|
||||
gl_Position = position + vec4(-0.2f, -0.2f, 0.0f, 0.0f);
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.2f, -0.2f, 0.0f, 0.0f);
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4(-0.2f, 0.2f, 0.0f, 0.0f);
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.2f, 0.2f, 0.0f, 0.0f);
|
||||
EmitVertex();
|
||||
gl_Position = position + vec4( 0.0f, 0.4f, 0.0f, 0.0f);
|
||||
fColor = vec3(1.0f, 1.0f, 1.0f);
|
||||
EmitVertex();
|
||||
EndPrimitive();
|
||||
|
||||
```
|
||||
|
||||
结果就像这样:
|
||||
|
||||
|
||||
|
||||
你可以对比一下你的[源码](http://learnopengl.com/code_viewer.php?code=advanced/geometry_shader_houses)和[着色器](http://learnopengl.com/code_viewer.php?code=advanced/geometry_shader_houses_shaders)。
|
||||
|
||||
你可以看到,使用几何着色器,你可以使用最简单的基本图形就能获得漂亮的新玩意。因为这些形状是在你的GPU超快硬件上动态生成的,这要比使用顶点缓冲自己定义这些形状更为高效。几何缓冲在简单的经常被重复的形状比如体素(voxel)的世界和室外的草地上,是一种非常强大的优化工具。
|
||||
|
||||
### 爆炸式物体
|
||||
|
||||
绘制房子的确很有趣,但我们不会经常这么用。这就是为什么现在我们将撬起物体缺口,形成爆炸式物体的原因!虽然这个我们也不会经常用到,但是它能向你展示一些几何着色器的强大之处。
|
||||
|
||||
当我们说对一个物体进行爆破的时候并不是说我们将要把之前的那堆顶点炸掉,但是我们打算把每个三角形沿着它们的法线向量移动一小段距离。效果是整个物体上的三角形看起来就像沿着它们的法线向量爆炸了一样。纳米服上的三角形的爆炸式效果看起来是这样的:
|
||||
|
||||
|
||||
|
||||
这样一个几何着色器效果的一大好处是,它可以用到任何物体上,无论它们多复杂。
|
||||
|
||||
因为我们打算沿着三角形的法线向量移动三角形的每个顶点,我们需要先计算它的法线向量。我们要做的是计算出一个向量,它垂直于三角形的表面,使用这三个我们已经的到的顶点就能做到。你可能记得变换教程中,我们可以使用叉乘获取一个垂直于两个其他向量的向量。如果我们有两个向量a和b,它们平行于三角形的表面,我们就可以对这两个向量进行叉乘得到法线向量了。下面的几何着色器函数做的正是这件事,它使用3个输入顶点坐标获取法线向量:
|
||||
|
||||
```c++
|
||||
vec3 GetNormal()
|
||||
{
|
||||
vec3 a = vec3(gl_in[0].gl_Position) - vec3(gl_in[1].gl_Position);
|
||||
vec3 b = vec3(gl_in[2].gl_Position) - vec3(gl_in[1].gl_Position);
|
||||
return normalize(cross(a, b));
|
||||
}
|
||||
```
|
||||
|
||||
这里我们使用减法获取了两个向量a和b,它们平行于三角形的表面。两个向量相减得到一个两个向量的差值,由于所有3个点都在三角形平面上,任何向量相减都会得到一个平行于平面的向量。一定要注意,如果我们调换了a和b的叉乘顺序,我们得到的法线向量就会使反的,顺序很重要!
|
||||
|
||||
知道了如何计算法线向量,我们就能创建一个explode函数,函数返回的是一个新向量,它把位置向量沿着法线向量方向平移:
|
||||
|
||||
```c++
|
||||
vec4 explode(vec4 position, vec3 normal)
|
||||
{
|
||||
float magnitude = 2.0f;
|
||||
vec3 direction = normal * ((sin(time) + 1.0f) / 2.0f) * magnitude;
|
||||
return position + vec4(direction, 0.0f);
|
||||
}
|
||||
```
|
||||
|
||||
函数本身并不复杂,sin(正弦)函数把一个time变量作为它的参数,它根据时间来返回一个-1.0到1.0之间的值。因为我们不想让物体坍缩,所以我们把sin返回的值做成0到1的范围。最后的值去乘以法线向量,direction向量被添加到位置向量上。
|
||||
|
||||
爆炸效果的完整的几何着色器是这样的,它使用我们的模型加载器,绘制出一个模型:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (triangles) in;
|
||||
layout (triangle_strip, max_vertices = 3) out;
|
||||
|
||||
in VS_OUT {
|
||||
vec2 texCoords;
|
||||
} gs_in[];
|
||||
|
||||
out vec2 TexCoords;
|
||||
|
||||
uniform float time;
|
||||
|
||||
vec4 explode(vec4 position, vec3 normal) { ... }
|
||||
|
||||
vec3 GetNormal() { ... }
|
||||
|
||||
void main() {
|
||||
vec3 normal = GetNormal();
|
||||
|
||||
gl_Position = explode(gl_in[0].gl_Position, normal);
|
||||
TexCoords = gs_in[0].texCoords;
|
||||
EmitVertex();
|
||||
gl_Position = explode(gl_in[1].gl_Position, normal);
|
||||
TexCoords = gs_in[1].texCoords;
|
||||
EmitVertex();
|
||||
gl_Position = explode(gl_in[2].gl_Position, normal);
|
||||
TexCoords = gs_in[2].texCoords;
|
||||
EmitVertex();
|
||||
EndPrimitive();
|
||||
}
|
||||
```
|
||||
|
||||
注意我们同样在发射一个顶点前输出了合适的纹理坐标。
|
||||
|
||||
也不要忘记在OpenGL代码中设置time变量:
|
||||
|
||||
```c++
|
||||
glUniform1f(glGetUniformLocation(shader.Program, "time"), glfwGetTime());
|
||||
```
|
||||
|
||||
最后的结果是一个随着时间持续不断地爆炸的3D模型(不断爆炸不断回到正常状态)。尽管没什么大用处,它却向你展示出很多几何着色器的高级用法。你可以用[完整的源码](http://learnopengl.com/code_viewer.php?code=advanced/geometry_shader_explode)和[着色器](http://learnopengl.com/code_viewer.php?code=advanced/geometry_shader_explode_shaders)对比一下你自己的。
|
||||
|
||||
### 把法线向量显示出来
|
||||
|
||||
在这部分我们将使用几何着色器写一个例子,非常有用:显示一个法线向量。当编写光照着色器的时候,你最终会遇到奇怪的视频输出问题,你很难决定是什么导致了这个问题。通常导致光照错误的是,不正确的加载顶点数据,以及给它们指定了不合理的顶点属性,又或是在着色器中不合理的管理,导致产生了不正确的法线向量。我们所希望的是有某种方式可以检测出法线向量是否正确。把法线向量显示出来正是这样一种方法,恰好几何着色器能够完美地达成这个目的。
|
||||
|
||||
思路是这样的:我们先不用几何着色器,正常绘制场景,然后我们再次绘制一遍场景,但这次只显示我们通过几何着色器生成的法线向量。几何着色器把一个三角形基本图形作为输入类型,用它们生成3条和法线向量同向的线段,每个顶点一条。伪代码应该是这样的:
|
||||
|
||||
```c++
|
||||
shader.Use();
|
||||
DrawScene();
|
||||
normalDisplayShader.Use();
|
||||
DrawScene();
|
||||
```
|
||||
|
||||
这次我们会创建一个使用模型提供的顶点法线,而不是自己去生成。为了适应缩放和旋转我们会在把它变换到裁切空间坐标前,使用法线矩阵来法线(几何着色器用他的位置向量做为裁切空间坐标,所以我们还要把法线向量变换到同一个空间)。这些都能在顶点着色器中完成:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
layout (location = 1) in vec3 normal;
|
||||
|
||||
out VS_OUT {
|
||||
vec3 normal;
|
||||
} vs_out;
|
||||
|
||||
uniform mat4 projection;
|
||||
uniform mat4 view;
|
||||
uniform mat4 model;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * model * vec4(position, 1.0f);
|
||||
mat3 normalMatrix = mat3(transpose(inverse(view * model)));
|
||||
vs_out.normal = normalize(vec3(projection * vec4(normalMatrix * normal, 1.0)));
|
||||
}
|
||||
```
|
||||
|
||||
经过变换的裁切空间法线向量接着通过一个接口块被传递到下个着色阶段。几何着色器接收每个顶点(带有位置和法线向量),从每个位置向量绘制出一个法线向量:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (triangles) in;
|
||||
layout (line_strip, max_vertices = 6) out;
|
||||
|
||||
in VS_OUT {
|
||||
vec3 normal;
|
||||
} gs_in[];
|
||||
|
||||
const float MAGNITUDE = 0.4f;
|
||||
|
||||
void GenerateLine(int index)
|
||||
{
|
||||
gl_Position = gl_in[index].gl_Position;
|
||||
EmitVertex();
|
||||
gl_Position = gl_in[index].gl_Position + vec4(gs_in[index].normal, 0.0f) * MAGNITUDE;
|
||||
EmitVertex();
|
||||
EndPrimitive();
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
GenerateLine(0); // First vertex normal
|
||||
GenerateLine(1); // Second vertex normal
|
||||
GenerateLine(2); // Third vertex normal
|
||||
}
|
||||
```
|
||||
|
||||
到现在为止,像这样的几何着色器的内容就不言自明了。需要注意的是我们我们把法线向量乘以一个MAGNITUDE向量来限制显示出的法线向量的大小(否则它们就太大了)。
|
||||
|
||||
由于把法线显示出来通常用于调试的目的,我们可以在片段着色器的帮助下把它们显示为单色的线(如果你愿意也可以更炫一点)。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
out vec4 color;
|
||||
|
||||
void main()
|
||||
{
|
||||
color = vec4(1.0f, 1.0f, 0.0f, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
现在先使用普通着色器来渲染你的模型,然后使用特制的法线可视着色器,你会看到这样的效果:
|
||||
|
||||
|
||||
|
||||
除了我们的纳米服现在看起来有点像一个带着隔热手套的全身多毛的家伙外,它给了我们一种非常有效的检查一个模型的法线向量是否有错误的方式。你可以想象下这样的几何着色器也经常能被用在给物体添加毛发上。
|
||||
|
||||
你可以从这里找到[源码](http://learnopengl.com/code_viewer.php?code=advanced/geometry_shader_normals)和可显示法线的[着色器](http://learnopengl.com/code_viewer.php?code=advanced/geometry_shader_normals_shaders)。
|
||||
352
04 Advanced OpenGL/10 Instancing.md
Normal file
352
04 Advanced OpenGL/10 Instancing.md
Normal file
@@ -0,0 +1,352 @@
|
||||
# 实例化(Instancing)
|
||||
|
||||
原文 | [Instancing](http://learnopengl.com/#!Advanced-OpenGL/Instancing)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
假如你有一个有许多模型的场景,而这些模型的顶点数据都一样,只是进行了不同的世界空间的变换。想象一下,有一个场景中充满了草叶:每根草都是几个三角形组成的。你可能需要绘制很多的草叶,最终一次渲染循环中就肯能有成千上万个草需要绘制了。因为每个草叶只是由几个三角形组成,绘制一个几乎是即刻完成,但是数量巨大以后,执行起来就很慢了。
|
||||
|
||||
如果我们渲染这样多的物体的时候,也许代码会写成这样:
|
||||
|
||||
```c++
|
||||
for(GLuint i = 0; i < amount_of_models_to_draw; i++)
|
||||
{
|
||||
DoSomePreparations(); //在这里绑定VAO、绑定纹理、设置uniform变量等
|
||||
glDrawArrays(GL_TRIANGLES, 0, amount_of_vertices);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
像这样绘制出你模型的其他实例,多次绘制之后,很快将达到一个瓶颈,这是因为你`glDrawArrays`或`glDrawElements`这样的函数(Draw call)过多。这样渲染顶点数据,会明显降低执行效率,这是因为OpenGL在它可以绘制你的顶点数据之前必须做一些准备工作(比如告诉GPU从哪个缓冲读取数据,以及在哪里找到顶点属性,所有这些都会使CPU到GPU的总线变慢)。所以即使渲染顶点超快,而多次给你的GPU下达这样的渲染命令却未必。
|
||||
|
||||
如果我们能够将数据一次发送给GPU,就会更方便,然后告诉OpenGL使用一个绘制函数,将这些数据绘制为多个物体。这就是我们将要展开讨论的**实例化(instancing)**。
|
||||
|
||||
**实例化(instancing)**是一种只调用一次渲染函数却能绘制出很多物体的技术,它节省渲染物体时从CPU到GPU的通信时间,而且只需做一次即可。要使用实例化渲染,我们必须将`glDrawArrays`和`glDrawElements`各自改为`glDrawArraysInstanced`和`glDrawElementsInstanced`。这些用于实例化的函数版本需要设置一个额外的参数,叫做**实例数量(instance count)**,它设置我们打算渲染实例的数量。这样我们就只需要把所有需要的数据发送给GPU一次就行了,然后告诉GPU它该如何使用一个函数来绘制所有这些实例。
|
||||
|
||||
就其本身而言,这个函数用处不大。渲染同一个物体一千次对我们来说没用,因为每个渲染出的物体不仅相同而且还在同一个位置;我们只能看到一个物体!出于这个原因GLSL在着色器中嵌入了另一个内建变量,叫做**`gl_InstanceID`**。
|
||||
|
||||
在通过实例化绘制时,`gl_InstanceID`的初值是0,它在每个实例渲染时都会增加1。如果我们渲染43个实例,那么在顶点着色器`gl_InstanceID`的值最后就是42。每个实例都拥有唯一的值意味着我们可以索引到一个位置数组,并将每个实例摆放在世界空间的不同的位置上。
|
||||
|
||||
我们调用一个实例化渲染函数,在标准化设备坐标中绘制一百个2D四边形来看看实例化绘制的效果是怎样的。通过对一个储存着100个偏移量向量的索引,我们为每个实例四边形添加一个偏移量。最后,窗口被排列精美的四边形网格填满:
|
||||
|
||||
|
||||
|
||||
每个四边形是2个三角形所组成的,因此总共有6个顶点。每个顶点包含一个2D标准设备坐标位置向量和一个颜色向量。下面是例子中所使用的顶点数据,每个三角形为了适应屏幕都很小:
|
||||
|
||||
```c++
|
||||
GLfloat quadVertices[] = {
|
||||
// ---位置--- ------颜色-------
|
||||
-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,
|
||||
0.05f, -0.05f, 0.0f, 1.0f, 0.0f,
|
||||
-0.05f, -0.05f, 0.0f, 0.0f, 1.0f,
|
||||
|
||||
-0.05f, 0.05f, 1.0f, 0.0f, 0.0f,
|
||||
0.05f, -0.05f, 0.0f, 1.0f, 0.0f,
|
||||
0.05f, 0.05f, 0.0f, 1.0f, 1.0f
|
||||
};
|
||||
```
|
||||
|
||||
片段着色器接收从顶点着色器发送来的颜色向量,设置为它的颜色输出,从而为四边形上色:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
in vec3 fColor;
|
||||
out vec4 color;
|
||||
|
||||
void main()
|
||||
{
|
||||
color = vec4(fColor, 1.0f);
|
||||
}
|
||||
```
|
||||
|
||||
到目前为止没有什么新内容,但顶点着色器开始变得有意思了:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec2 position;
|
||||
layout (location = 1) in vec3 color;
|
||||
|
||||
out vec3 fColor;
|
||||
|
||||
uniform vec2 offsets[100];
|
||||
|
||||
void main()
|
||||
{
|
||||
vec2 offset = offsets[gl_InstanceID];
|
||||
gl_Position = vec4(position + offset, 0.0f, 1.0f);
|
||||
fColor = color;
|
||||
}
|
||||
```
|
||||
|
||||
这里我们定义了一个uniform数组,叫`offsets`,它包含100个偏移量向量。在顶点着色器里,我们接收一个对应着当前实例的偏移量,这是通过使用 `gl_InstanceID`来索引offsets得到的。如果我们使用实例化绘制100个四边形,使用这个顶点着色器,我们就能得到100位于不同位置的四边形。
|
||||
|
||||
我们一定要设置偏移位置,在游戏循环之前我们用一个嵌套for循环计算出它来:
|
||||
|
||||
```c++
|
||||
glm::vec2 translations[100];
|
||||
int index = 0;
|
||||
GLfloat offset = 0.1f;
|
||||
for(GLint y = -10; y < 10; y += 2)
|
||||
{
|
||||
for(GLint x = -10; x < 10; x += 2)
|
||||
{
|
||||
glm::vec2 translation;
|
||||
translation.x = (GLfloat)x / 10.0f + offset;
|
||||
translation.y = (GLfloat)y / 10.0f + offset;
|
||||
translations[index++] = translation;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里我们创建100个平移向量,它包含着10×10格子所有位置。除了生成`translations`数组外,我们还需要把这些位移数据发送到顶点着色器的uniform数组:
|
||||
|
||||
```c++
|
||||
shader.Use();
|
||||
for(GLuint i = 0; i < 100; i++)
|
||||
{
|
||||
stringstream ss;
|
||||
string index;
|
||||
ss << i;
|
||||
index = ss.str();
|
||||
GLint location = glGetUniformLocation(shader.Program, ("offsets[" + index + "]").c_str())
|
||||
glUniform2f(location, translations[i].x, translations[i].y);
|
||||
}
|
||||
```
|
||||
|
||||
这一小段代码中,我们将for循环计数器i变为string,接着就能动态创建一个为请求的uniform的`location`创建一个`location`字符串。将offsets数组中的每个条目,我们都设置为相应的平移向量。
|
||||
|
||||
现在所有的准备工作都结束了,我们可以开始渲染四边形了。用实例化渲染来绘制四边形,我们需要调用`glDrawArraysInstanced`或`glDrawElementsInstanced`,由于我们使用的不是索引绘制缓冲,所以我们用的是`glDrawArrays`对应的那个版本`glDrawArraysInstanced`:
|
||||
|
||||
```c++
|
||||
glBindVertexArray(quadVAO);
|
||||
glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);
|
||||
glBindVertexArray(0);
|
||||
```
|
||||
|
||||
`glDrawArraysInstanced`的参数和`glDrawArrays`一样,除了最后一个参数设置了我们打算绘制实例的数量。我们想展示100个四边形,它们以10×10网格形式展现,所以这儿就是100.运行代码,你会得到100个相似的有色四边形。
|
||||
|
||||
## 实例化数组(instanced arrays)
|
||||
|
||||
在这种特定条件下,前面的实现很好,但是当我们有100个实例的时候(这很正常),最终我们将碰到uniform数据数量的上线。为避免这个问题另一个可替代方案是实例化数组,它使用顶点属性来定义,这样就允许我们使用更多的数据了,当顶点着色器渲染一个新实例时它才会被更新。
|
||||
|
||||
使用顶点属性,每次运行顶点着色器都将让GLSL获取到下个顶点属性集合,它们属于当前顶点。当把顶点属性定义为实例数组时,顶点着色器只更新每个实例的顶点属性的内容而不是顶点的内容。这使我们在每个顶点数据上使用标准顶点属性,用实例数组来储存唯一的实例数据。
|
||||
|
||||
为了展示一个实例化数组的例子,我们将采用前面的例子,把偏移uniform表示为一个实例数组。我们不得不增加另一个顶点属性,来更新顶点着色器。
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec2 position;
|
||||
layout (location = 1) in vec3 color;
|
||||
layout (location = 2) in vec2 offset;
|
||||
|
||||
out vec3 fColor;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = vec4(position + offset, 0.0f, 1.0f);
|
||||
fColor = color;
|
||||
}
|
||||
```
|
||||
|
||||
我们不再使用`gl_InstanceID`,可以直接用`offset`属性,不用先在一个大uniform数组里进行索引。
|
||||
|
||||
因为一个实例化数组实际上就是一个和位置和颜色一样的顶点属性,我们还需要把它的内容储存为一个顶点缓冲对象里,并把它配置为一个属性指针。我们首先将平移变换数组贮存到一个新的缓冲对象上:
|
||||
|
||||
```c++
|
||||
GLuint instanceVBO;
|
||||
glGenBuffers(1, &instanceVBO);
|
||||
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
|
||||
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);
|
||||
glBindBuffer(GL_ARRAY_BUFFER, 0);
|
||||
```
|
||||
|
||||
之后我们还需要设置它的顶点属性指针,并开启顶点属性:
|
||||
|
||||
```c++
|
||||
glEnableVertexAttribArray(2);
|
||||
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
|
||||
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(GLfloat), (GLvoid*)0);
|
||||
glBindBuffer(GL_ARRAY_BUFFER, 0);
|
||||
glVertexAttribDivisor(2, 1);
|
||||
```
|
||||
|
||||
代码中有意思的地方是,最后一行,我们调用了 **`glVertexAttribDivisor`**。这个函数告诉OpenGL什么时候去更新顶点属性的内容到下个元素。它的第一个参数是提到的顶点属性,第二个参数是属性除数(attribute divisor)。默认属性除数是0,告诉OpenGL在顶点着色器的每次迭代更新顶点属性的内容。把这个属性设置为1,我们就是告诉OpenGL我们打算在开始渲染一个新的实例的时候更新顶点属性的内容。设置为2代表我们每2个实例更新内容,依此类推。把属性除数设置为1,我们可以高效地告诉OpenGL,location是2的顶点属性是一个实例数组(instanced array)。
|
||||
|
||||
如果我们现在再次使用`glDrawArraysInstanced`渲染四边形,我们会得到下面的输出:
|
||||
|
||||

|
||||
|
||||
和前面的一样,但这次是使用实例数组实现的,它使我们为绘制实例向顶点着色器传递更多的数据(内存允许我们存多少就能存多少)。
|
||||
|
||||
你还可以使`用gl_InstanceID`从右上向左下缩小每个四边形。
|
||||
|
||||
```c++
|
||||
void main()
|
||||
{
|
||||
vec2 pos = position * (gl_InstanceID / 100.0f);
|
||||
gl_Position = vec4(pos + offset, 0.0f, 1.0f);
|
||||
fColor = color;
|
||||
}
|
||||
```
|
||||
|
||||
结果是第一个实例的四边形被绘制的非常小,随着绘制实例的增加,`gl_InstanceID`越来越接近100,这样更多的四边形会更接近它们原来的大小。这是一种很好的将`gl_InstanceID`与实例数组结合使用的法则:
|
||||
|
||||
|
||||
|
||||
如果你仍然不确定实例渲染如何工作,或者想看看上面的代码是如何组合起来的,你可以在[这里找到应用的源码](http://learnopengl.com/code_viewer.php?code=advanced/instancing_quads)。
|
||||
|
||||
这些例子不是实例的好例子,不过挺有意思的。它们可以让你对实例的工作方式有一个概括的理解,但是当绘制拥有极大数量的相同物体的时候,它极其有用,现在我们还没有展示呢。出于这个原因,我们将在接下来的部分进入太空来看看实例渲染的威力。
|
||||
|
||||
### 小行星带
|
||||
|
||||
想象一下,在一个场景中有一个很大的行星,行星周围有一圈小行星带。这样一个小行星大可能包含成千上万的石块,对于大多数显卡来说几乎是难以完成的渲染任务。这个场景对于实例渲染来说却不再话下,由于所有小行星可以使用一个模型来表示。每个小行星使用一个变换矩阵就是一个经过少量变化的独一无二的小行星了。
|
||||
|
||||
为了展示实例渲染的影响,我们先不使用实例渲染,来渲染一个小行星围绕行星飞行的场景。这个场景的大天体可以[从这里下载](http://learnopengl.com/data/models/planet.rar),此外要把小行星放在合适的位置上。小行星可以[从这里下载](http://learnopengl.com/data/models/rock.rar)。
|
||||
|
||||
为了得到我们理想中的效果,我们将为每个小行星生成一个变换矩阵,作为它们的模型矩阵。变换矩阵先将小行星平移到行星带上,我们还要添加一个随机位移值来作为偏移量,这样才能使行星带更自然。接着我们应用一个随机缩放,以及一个随机旋转向量。最后,变换矩阵就会将小行星变换到行星的周围,同时使它们更自然,每个行星都有别于其他的。
|
||||
|
||||
```c++
|
||||
GLuint amount = 1000;
|
||||
glm::mat4* modelMatrices;
|
||||
modelMatrices = new glm::mat4[amount];
|
||||
srand(glfwGetTime()); // initialize random seed
|
||||
GLfloat radius = 50.0;
|
||||
GLfloat offset = 2.5f;
|
||||
for(GLuint i = 0; i < amount; i++)
|
||||
{
|
||||
glm::mat4 model;
|
||||
// 1. Translation: displace along circle with 'radius' in range [-offset, offset]
|
||||
GLfloat angle = (GLfloat)i / (GLfloat)amount * 360.0f;
|
||||
GLfloat displacement = (rand() % (GLint)(2 * offset * 100)) / 100.0f - offset;
|
||||
GLfloat x = sin(angle) * radius + displacement;
|
||||
displacement = (rand() % (GLint)(2 * offset * 100)) / 100.0f - offset;
|
||||
GLfloat y = displacement * 0.4f; // y value has smaller displacement
|
||||
displacement = (rand() % (GLint)(2 * offset * 100)) / 100.0f - offset;
|
||||
GLfloat z = cos(angle) * radius + displacement;
|
||||
model = glm::translate(model, glm::vec3(x, y, z));
|
||||
// 2. Scale: Scale between 0.05 and 0.25f
|
||||
GLfloat scale = (rand() % 20) / 100.0f + 0.05;
|
||||
model = glm::scale(model, glm::vec3(scale));
|
||||
// 3. Rotation: add random rotation around a (semi)randomly picked rotation axis vector
|
||||
GLfloat rotAngle = (rand() % 360);
|
||||
model = glm::rotate(model, rotAngle, glm::vec3(0.4f, 0.6f, 0.8f));
|
||||
// 4. Now add to list of matrices
|
||||
modelMatrices[i] = model;
|
||||
}
|
||||
```
|
||||
|
||||
这段代码看起来还是有点吓人,但我们基本上是沿着一个半径为radius的圆圈变换小行星的x和y的值,让每个小行星在-offset和offset之间随机生成一个位置。我们让y变化的更小,这让这个环带就会成为扁平的。接着我们缩放和旋转变换,把结果储存到一个modelMatrices矩阵里,它的大小是amount。这里我们生成1000个模型矩阵,每个小行星一个。
|
||||
|
||||
加载完天体和小行星模型后,编译着色器,渲染代码是这样的:
|
||||
|
||||
```c++
|
||||
// 绘制行星
|
||||
shader.Use();
|
||||
glm::mat4 model;
|
||||
model = glm::translate(model, glm::vec3(0.0f, -5.0f, 0.0f));
|
||||
model = glm::scale(model, glm::vec3(4.0f, 4.0f, 4.0f));
|
||||
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));
|
||||
planet.Draw(shader);
|
||||
|
||||
// 绘制石头
|
||||
for(GLuint i = 0; i < amount; i++)
|
||||
{
|
||||
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(modelMatrices[i]));
|
||||
rock.Draw(shader);
|
||||
}
|
||||
```
|
||||
|
||||
我们先绘制天体模型,要把它平移和缩放一点以适应场景,接着,我们绘制amount数量的小行星,它们按照我们所计算的结果进行变换。在我们绘制每个小行星之前,我们还得先在着色器中设置相应的模型变换矩阵。
|
||||
|
||||
结果是一个太空样子的场景,我们可以看到有一个自然的小行星带:
|
||||
|
||||
|
||||
|
||||
这个场景包含1001次渲染函数调用,每帧渲染1000个小行星模型。你可以在这里找到[场景的源码](http://learnopengl.com/code_viewer.php?code=advanced/instancing_asteroids_normal),以及[顶点](http://learnopengl.com/code_viewer.php?code=advanced/instancing&type=vertex)和[片段](http://learnopengl.com/code_viewer.php?code=advanced/instancing&type=fragment)着色器。
|
||||
|
||||
当我们开始增加数量的时候,很快就会注意到帧数的下降,而且下降的厉害。当我们设置为2000的时候,场景慢得已经难以移动了。
|
||||
|
||||
我们再次使用实例渲染来渲染同样的场景。我们先得对顶点着色器进行一点修改:
|
||||
|
||||
```c++
|
||||
#version 330 core
|
||||
layout (location = 0) in vec3 position;
|
||||
layout (location = 2) in vec2 texCoords;
|
||||
layout (location = 3) in mat4 instanceMatrix;
|
||||
|
||||
out vec2 TexCoords;
|
||||
|
||||
uniform mat4 projection;
|
||||
uniform mat4 view;
|
||||
|
||||
void main()
|
||||
{
|
||||
gl_Position = projection * view * instanceMatrix * vec4(position, 1.0f);
|
||||
TexCoords = texCoords;
|
||||
}
|
||||
```
|
||||
|
||||
我们不再使用模型uniform变量,取而代之的是把一个mat4的顶点属性,送一我们可以将变换矩阵储存为一个实例数组(instanced array)。然而,当我们声明一个数据类型为顶点属性的时候,它比一个vec4更大,是有些不同的。顶点属性被允许的最大数据量和vec4相等。因为一个mat4大致和4个vec4相等,我们为特定的矩阵必须保留4个顶点属性。因为我们将它的位置赋值为3个列的矩阵,顶点属性的位置就会是3、4、5和6。
|
||||
|
||||
然后我们必须为这4个顶点属性设置属性指针,并将其配置为实例数组:
|
||||
|
||||
```c++
|
||||
for(GLuint i = 0; i < rock.meshes.size(); i++)
|
||||
{
|
||||
GLuint VAO = rock.meshes[i].VAO;
|
||||
// Vertex Buffer Object
|
||||
GLuint buffer;
|
||||
glBindVertexArray(VAO);
|
||||
glGenBuffers(1, &buffer);
|
||||
glBindBuffer(GL_ARRAY_BUFFER, buffer);
|
||||
glBufferData(GL_ARRAY_BUFFER, amount * sizeof(glm::mat4), &modelMatrices[0], GL_STATIC_DRAW);
|
||||
// Vertex Attributes
|
||||
GLsizei vec4Size = sizeof(glm::vec4);
|
||||
glEnableVertexAttribArray(3);
|
||||
glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (GLvoid*)0);
|
||||
glEnableVertexAttribArray(4);
|
||||
glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (GLvoid*)(vec4Size));
|
||||
glEnableVertexAttribArray(5);
|
||||
glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (GLvoid*)(2 * vec4Size));
|
||||
glEnableVertexAttribArray(6);
|
||||
glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (GLvoid*)(3 * vec4Size));
|
||||
|
||||
glVertexAttribDivisor(3, 1);
|
||||
glVertexAttribDivisor(4, 1);
|
||||
glVertexAttribDivisor(5, 1);
|
||||
glVertexAttribDivisor(6, 1);
|
||||
|
||||
glBindVertexArray(0);
|
||||
}
|
||||
```
|
||||
|
||||
要注意的是我们将Mesh的VAO变量声明为一个public(公有)变量,而不是一个private(私有)变量,所以我们可以获取它的顶点数组对象。这不是最干净的方案,但这能较好的适应本教程。若没有这点hack,代码就干净了。我们声明了OpenGL该如何为每个矩阵的顶点属性的缓冲进行解释,每个顶点属性都是一个实例数组。
|
||||
|
||||
下一步我们再次获得网格的VAO,这次使用`glDrawElementsInstanced`进行绘制:
|
||||
|
||||
```c++
|
||||
// Draw meteorites
|
||||
instanceShader.Use();
|
||||
for(GLuint i = 0; i < rock.meshes.size(); i++)
|
||||
{
|
||||
glBindVertexArray(rock.meshes[i].VAO);
|
||||
glDrawElementsInstanced(
|
||||
GL_TRIANGLES, rock.meshes[i].vertices.size(), GL_UNSIGNED_INT, 0, amount
|
||||
);
|
||||
glBindVertexArray(0);
|
||||
}
|
||||
```
|
||||
|
||||
这里我们绘制和前面的例子里一样数量(amount)的小行星,只不过是使用的实例渲染。结果是相似的,但你会看在开始增加数量以后效果的不同。不实例渲染,我们可以流畅渲染1000到1500个小行星。而使用了实例渲染,我们可以设置为100000,每个模型由576个顶点,这几乎有5千7百万个顶点,而且帧率没有丝毫下降!
|
||||
|
||||
|
||||
|
||||
上图渲染了十万小行星,半径为150.0f,偏移等于25.0f。你可以在这里找到这个演示实例渲染的[源码](http://learnopengl.com/code_viewer.php?code=advanced/instancing_asteroids_instanced)。
|
||||
|
||||
!!! Important
|
||||
|
||||
有些机器渲染十万可能会有点吃力,所以尝试修改这个数量知道你能获得可以接受的帧率。
|
||||
|
||||
就像你所看到的,在合适的条件下,实例渲染对于你的显卡来说和普通渲染有很大不同。处于这个理由,实例渲染通常用来渲染草、草丛、粒子以及像这样的场景,基本上来讲只要场景中有很多重复物体,使用实例渲染都会获得好处。
|
||||
206
04 Advanced OpenGL/11 Anti Aliasing.md
Normal file
206
04 Advanced OpenGL/11 Anti Aliasing.md
Normal file
@@ -0,0 +1,206 @@
|
||||
## 抗锯齿(Anti Aliasing)
|
||||
|
||||
原文 | [Anti Aliasing](http://learnopengl.com/#!Advanced-OpenGL/Anti-Aliasing)
|
||||
---|---
|
||||
作者 | JoeyDeVries
|
||||
翻译 | [Django](http://bullteacher.com/)
|
||||
校对 | [Geequlim](http://geequlim.com)
|
||||
|
||||
在你的渲染大冒险中,你可能会遇到模型边缘有锯齿的问题。锯齿边出现的原因是由顶点数据像素化之后成为片段的方式所引起的。下面是一个简单的立方体,它体现了锯齿边的效果:
|
||||
|
||||
|
||||
|
||||
也许不是立即可见的,如果你更近的看看立方体的边,你就会发现锯齿了。如果我们放大就会看到下面的情境:
|
||||
|
||||

|
||||
|
||||
这当然不是我们在最终版本的应用里想要的效果。这个效果,很明显能看到边是由像素所构成的,这种现象叫做走样(aliasing)。有很多技术能够减少走样,产生更平滑的边缘,这些技术叫做反走样技术(anti-aliasing,也被称为抗锯齿技术)。
|
||||
|
||||
首先,我们有一个叫做超级采样抗锯齿技术(super sample anti-aliasing SSAA),它暂时使用一个更高的解析度(以超级采样方式)来渲染场景,当视频输出在帧缓冲中被更新时,解析度便降回原来的普通解析度。这个额外的解析度被用来防止锯齿边。虽然它确实为我们提供了一种解决走样问题的方案,但却由于必须绘制比平时更多的片段而降低了性能。所以这个技术只流行了一段时间。
|
||||
|
||||
这个技术的基础上诞生了更为现代的技术,叫做多采样抗锯齿(multisample anti-aliasing)或叫MSAA,虽然它借用了SSAA的理念,但却以更加高效的方式实现了它。这节教程我们会展开讨论这个MSAA技术,它是OpenGL内建的。
|
||||
|
||||
## 多重采样(Multisampling)
|
||||
|
||||
为了理解什么是多重采样,以及它是如何解决锯齿问题的,我们先要更深入了解一个OpenGL光栅化的工作方式。
|
||||
|
||||
光栅化是你的最终的经处理的顶点和片段着色器之间的所有算法和处理的集合。光栅化将属于一个基本图形的所有顶点转化为一系列片段。顶点坐标理论上可以含有任何坐标,但片段却不是这样,这是因为它们与你的窗口的解析度有关。几乎永远都不会有顶点坐标和片段的一对一映射,所以光栅化必须以某种方式决定每个特定顶点最终结束于哪个片段/屏幕坐标上。
|
||||
|
||||
|
||||
|
||||
这里我们看到一个屏幕像素网格,每个像素中心包含一个采样点(sample point),它被用来决定一个像素是否被三角形所覆盖。红色的采样点如果被三角形覆盖,那么就会为这个被覆盖像(屏幕)素生成一个片段。即使三角形覆盖了部分屏幕像素,但是采样点没被覆盖,这个像素仍然不会受到任何片段着色器影响到。
|
||||
|
||||
你可能已经明白走样的原因来自何处了。三角形渲染后的版本最后在你的屏幕上是这样的:
|
||||
|
||||

|
||||
|
||||
由于屏幕像素总量的限制,有些边上的像素能被渲染出来,而有些则不会。结果就是我们渲染出的基本图形的非光滑边缘产生了上图的锯齿边。
|
||||
|
||||
多采样所做的正是不再使用单一采样点来决定三角形的覆盖范围,而是采用多个采样点。我们不再使用每个像素中心的采样点,取而代之的是4个子样本(subsample),用它们来决定像素的覆盖率。这意味着颜色缓冲的大小也由于每个像素的子样本的增加而增加了。
|
||||
|
||||
|
||||
|
||||
左侧的图显示了我们普通决定一个三角形的覆盖范围的方式。这个像素并不会运行一个片段着色器(这就仍保持空白),因为它的采样点没有被三角形所覆盖。右边的图展示了多采样的版本,每个像素包含4个采样点。这里我们可以看到只有2个采样点被三角形覆盖。
|
||||
|
||||
!!! Important
|
||||
|
||||
采样点的数量是任意的,更多的采样点能带来更精确的覆盖率。
|
||||
|
||||
多采样开始变得有趣了。2个子样本被三角覆盖,下一步是决定这个像素的颜色。我们原来猜测,我们会为每个被覆盖的子样本运行片段着色器,然后对每个像素的子样本的颜色进行平均化。例子的那种情况,我们在插值的顶点数据的每个子样本上运行片段着色器,然后将这些采样点的最终颜色储存起来。幸好,它不是这么运作的,因为这等于说我们必须运行更多的片段着色器,会明显降低性能。
|
||||
|
||||
MSAA的真正工作方式是,每个像素只运行一次片段着色器,无论多少子样本被三角形所覆盖。片段着色器运行着插值到像素中心的顶点数据,最后颜色被储存近每个被覆盖的子样本中,每个像素的所有颜色接着将平均化,每个像素最终有了一个唯一颜色。在前面的图片中4个样本中只有2个被覆盖,像素的颜色将以三角形的颜色进行平均化,颜色同时也被储存到其他2个采样点,最后生成的是一种浅蓝色。
|
||||
|
||||
结果是,颜色缓冲中所有基本图形的边都生成了更加平滑的样式。让我们看看当再次决定前面的三角形覆盖范围时多样本看起来是这样的:
|
||||
|
||||
|
||||
|
||||
这里每个像素包含着4个子样本(不相关的已被隐藏)蓝色的子样本是被三角形覆盖了的,灰色的没有被覆盖。三角形内部区域中的所有像素都会运行一次片段着色器,它输出的颜色被储存到所有4个子样本中。三角形的边缘并不是所有的子样本都会被覆盖,所以片段着色器的结果仅储存在部分子样本中。根据被覆盖子样本的数量,最终的像素颜色由三角形颜色和其他子样本所储存的颜色所决定。
|
||||
|
||||
大致上来说,如果更多的采样点被覆盖,那么像素的颜色就会更接近于三角形。如果我们用早期使用的三角形的颜色填充像素,我们会获得这样的结果:
|
||||
|
||||
|
||||
|
||||
对于每个像素来说,被三角形覆盖的子样本越少,像素受到三角形的颜色的影响也越少。现在三角形的硬边被比实际颜色浅一些的颜色所包围,因此观察者从远处看上去就比较平滑了。
|
||||
|
||||
不仅颜色值被多采样影响,深度和模板测试也同样使用了多采样点。比如深度测试,顶点的深度值在运行深度测试前被插值到每个子样本中,对于模板测试,我们为每个子样本储存模板值,而不是每个像素。这意味着深度和模板缓冲的大小随着像素子样本的增加也增加了。
|
||||
|
||||
到目前为止我们所讨论的不过是多采样发走样工作的方式。光栅化背后实际的逻辑要比我们讨论的复杂,但你现在可以理解多采样抗锯齿背后的概念和逻辑了。
|
||||
|
||||
## OpenGL中的MSAA
|
||||
|
||||
如果我们打算在OpenGL中使用MSAA,那么我们必须使用一个可以为每个像素储存一个以上的颜色值的颜色缓冲(因为多采样需要我们为每个采样点储存一个颜色)。我们这就需要一个新的缓冲类型,它可以储存要求数量的多重采样样本,它叫做**多样本缓冲(multisample buffer)**。
|
||||
|
||||
多数窗口系统可以为我们提供一个多样本缓冲,以代替默认的颜色缓冲。GLFW同样给了我们这个功能,我们所要作的就是提示GLFW,我们希望使用一个带有N个样本的多样本缓冲,而不是普通的颜色缓冲,这要在创建窗口前调用`glfwWindowHint`来完成:
|
||||
|
||||
```c++
|
||||
glfwWindowHint(GLFW_SAMPLES, 4);
|
||||
```
|
||||
|
||||
当我们现在调用`glfwCreateWindow`,用于渲染的窗口就被创建了,这次每个屏幕坐标使用一个包含4个子样本的颜色缓冲。这意味着所有缓冲的大小都增长4倍。
|
||||
|
||||
现在我们请求GLFW提供了多样本缓冲,我们还要调用`glEnable`来开启多采样,参数是 `GL_MULTISAMPLE`。大多数OpenGL驱动,多采样默认是开启的,所以这个调用有点多余,但通常记得开启它是个好主意。这样所有OpenGL实现的多采样都开启了。
|
||||
|
||||
```c++
|
||||
glEnable(GL_MULTISAMPLE);
|
||||
```
|
||||
|
||||
当默认帧缓冲有了多采样缓冲附件的时候,我们所要做的全部就是调用 `glEnable`开启多采样。因为实际的多采样算法在OpenGL驱动光栅化里已经实现了,所以我们无需再做什么了。如果我们现在来渲染教程开头的那个绿色立方体,我们会看到边缘变得平滑了:
|
||||
|
||||
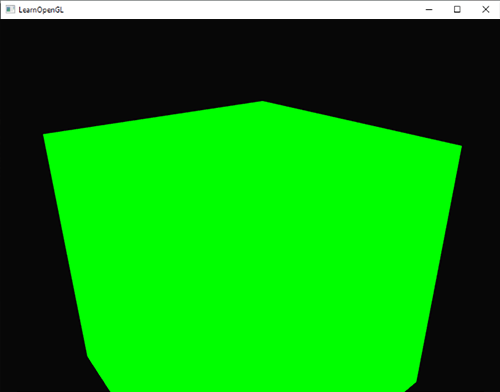
|
||||
|
||||
这个箱子看起来平滑多了,在场景中绘制任何物体都可以利用这个技术。可以[从这里找到](http://learnopengl.com/code_viewer.php?code=advanced/anti_aliasing_multisampling)这个简单的例子。
|
||||
|
||||
## 离屏MSAA
|
||||
|
||||
因为GLFW负责创建多采样缓冲,开启MSAA非常简单。如果我们打算使用我们自己的帧缓冲,来进行离屏渲染,那么我们就必须自己生成多采样缓冲了;现在我们需要自己负责创建多采样缓冲。
|
||||
|
||||
有两种方式可以创建多采样缓冲,并使其成为帧缓冲的附件:纹理附件和渲染缓冲附件,和[帧缓冲教程](http://learnopengl-cn.readthedocs.org/zh/latest/04%20Advanced%20OpenGL/05%20Framebuffers/)里讨论过的普通的附件很相似。
|
||||
|
||||
### 多采样纹理附件
|
||||
|
||||
为了创建一个支持储存多采样点的纹理,我们使用 `glTexImage2DMultisample`来替代 `glTexImage2D`,它的纹理目标是**`GL_TEXTURE_2D_MULTISAMPLE`**:
|
||||
|
||||
```c++
|
||||
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, tex);
|
||||
glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, samples, GL_RGB, width, height, GL_TRUE);
|
||||
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, 0);
|
||||
```
|
||||
|
||||
第二个参数现在设置了我们打算让纹理拥有的样本数。如果最后一个参数等于 **`GL_TRUE`**,图像上的每一个纹理像素(texel)将会使用相同的样本位置,以及同样的子样本数量。
|
||||
|
||||
为将多采样纹理附加到帧缓冲上,我们使用`glFramebufferTexture2D`,不过这次纹理类型是**`GL_TEXTURE_2D_MULTISAMPLE`**:
|
||||
|
||||
```c++
|
||||
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D_MULTISAMPLE, tex, 0);
|
||||
```
|
||||
|
||||
当前绑定的帧缓冲现在有了一个纹理图像形式的多采样颜色缓冲。
|
||||
|
||||
### 多采样渲染缓冲对象(Multisampled renderbuffer objects)
|
||||
|
||||
和纹理一样,创建一个多采样渲染缓冲对象不难。而且还很简单,因为我们所要做的全部就是当我们指定渲染缓冲的内存的时候将`glRenderbuffeStorage`改为`glRenderbufferStorageMuiltisample`:
|
||||
|
||||
```c++
|
||||
glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, width, height);
|
||||
```
|
||||
|
||||
有一样东西在这里有变化,就是缓冲目标后面那个额外的参数,我们将其设置为样本数量,当前的例子中应该是4.
|
||||
|
||||
### 渲染到多采样帧缓冲
|
||||
|
||||
渲染到多采样帧缓冲对象是自动的。当我们绘制任何东西时,帧缓冲对象就绑定了,光栅化会对负责所有多采样操作。我们接着得到了一个多采样颜色缓冲,以及深度和模板缓冲。因为多采样缓冲有点特别,我们不能为其他操作直接使用它们的缓冲图像,比如在着色器中进行采样。
|
||||
|
||||
一个多采样图像包含了比普通图像更多的信息,所以我们需要做的是压缩或还原图像。还原一个多采样帧缓冲,通常用`glBlitFramebuffer`来完成,它从一个帧缓冲中复制一个区域粘贴另一个里面,同时也将任何多采样缓冲还原。
|
||||
|
||||
`glBlitFramebuffer`把一个4屏幕坐标源区域传递到一个也是4空间坐标的目标区域。你可能还记得帧缓冲教程中,如果我们绑定到`GL_FRAMEBUFFER`,我们实际上就同时绑定到了读和写的帧缓冲目标。我们还可以通过`GL_READ_FRAMEBUFFER`和`GL_DRAW_FRAMEBUFFER`绑定到各自的目标上。`glBlitFramebuffer`函数从这两个目标读取,并决定哪一个是源哪一个是目标帧缓冲。接着我们就可以通过把图像位块传送(Blitting)到默认帧缓冲里,将多采样帧缓冲输出传递到实际的屏幕了:
|
||||
|
||||
```c++
|
||||
glBindFramebuffer(GL_READ_FRAMEBUFFER, multisampledFBO);
|
||||
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
|
||||
glBlitFramebuffer(0, 0, width, height, 0, 0, width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);
|
||||
```
|
||||
|
||||
如果我们渲染应用,我们将得到和没用帧缓冲一样的结果:一个绿色立方体,它使用MSAA显示出来,但边缘锯齿明显少了:
|
||||
|
||||

|
||||
|
||||
你可以[在这里找到源代码](http://learnopengl.com/code_viewer.php?code=advanced/anti_aliasing_framebuffers)。
|
||||
|
||||
但是如果我们打算使用一个多采样帧缓冲的纹理结果来做这件事,就像后处理一样会怎样?我们不能在片段着色器中直接使用多采样纹理。我们可以做的事情是把多缓冲位块传送(Blit)到另一个带有非多采样纹理附件的FBO中。之后我们使用这个普通的颜色附件纹理进行后处理,通过多采样来对一个图像渲染进行后处理效率很高。这意味着我们必须生成一个新的FBO,它仅作为一个将多采样缓冲还原为一个我们可以在片段着色器中使用的普通2D纹理中介。伪代码是这样的:
|
||||
|
||||
```c++
|
||||
GLuint msFBO = CreateFBOWithMultiSampledAttachments();
|
||||
// Then create another FBO with a normal texture color attachment
|
||||
...
|
||||
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, screenTexture, 0);
|
||||
...
|
||||
while(!glfwWindowShouldClose(window))
|
||||
{
|
||||
...
|
||||
|
||||
glBindFramebuffer(msFBO);
|
||||
ClearFrameBuffer();
|
||||
DrawScene();
|
||||
// Now resolve multisampled buffer(s) into intermediate FBO
|
||||
glBindFramebuffer(GL_READ_FRAMEBUFFER, msFBO);
|
||||
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, intermediateFBO);
|
||||
glBlitFramebuffer(0, 0, width, height, 0, 0, width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);
|
||||
// Now scene is stored as 2D texture image, so use that image for post-processing
|
||||
glBindFramebuffer(GL_FRAMEBUFFER, 0);
|
||||
ClearFramebuffer();
|
||||
glBindTexture(GL_TEXTURE_2D, screenTexture);
|
||||
DrawPostProcessingQuad();
|
||||
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
如果我们实现帧缓冲教程中讲的后处理代码,我们就能创造出没有锯齿边的所有效果很酷的后处理特效。使用模糊kernel过滤器,看起来会像这样:
|
||||
|
||||
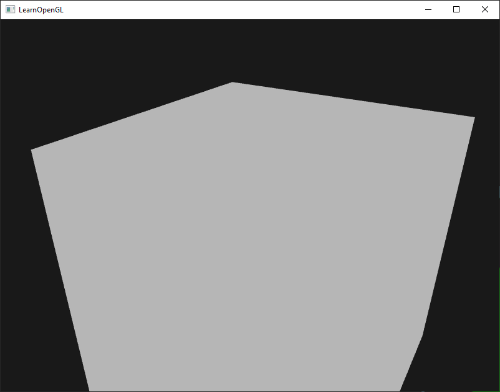
|
||||
|
||||
你可以[在这里找到所有MSAA版本的后处理源码](http://learnopengl.com/code_viewer.php?code=advanced/anti_aliasing_post_processing)。
|
||||
|
||||
!!! Important
|
||||
|
||||
因为屏幕纹理重新变回了只有一个采样点的普通纹理,有些后处理过滤器,比如边检测(edge-detection)将会再次导致锯齿边问题。为了修正此问题,之后你应该对纹理进行模糊处理,或者创建你自己的抗锯齿算法。
|
||||
|
||||
当我们希望将多采样和离屏渲染结合起来时,我们需要自己负责一些细节。所有细节都是值得付出这些额外努力的,因为多采样可以明显提升场景视频输出的质量。要注意,开启多采样会明显降低性能,样本越多越明显。本文写作时,MSAA4样本很常用。
|
||||
|
||||
## 自定义抗锯齿算法
|
||||
|
||||
可以直接把一个多采样纹理图像传递到着色器中,以取代必须先还原的方式。GLSL给我们一个选项来为每个子样本进行纹理图像采样,所以我们可以创建自己的抗锯齿算法,在比较大的图形应用中,通常这么做。
|
||||
|
||||
为获取每个子样本的颜色值,你必须将纹理uniform采样器定义为sampler2DMS,而不是使用sampler2D:
|
||||
|
||||
```c++
|
||||
uniform sampler2DMS screenTextureMS;
|
||||
```
|
||||
|
||||
使用texelFetch函数,就可以获取每个样本的颜色值了:
|
||||
|
||||
```c++
|
||||
vec4 colorSample = texelFetch(screenTextureMS, TexCoords, 3); // 4th subsample
|
||||
```
|
||||
|
||||
我们不会深究自定义抗锯齿技术的创建细节,但是会给你自己去实现它提供一些提示。
|
||||
Reference in New Issue
Block a user